# 효과적인 프로그램 (Effective Programs)
- Speaker: Rich Hickey
- Conference: Clojure/Conj 2017 (opens new window) - Oct 2017
- Video: https://www.youtube.com/watch?v=2V1FtfBDsLU (opens new window)
# Effective Programs

여러분께 감사 인사를 전할 때마다 매번 녹음기가 고장난 것 같은 기분이 듭니다. 그래서 저는 "제 아들이 오늘 결혼합니다."라고 말하면서 다른 방식으로 시작하고 싶습니다.
[청중 박수]
"다른 주에서."
[청중 웃음]
그래서 이 강연이 끝나면 바로 비행기를 타고 가서 내일 아침에 돌아올 테니 저는 사라지지 않았습니다. 후속 강연과 다른 모든 것이 기대되지만 잠시 자리를 비우게 될 것입니다.
그럼 이제 중복이 되겠습니다. 와주신 모든 분들께 감사드립니다. 10년 전, 클로저가 출시되었는데요.
[청중 박수]
상상도 못했죠. 아내 스테파니에게 "100명이 이걸 사용한다면 엄청나게 터무니없는 일이 될 것"이라고 말했는데, 실제로는 그렇게 되지 않았죠. 그리고 실제로 일어난 일은 흥미롭지만 완전히 이해되지 않는다고 생각합니다.
하지만 오늘은 클로저를 개발하게 된 동기에 대해 잠시 되돌아보고 싶었습니다. 프로그래밍 언어를 개발할 때 모든 이야기를 다 할 수 있는 것과는 다릅니다. 첫 번째는 좋은 마케팅이 아니기 때문이고, 두 번째는 솔직히 말해서 여러분은 아마 모르기 때문이라고 생각합니다. 무슨 일이 일어났는지, 왜 그랬는지, 무슨 생각을 하고 있었는지 이해하는 데는 시간이 걸리므로, 제가 모든 것을 통합한 거창한 계획을 세웠다고 주장하지는 않겠습니다. 확실히 커뮤니티의 사람들과 많은 상호작용이 필요했습니다.
하지만 "클로저는 독단적이다"라는 말을 많이 듣습니다. 두 가지 측면을 생각해 보면 흥미롭다고 생각합니다. 하나는 어떤 면에서 그렇고, 언어가 독단적이라는 것은 무엇을 의미하느냐는 것입니다. 클로저의 경우, 사람들이 클로저를 사용하면서 "와, 이건 어디를 가든 특정 방식으로 무언가를 하라고 강요하는구나"라고 생각하게 됩니다.
그래서 저는 강력하게 지원되는 몇 가지 관용구만 있고 그에 대한 지원은 많지 않다고 생각합니다. 따라서 함께 제공되는 자료를 사용하면 여러분의 노력을 뒷받침하는 전체 스토리가 있습니다. 그리고 여러분이 그것에 맞서 싸우고 싶다면, 우리는 너무 많은 일을 하지 않습니다.
[알렉스가 어떤 안경이 옳은지 물어봤는데 "둘 다"가 정답입니다.]
하지만 디자인은 선택의 문제입니다.
I feel like a broken record every time I start these talks by thanking everybody. So I want to start this way in a different way by saying, "My son is getting married today."
[Audience applause]
"In another state."
[Audience laughter]
So right after I give this talk, I'm gonna hop on a plane, go do that, I'll be back tomorrow morning, so I haven't disappeared. I'm looking forward to the follow-up talks and everything else, but I will be missing in action briefly.
So now, to be redundant. Thanks everybody for coming. Ten years ago, Clojure was released, and there's no possible way
[Audience applause]
I could have imagined this. You know I told my wife Steph, I said, "if 100 people use this, that would be ridiculously outrageous", and that's not what happened. And what did happen is interesting, I don't think it's fully understood.
But I wanted today to talk about a look back a little bit about the motivations behind Clojure. It's not like when you come out with a programming language you can tell that whole story. I think one because it's not good marketing, and two because if you really wanna be honest, you probably don't know. It takes time to understand what happened, and why and what you really were thinking, and I won't pretend I had a grand plan that incorporated everything that ended up becoming Clojure. It certainly involved a lot of interaction with people in the community.
But, there is this, "Clojure is opinionated", this, we hear this. And I think it's interesting to think about two aspects of that. One is, in which ways is it, and what does it mean for a language to be opinionated. I think in Clojure's case, people come to it, and they're like "wow, this is forcing me, everywhere I turn to do something a certain way".
So, and I think the nice way to say that is there's only a few strongly supported idioms, and a lot of support for them. So if you use the stuff that comes with it, there's a whole story that supports your efforts. And if you want to fight against that, we don't do too much.
[Alex was asking me which glasses were the right ones and "neither" is the answer.]
But design is about making choices.

특히 클로저에는 많은 선택지가 있는데, 이 강연에서는 무엇을 제외할 것인지에 대한 큰 선택이 있으며, 이 강연의 일부는 제외된 것에 대해 이야기할 것입니다.
독단적이라는 것의 다른 측면은 "어떻게 독단적일 수 있는가"입니다. 제 말은 제가 고집이 센 게 아니라는 거죠.
[청중 웃음]
물론 저는 고집이 세고 경험에서 비롯된 것이죠. 제가 시작했을 때
And now there's a bunch of choices in Clojure, in particular, there's a big choice about what to leave out, and part of this talk will be talking about what was left out.
The other side of being opinionated is "how do you get opinionated". I mean it's not like I'm opinionated.
[Audience laughter]
Of course I'm opinionated, and that comes from experience. When I started
# Application Development

2005년에 클로저를 시작했을 때 저는 이미 18년 동안 프로그래밍을 해왔습니다. 그래서 그만뒀죠. 다 끝났어요. 지겨웠죠. 하지만 당시 전문 프로그래머들이 사용하는 언어로 정말 흥미로운 작업을 해본 적이 있었죠.
주로 C++로 스케줄링 시스템을 개발했는데, 이는 방송사를 위한 스케줄링 시스템으로 라디오 방송국에서는 스케줄링 시스템을 사용해 어떤 음악을 재생할지 결정합니다. 그리고 그 작동 방식은 매우 정교합니다. "하루 종일 같은 노래를 반복하고 싶지 않다"고 생각하죠. 실제로 오전에는 한 시간 동안 라디오를 듣고 오후에는 다른 한 시간 동안 라디오를 듣는 사람들에 대해 생각해야 합니다. 그리고 운전 시간대마다 일종의 대체 시간대를 만들어야 합니다. 그런 식이죠. 따라서 다차원 스케줄링이 있고 진화적 프로그램 최적화를 사용하여 스케줄 최적화를 수행했습니다.
방송 자동화는 오디오를 재생하는 것인데, 이 작업을 할 당시에는 컴퓨터에서 오디오를 재생하는 것이 매우 어려웠습니다. DSP 작업을 위해서는 전용 카드가 필요했습니다. 저는 오디오 핑거프린팅 작업을 했기 때문에 벽장에 앉아서 라디오를 듣고 들은 내용을 기록하는 시스템을 만들었습니다. 그리고 이것은 방송국의 재생 목록을 추적하는 데 사용되었고 결국에는 광고가 어디에 있는지 추적하는 데 사용되었습니다. 오디오를 효과적으로 핑거프린팅하고 오디오를 스크러빙하는 방법을 알아내어 과거와 현재를 비교하는 작업도 했습니다.
저는 수익률 관리 시스템을 연구했습니다. "수익률 관리"가 뭔지 다들 아시나요? 아마 모르시겠죠. 그렇다면 호텔, 항공사, 라디오 방송국의 공통점은 무엇일까요? 시간이 지나면 재고가 사라진다는 것이죠? "아, 빈 방이 있고, 스케줄에 자리가 있고, 비행기 좌석이 있네"라고 생각했는데 시간이 지나고 아무도 사지 않아서 지금은 없는 것이죠. 따라서 수익률 관리는 재고가 사라질 때 재고의 가치를 최적화하는 방법을 알아내는 과학이자 실천입니다. 이는 과거와 과거의 판매량을 살펴보는 것으로, 단순하지 않습니다. 예를 들어, 인벤토리를 모두 판매하는 것이 목표가 아니라 인벤토리에서 얻는 수익을 극대화하는 것이 목표이므로 대부분의 경우 인벤토리를 모두 판매하지 않는 것이 좋습니다.
그 당시에는 C++로 작성된 것이 아니었고, 제가 커먼 리스프를 발견한 지 약 8년 후인 15년 전이었습니다. 그래서 저는 모든 수율 관리 알고리즘을 다시 SQL 저장 프로시저로 작성하고 이 데이터베이스를 제공하는 커먼 리스프 프로그램을 작성했습니다.
결국 저는 다시 스케줄링으로 돌아와서 새로운 종류의 스케줄링 시스템을 커먼 리스프어로 다시 작성했는데, 이 시스템 역시 프로덕션에서 실행하기를 원하지 않았습니다. 그런 다음 C++로 다시 작성했습니다. 이 시점에서 저는 C++ 전문 사용자였고 C++를 정말 사랑했습니다.
[청중 웃음]
만족감을 전혀 느끼지 못했죠.
[청중 웃음]
하지만 나중에 보겠지만 저는 C++의 퍼즐을 좋아합니다. 그래서 C++로 다시 작성해야 했는데 처음에 작성할 때보다 4배나 더 오래 걸렸고, 코드도 5배나 많았지만 더 빠르지도 않았어요. 그때 제가 잘못하고 있다는 것을 깨달았습니다.
doing Clojure in 2005, I had already been programming for 18 years. So I'd had it. I was done. I was tired of it. But I had done some really interesting things with the languages that professional programmers used at the time.
So primarily I was working on scheduling systems in C++, these are scheduling systems for broadcasters, so radio stations use scheduling systems to determine what music they play. And it's quite sophisticated the way that works. You know, you think about "well over the course of the day you don't want to repeat the same song". You actually have to think about the people who, you know, listen to the radio for one hour in the morning and this other hour in the afternoon. And you create sort of alternate time dimension for every drive time hour. Things like that. So there's multi-dimensional scheduling and we used evolutionary program optimization to do schedule optimization.
Broadcast automation is about playing audio and at the time we were doing this, playing audio on computers was a hard thing. It required dedicated cards to DSP work. I did work on audio fingerprinting, so we made systems that sat in closets and listened to the radio and wrote down what they heard. And this was both used to track station's playlists and eventually to track advertising which was where the money was for that. Which involved figuring out how to effectively fingerprint audio and scrub audio, sort of compare novelty to the past.
I worked on yield management systems. Does everybody know what "yield management" is"? Probably not. So what do hotels, airlines, and radio stations have in common? Their inventory disappears as time passes, right? "Oh, I have a free room, I've got a slot in my schedule, I've got a seat on this airplane", and then time passes and nobody bought it, and now you don't. So yield management is the science and practice of trying to figure out how to optimize the value of your inventory as it disappears out from under you. And that's about looking at the past and past sales and it's not simplistic. So for instance, it's not an objective to sell all of your inventory, the objective is to maximize the revenue you get from it, which means not selling all of it in most cases.
That was not written in C++, that was around the time I discovered Common Lisp, which was about 8 years into that 15 years. And there was no way the consumer of this would use Common Lisp, so I wrote a Common Lisp program that wrote all the yield management algorithms again out as SQL stored procedures and gave them this database, which was a program.
Eventually I got back to scheduling and again wrote a new kind of scheduling system in Common Lisp, which again they did not want to run in production. And then I rewrote it in C++. Now at this point I was an expert C++ user and really loved C++, for some value of love
[Audience laughter]
that involves no satisfaction at all.
[Audience laughter]
But as we'll see later I love the puzzle of C++. So I had to rewrite it in C++ and it took, you know, four times as long to rewrite it as it took to write it in the first place, it yielded five times as much code and it was no faster. And that's when I knew I was doing it wrong.

제 친구 Eric이 선거 예측 시스템을 포함하는 새로운 버전의 미국 출구조사 시스템을 작성하는 것을 돕기 위해 나갔습니다. 저희는 일종의 자의적 함수형 스타일인 C#으로 이 작업을 수행했습니다.
그러다가 2005년경에 클로저와 기계 청취 프로젝트를 동시에 시작했어요. 어느 쪽이 어디로 갈지 모르는 상황에서 2년 동안 안식년을 주어 이 두 가지 일을 병행했습니다. 상업적 목표도, 성공 지표도 없이 제가 옳다고 생각하는 일을 자유롭게 하면서 2년 동안 제 자신을 만족시키려고 노력했고, 일종의 휴식을 취한 셈이죠.
하지만 그 기간 동안 한 작품만 완성할 수 있다는 사실을 깨달았습니다. 그리고 저는 클로저를 끝낼 방법을 알고 있었고, 기계 청취는 연구 주제였습니다. 2년이 걸릴지 5년이 걸릴지 알 수 없었죠. 그래서 클로저는 자바로 작성되었고 결국에는 라이브러리도 클로저로 작성되었습니다.
그리고 기계 청취 작업에는 인공 달팽이관을 만드는 작업이 포함되었고, 저는 커먼 리스프와 매서티카, C++를 조합하여 이를 수행했습니다. 그리고 최근 몇 년 동안 이 작업을 꾸준히 해오면서 Clojure로 할 수 있게 되었는데, 이것이 가장 흥미로운 일이었습니다. 이전에는 이 세 가지 언어가 모두 필요했지만 이제는 클로저만 있으면 됩니다.
그리고 데이터믹(Datomic)을 만들었는데, 이것도 클로저입니다.
Went out to help my friend Eric write the new version of the National Exit Poll System for the U.S., which also involves an election projection system. We did that in, you know, a sort of self-imposed functional style of C#.
And then, you know, around 2005, I started doing Clojure and this machine listening project at the same time. And I'd given myself a 2-year sabbatical to work on these things not knowing which one would go where. And leaving myself free to do whatever I thought was right so I had zero commercial objectives, zero acceptance metrics, I was trying to please myself for two years, just sort of bought myself a break.
But along the way during that period of time, you know, I realized I'd only have time to finish one. And I knew how to finish Clojure, and you know, machine listening is a research topic. I didn't know if I was two years away or five years away. So Clojure is written in Java and eventually, you know, the libraries written in Clojure.
And the machine listening work involved building an artificial cochlea, and I did that in a combination of Common Lisp and Mathematica and C++. And in recent years as I've dusted it off, I've been able to do it in Clojure, and that's sort of the most exciting thing. I needed these three languages before to do this and now I only need Clojure to do it.
And then I did Datomic, which is also Clojure.
# Databases!

거의 모든 프로젝트가 데이터베이스와 관련이 있었습니다. ISAM 데이터베이스부터 다양한 종류의 데이터베이스, 많은 SQL, 많은 시도가 있었지만 RDF를 통합한 사례는 많지 않았습니다. 데이터베이스는 이러한 종류의 문제를 해결하는 데 필수적인 부분입니다. 이것이 바로 우리가 하는 일입니다.
매일 하는 일에서 데이터베이스를 사용하는 사람이 얼마나 될까요? 그렇지 않은 사람은 얼마나 될까요?
그렇군요.
따라서 이 마지막 단어는 데이터베이스의 약어가 아닙니다. 이 일화를 상기시키기 위한 것입니다.
저는 경량 언어 워크숍에 간 적이 있습니다. MIT에서 열린 하루짜리 워크숍이었죠. 독점적이거나 도메인에 특화된 작은 언어를 개발하는 사람들, 즉 DARPA(?) 같은 곳에서 작은 언어에 대해 이야기하고 작은 언어로 무엇을 할 것인지에 대해 이야기하는 자리였죠. 정말 멋지고 흥미진진했어요. 언어에 관심이 많은 사람들이 한 방에 모였고, 끝나고 피자를 먹었죠.
그래서 혼자 가거나 친구와 함께 갔던 기억이 나요. 저는 그런 커뮤니티의 일원이 아니었고 그냥 들여보내 주었어요. 그런데 나중에 피자를 먹어서 모르는 사람 두 명과 피자를 먹었는데 아직도 그 사람들의 이름을 모르겠어요. 이제 그들을 비방할 테니 모르는 게 다행이죠.
[청중 웃음]
둘 다 컴퓨터 언어 연구자였는데, 데이터베이스에 빠져서 진정한 길을 잃은 동료에 대해 비방하는 이야기를 하고 있었습니다. 한 사람이 다른 사람에게 "데이비드, 마지막으로 데이터베이스를 사용해 본 게 언제야?"라고 비웃듯이 말했더니 그 사람이 "데이터베이스를 사용해 본 적이 없어요"라고 대답했습니다. 이론적으로는 프로그래밍 언어를 설계하지만 프로그래밍을 하면서 데이터베이스를 한 번도 사용해 본 적이 없으니, 마치 피자에 질식한 것 같았습니다. 저는 그게 어떻게 작동하는지 몰랐어요.
하지만 그 경험에서 영감을 얻었습니다.
Almost all of these projects involved a database. All different kinds of databases from, you know, ISAM databases, a lot of SQL, many attempts but not many integrations of RDF. Databases are an essential part of solving these kinds of problems. It's just what we do.
How many people use a database in what they do every day? How many people don't?
Ok.
So this last thing is not an acronym for a database. It's there to remind me to tell this anecdote.
So I used to go to the Light-Weight Languages workshop. It was a one-day workshop held at MIT. Where people working on small languages, you know, either proprietary or just domain-specific, you know, DARPA(?) or whatever would talk about their little languages and what they would do with their little languages. It was very cool and very exciting. Got a bunch of language geeks in the same room, and there was pizza afterwards.
So I remember, I would just go by myself or with my friend. I was not part of the community that did that, they just let me in. But afterwards, they had pizza, so I had sat down with pizza with two people I didn't know, and I still don't know their names. And it's good that I don't, because I'm gonna now disparage them.
[audience laughter]
They were both computer language researchers, and they were talking also disparagingly about their associate who'd somehow had fallen in with databases and lost the true way. And one of them sort of sneeringly ? to the other and said, "aw, David, when was the last time you used a database?", and he was like, "I don't know that I've ever used a database". And like I sort of choked on my pizza, because theoretically they're designing programming languages and yet they're programming and they never use databases. I didn't know how that worked.
But it's part of the inspiration to do

클로저는 데이터베이스를 사용하지 않는 사람이라도 누구나 프로그래밍 언어를 작성할 수 있기 때문입니다.
[청중 웃음]
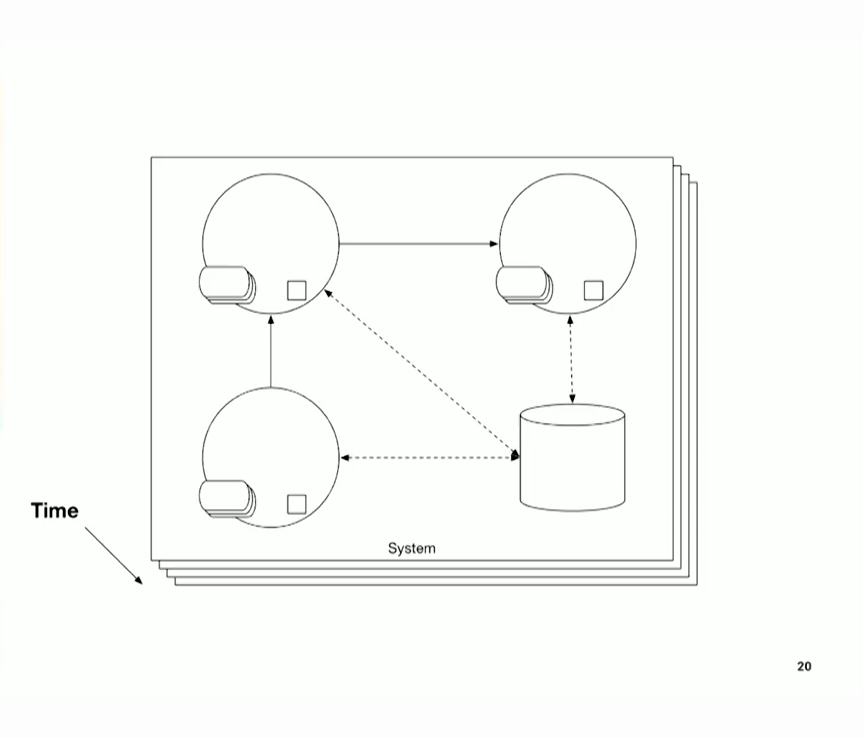
그래서 다양한 종류의 프로그램이 있는데, 제가 이 슬라이드에 담으려고 했던 것 중 하나는 제가 작업하고 있는 프로그램이 어떤 것인지에 대해 이야기하는 것이었습니다. 그래서 생각해낸 단어가 바로 '포지셔닝된' 프로그램입니다. 다시 말해, 세상과 얽혀서 세상 속에 자리 잡고 있는 이런 종류의 프로그램을 구분할 수 있습니다. 여기에는 여러 가지 특징이 있습니다. 첫째는 오랜 시간 동안 실행된다는 점입니다. 이 결과를 계산해서 저기 뱉어내는 것과는 다릅니다. AWS의 람다 함수와도 다릅니다. 이러한 시스템은 지속적으로 실행되며 전 세계와 연결되어 있습니다. 그리고 이러한 시스템 대부분은 연중무휴 24시간 연속적으로 실행됩니다. 30년이나 된 이런 시스템이 교체되지 않았다면 어딘가에서 여전히 24시간 연중무휴로 작동하고 있을 가능성이 높다는 사실은 저에게 매우 끔찍한 일입니다.
따라서 여기서 말하는 장시간이라는 개념은 단발성이 아니라 지속적으로 지속된다는 의미입니다. 거의 항상 정보를 다루기 때문입니다. 어떤 종류의 정보에 대해 이야기했나요? 스케줄링입니다. 스케줄링에서는 과거에 수행한 작업을 살펴봅니다. 리서치 데이터를 살펴봅니다. 청중이 무엇을 좋아하거나 관심이 있는지, 또는 무엇에 지쳐 있는지 파악합니다. 그리고 이러한 지식을 결합하여 일정을 만듭니다.
수익률 관리는 특정 기간과 관련된 과거 판매 및 매출을 살펴보고 이에 대한 사실을 파악하여 가격 책정 정보를 생성합니다.
선거 시스템은 이전 투표 기록을 살펴봅니다. 사람들은 이전에 어떻게 투표했나요? 이는 그들이 다시 투표할 때 어떻게 투표할 것인지에 대한 큰 지표가 됩니다. 물론 그 이면의 알고리즘(?)은 훨씬 더 정교합니다.
하지만 단순화해서 말하자면, 이 모든 시스템은 정보를 소비했고, 그 정보는 그들에게 매우 중요했다고 말할 수 있습니다. 그리고 그들 중 일부는 정보를 생산했습니다. 그들은 자신이 한 일을 기록으로 남겼습니다.
그리고 다음 요점은 이러한 시스템 대부분이 일종의 시간이 오래 걸리는 메모리를 가지고 있다는 것입니다. 데이터베이스는 고정된 시스템 입력이 아닙니다. 시스템이 실행됨에 따라 추가되는 것입니다. 따라서 이러한 시스템은 자신이 수행한 작업을 기억하고 있으며, 자체적으로 사용하거나 다른 프로그램에서 자주 사용합니다.
그리고 실제 불규칙성을 처리합니다. 이것이 제가 생각하는 또 다른 중요한 점입니다. 이 프로그래밍 세계에서 매우 중요하다고 생각합니다. 현실 세계는 생각만큼 우아하지 않거든요.
하루 종일 듣는 사람과 오전과 오후에 운전하면서 듣는 사람으로 나뉘는 선형적인 시간대에 대한 스케줄링 문제에 대해서도 이야기했습니다. 8시간 간격으로 한 세트의 사람들이 있고 한 시간 후에 또 다른 세트의 사람들이 있고 또 다른 세트가 있습니다. 그 모든 시간을 생각해야 합니다. 다차원적 시간이라는 우아한 개념을 떠올리면 "아, 화요일만 빼고 다 괜찮아"라고 생각할 수 있습니다. 왜 그럴까요? 미국에서는 특정 장르의 라디오에 "화요일은 2번"이라는 것이 있습니다. 그렇죠? 그래서 이 스케줄링 시스템을 만들었는데, 이 시스템의 주요 목적은 같은 곡을 연속해서 두 번 재생하지 않거나 마지막에 재생한 곡과 거의 비슷한 시간대에 재생하지 않는 것입니다. 그리고 같은 아티스트를 재생할 때와 가까운 시간에도 같은 아티스트를 재생하지 않으면 누군가가 "엘튼 존만 재생하네, 이 방송국 싫어"라고 말할 것입니다.
하지만 화요일에는 속임수입니다. "화요일에는 두 곡"은 한 곡을 틀 때마다 해당 아티스트의 노래를 두 곡씩 틀겠다는 뜻입니다. 시스템에 있는 모든 귀중하고 우아한 규칙을 위반하는 거죠. 이런 종류의 불규칙성이 없는 실제 시스템은 본 적이 없습니다. 그리고 그 규칙이 중요하지 않은 곳도 있었죠.
Clojure because, I mean, people who don't do databases can write programming languages, anybody can.
[audience laughter]
So, you know, there are different kinds of programs, and one of the things I tried to capture on this slide is to talk about what those kinds of programs were that I was working on. And the word I came up with was "situated" programs. In other words, you can distinguish these kinds of programs that sit in the world in a sort of entangled with the world. They have a bunch of characteristics. One is, they execute for an extended period of time. It's not just like calculate this result and spit it over there. It's not like a lambda function at AWS. These things run on an ongoing basis and they're sort of wired up to the world. And most of these systems run continuously, 24/7. It's quite terrifying to me that now these things which are 30 years old are almost definitely still running 24/7 somewhere, if they haven't been replaced.
So this first notion of extended periods of time means continuously, as opposed to just for a burst. They almost always deal with information. What were the kinds of things that I talked about? Scheduling. In scheduling you look at what you've done in the past. You look at your research data. What does your audience tell you they like or they're interested in, or what they're burnt out on. And you combine that knowledge to make a schedule.
Yield management looks at the past sales and sales related to particular periods of time and facts about that, and produces pricing information.
The election system looks at prior vote records. How did people vote before? That is a big indicator of how they're going to vote again. Of course the algorithms behind (?) that are much more sophisticated.
But in a simplified way, you can say all of these systems consumed information, and it was vital to them. And some of them produced information. They tracked the record what they did.
And that's this next point which is that most of these systems have some sort of time-extensive memory. That database isn't like an input to the system that's, you know, fixed. It's something that gets added to as the system runs. So these systems are remembering what they did and they're doing it both for their own consumption and for consumption by other programs quite often.
And they deal with real-world irregularity. This is the other thing I think that's super-critical, you know, in this situated programming world. It's never as elegant as you think, the real-world.
And I talked about that scheduling problem of, you know, those linear times, somebody who listens all day, and the somebody who just listens while they're driving in the morning and the afternoon. Eight hours apart there's one set of people and, then an hour later there's another set of people, another set. You know, you have to think about all that time. You come up with this elegant notion of multi-dimensional time and you'd be like, "oh, I'm totally good...except on Tuesday". Why? Well, in the U.S. on certain kinds of genres of radio, there's a thing called "two for Tuesday". Right? So you built this scheduling system, and the main purpose of the system is to never play the same song twice in a row, or even pretty near when you played it last. And not even play the same artist near when you played the artist, or else somebody's going to say, "all you do is play Elton John, I hate this station".
But on Tuesday, it's a gimmick. "Two for Tuesday" means, every spot where we play a song, we're going to play two songs by that artist. Violating every precious elegant rule you put in the system. And I've never had a real-world system that didn't have these kinds of irregularities. And where they weren't important.

포지셔닝된 프로그램의 다른 측면을 살펴보면, 다른 사람과 상호 작용하거나 다른 사람과 동의할 필요가 없는 자신만의 작은 우주와 같은 경우는 거의 없습니다. 거의 모든 시스템이 다른 시스템과 상호 작용했습니다. 거의 모든 시스템이 사람들과 상호 작용했습니다. 누군가 앉아서 "이 노래 지금 틀어주세요" 또는 "이 노래 건너뛰세요"라고 말하면, 저희는 "내가 그 노래를 예약했고, 그 노래를 틀기 위해 모든 밸런스를 맞췄는데, 이제 DJ가 '그러지 마세요'라고 하네요."라고 답합니다.
선거 프로젝션 시스템에는 사용자가 사물을 보고, 교차 표를 만들고, 결정을 내릴 수 있는 수많은 화면이 있으며, 사람들이 다른 사람들에게 설명할 수 있도록 TV에 보이는 모든 것을 제공합니다. 따라서 사람과 사람 사이의 대화는 이러한 프로그램에서 중요한 부분입니다.
이러한 프로그램은 오랜 기간 동안 계속 사용됩니다. 아까 말씀드린 것처럼 이 프로그램들은 버려지는 프로그램이 아닙니다. 제가 작성한 소프트웨어 중 누군가가 더 이상 사용하지 않는 소프트웨어는 많지 않을 겁니다. 사람들은 여전히 사용하고 있습니다.
그리고 그들은 또한 변화하는 세상에 살고 있습니다. 다시 말하지만, 처음 작성할 때는 최선의 계획을 세웠지만 그 후 규칙이 바뀝니다. '목요일은 3번'이 될 수도 있죠. 모르겠지만 그런 일이 발생하면 모든 것을 변경하여 대처하세요.
위치의 또 다른 측면은 제가 최근에 더 많이 생각하고 있는 소프트웨어 환경과 커뮤니티에 위치하는 것입니다. 프로그램을 처음부터 프로그램의 목적만을 위해 모든 코드를 작성하는 경우는 거의 없습니다. 항상 라이브러리를 가져와야 하는 경우가 많습니다. 그리고 그렇게 되면 라이브러리 생태계에 속하게 됩니다. 그리고 그것은 또 다른 문제입니다.
그래서 제가 포지셔닝된 프로그램에 대해 이야기할 때 제 경력에서 제가 쓴 프로그램을 보면 그 중 하나가 정말 눈에 띄죠? 그게 뭔가요? 클로저입니다. 컴파일러는 이와는 달리 이런 문제가 거의 없습니다. 컴파일러는 디스크에서 바로 입력을 받아 전체 세계를 정의할 수 있죠? 언어를 작성할 때는 어떤 작업을 하나요? 언어를 작성할 때 가장 먼저 하는 일은 "화요일에 두 개"를 없애는 것입니다.
[청중 웃음]
그렇죠? 그냥 없애버리면 되죠. 가장 규칙적인 것을 만들려고 노력한 다음 프로그래밍을 하면 이제 제가 스스로 만든 규칙을 적용해야 합니다. 와우, 이보다 더 쉬운 일이 어디 있겠어요?
[청중 웃음]
그리고 실제로는 훨씬 더 간단합니다. 일반적으로 데이터베이스를 사용하지 않습니다. 데이터베이스를 사용해야 한다고 생각하지만요. 유선으로 대화하는 경우는 거의 없으니까요. 따라서 컴파일러와 정리 증명기 등은 이러한 프로그램과는 다릅니다.
Other aspects of situated programs, they rarely are, sort of, their own little universe where they get to decide how things are and they don't need to interact with anyone else or agree with anyone else. Almost all these systems interacted with other systems. Almost all these systems interacted with people. Somebody would sit there and say, "start playing this song right now", or "skip this song", and we're like "I scheduled that song and I balanced everything around you playing it and now your D.J. just said 'don't do that'".
The election projection system has tons of screens for users to look at things, cross-tabulate? things, and make decisions, feeding all the things you see on T.V. so people can explain things to other people. So people and talking to people is an important part of these programs.
They remain in use for long periods of time. These are not throw-away programs, like I said. I don't know that much of the software I ever wrote has stopped being run by somebody. People are still using it.
And they're also situated in a world that changes. So again, your best laid plans are there the day you first write it, but then the rules changes. May be there's "three for Thursdays". I don't know, but when that happens, go change everything to deal with it.
Another aspect of being situated is one I think I've been thinking about a lot more recently is, being situated in the software environment and community. You know, your program is rarely written from scratch with all code that you wrote just for the purpose of the program. Invariably, you're going to pull in some libraries. And when you do, you've situated yourself in that library ecosystem. And that's another thing.
So when I talk about situated programs and you look at the programs I talked about having written in my career one of them really sticks out, right? What's that? Clojure. Compilers, they're not like this, they don't have a fraction of these problems. They take some input right off the disk, they get to define the whole world, right? When you write a language, what do you do? The first thing you do when you write a language, you get rid of any "two for Tuesdays".
[audience laughter]
Right? You can just disallow it. You try to make the most regular thing, and then your programming is just, well, now I have to enforce the rules that I made up for myself. It's like, wow, what could be easier than that?
[audience laughter]
And it really is a lot simpler. They don't generally use a database. Although I think they probably should. They rarely talk over wires and blah, blah, blah, blah, blah. So compilers and theorem provers and things like that are not like these programs.
# Effective

이번 강연의 제목이 "효과적인 프로그램"인데, "효과적"이란 무슨 뜻인가요? "의도한 결과를 만들어낸다"는 뜻인데, 저는 "정확성"이라는 단어에 정말 지쳤기 때문에 이 단어가 중요해졌으면 합니다. "정확하다"는 말은 그냥 "입력 검사기를 만족시킨다"는 뜻이거든요.
[청중 웃음]
제가 전문적으로 했던 프로그램의 소비자(?) 중 누구도 그런 것에 신경 쓰지 않았습니다. 맞아요, 그들은 프로그램이 "작동한다"는 정의에 맞게 작동하는지를 중요하게 생각하죠.
반면에 저는 이것이 '해킹을 위한 레시피'라는 식으로 받아들여지는 것을 원하지 않습니다. 그래서 우리는 "작동"의 의미에 대해 이야기해야 합니다. 실제로 효과가 있다는 것은 무엇을 의미할까요?
So the title of this talk is "Effective Programs", and what does "effective" mean? It means "producing the intended result" and I really want this word to become important because I'm really tired of the word "correctness". Where "correct" just means, I don't know, "make the type checker happy".
[audience laughter]
None of my (?) consumers of these programs that I did professionally care about that. Right, they care that the program works for their definition of "works".
On the other hand, I don't want this to be taken as, "this is a recipe for hacking", right, just like "do anything that kind of works". So we have to talk about what "works" means. What does it mean to actually accomplish the job of being effective.
# What is Programming About?

그래서 저는 '프로그래밍'이라는 이름을 다시 되찾고 싶습니다. 아니면 최소한 클로저와 같은 언어와 그 접근 방식을 포함하는 광범위한 정의를 내려야 합니다. 이런 문제가 중요하다고 생각하기 때문입니다.
그렇다면 프로그래밍이란 무엇일까요? **"저에게 프로그래밍이란 컴퓨터를 세상에서 효과적으로 만드는 것"**이라고 말씀드리고 싶습니다. 여기서 '효과적'이라는 말은 사람이 세상에서 효과적이라는 말과 같은 의미입니다. 프로그램 자체가 효과적이거나 사람들이 효과적이 되도록 돕는 것이죠.
그렇다면 우리는 어떻게 효과적일까요? 글쎄요, 때때로 우리는 정말 잘 계산하기 때문에 효과적일 수 있습니다. 예를 들어 미사일의 궤도를 계산할 때처럼 말입니다. 하지만 대부분은 그렇지 않습니다. 대부분 인간이 노력하는 영역이죠. 우리는 경험을 통해 학습하고 그 경험을 예측력으로 전환할 수 있기 때문에 효과적입니다. 거대한 구멍이나 절벽에 발을 들여놓지 않거나 포효하는 사자를 향해 걸어가지 않는 방법, 사람들에게 마케팅하는 방법, 이 수술에 대한 올바른 접근 방식, 이 문제에 대한 올바른 진단이 무엇인지 등을 알 수 있습니다.
사람들은 학습하고 경험을 통해 배우고 그것을 활용하기 때문에 효과적입니다. 그래서 저는 "효과적이라는 것은 대부분 계산에 관한 것이 아니라 정보에서 예측력을 생성하는 것입니다."라고 말하고 싶습니다.
제가 정보에 대해 이야기하는 것을 들어보셨죠? 정보란 사실에 관한 것이고, 일어나는 일에 관한 것이죠? 특히 이를 프로그래밍 세계로 끌어들일 때는 경험이 중요합니다. 경험은 정보와 같고 정보는 실제로 일어난 일에 대한 사실과 같습니다. 맞아요, 이것이 성공의 원재료입니다. 세상에서는 사람을 위한 프로그램, 사람을 지원하거나 사람을 대체하는 프로그램이 되어야 합니다. 그래야 사람들이 더 흥미로운 일을 할 수 있습니다.
And that's where I want to sort of reclaim the name "programming". Or at least make sure we have a broad definition that incorporates languages like Clojure and the approaches that it takes. Because I think these problems matter.
So what is programming about? I'm going to say, "for me, programming is about making computers effective in the world". And I mean "effective" in the same way we would talk about people being effective in the world. Either the programs themselves are effective or they're helping people be effective.
Now, how are we effective? Well, sometimes we're effective because we calculate really well. Like may be when we're trying to compute trajectories for missles or something like that. But mostly not. Mostly areas of human endeavor. We're effective because we have learned from our experience, and we can turn that experience into predictive power. Whether that's knowing not to step in a giant hole or off a cliff, or walk towards the roaring lion, or how to market to people, or what's the right approach to doing this surgery, or what's the right diagnosis for this problem.
People are effective because they learn and they learn from experience and they leverage that. And so, I'm going to say, "being effective is mostly not about computation, but it's about generating predictive power from information".
And you've heard me talk about information, right? It's about facts, it's about things that happen, right? Experience, especially when we start pulling this into the programming world. Experience equals information equals facts about things that actually happened. Right, that's the raw material of success. In the world, it is for people, it should be for programs that either support people or replace people. So they can do more interesting things.
# What is Programming NOT About?

그래서 저는 "저에게 프로그래밍이란 무엇에 관한 것이 아닌가요?"라고 묻고 싶습니다. 프로그래밍은 그 자체에 관한 것이 아닙니다. 프로그래밍은 유형이 초기 명제와 일치한다는 이론을 증명하는 것이 아닙니다. 그렇지 않죠. 그것은 그 자체로 흥미로운 시도입니다. 하지만 그건 제가 말씀드린 것과는 다릅니다. 제 커리어에서 해왔던 일들이 아닙니다. 프로그래밍이 저를 위한 것도 아니고(?) 제가 프로그래밍을 좋아하는 이유도 아닙니다. 저는 세상에서 무언가를 성취하는 것을 좋아합니다.
버트런드 러셀이 이에 대해 멋지게 비꼬는 말이 있습니다. 사실 비꼬는 게 아니에요. 그는 수학의 위상을 높이고 "수학은 수학 자체에 관한 것이 매우 중요하다"고 말하고 싶었던 것입니다. 선을 넘기 시작하면 안 되죠? 그리고 무대에 서서 "수학적 안전, 유형 안전은 심장 기계의 안전과 같다"고 말하는 것은 수학을 잘못하는 것이라고 버트런드 러셀은 말합니다. 알고리즘과 계산은 중요하지만 우리가 하는 일의 일부분일 뿐입니다.
So I'll also say that, "for me, what is programming not about?". It's not about itself. Programming is not about proving theories about types being consistent with your initial propositions. It's not. That's an interesting endeavor of its own. But it's not, it's not what I've been talking about. It's not the things I've done in my career. It's not (?) programming is for me and it's not why I love programming. I like to accomplish things in the world.
Bertrand Russell has a nice snarky comment about that. He's actually not being snarky. He wants to elevate mathematics and say, "it's quite important that mathematics be only about itself". If you start crossing the line, right? And standing on stage and saying, "mathematical safety, type safety equals heart machine safety", you're doing mathematics wrong, according to Bertrand Russell. And it's not just algorithms and computation, they're important, but they're a subset of what we do.

오해하지 마세요. 저는 논리를 좋아하죠? 스케줄링 시스템, 수율 관리 알고리즘, 데이터로그 엔진도 만들었습니다. 전 논리를 좋아해요. 저는 시스템에서 그런 부분을 작성하는 것을 좋아합니다. 저는 보통 시스템에서 그런 부분을 작업하곤 합니다. 정말 멋진 일이죠.
So, don't get me wrong. I like logic, right? I've written those scheduling systems, I've written those yield management algorithms, I've written a Datalog engine. I like logic. I like writing that part of the system. I usually get to work on that part of the system. That's really cool.
하지만 정리 증명기나 컴파일러도 결국에는 디스크에서 무언가를 읽거나 뱉어내거나 인쇄해야 합니다. 그래서 그것들은 로직이 아닌 다른 무언가의 심입니다. 하지만 제가 해온 프로그래밍과 클로저 프로그래머들이 하는 프로그래밍의 세계에서는 그렇지 않다고 생각합니다,
But even, you know, a theorem prover, or a compiler, you know, eventually needs to read something from the disk, or spit something back out, print something. So they're some shim of something other than the logic. But in this world of situated programs and the kinds of programming that I've done, and I think that Clojure programmers do,
프로그래밍의 작은 부분입니다. 프로그램은 정보 처리가 주를 이룹니다. UI가 없다면 이 주위에 거대한 원이 있고, 이 원은 점처럼 보입니다.
[청중 웃음]
하지만 저는 거기까지는 가지 않겠습니다.
[청중 웃음]
사실 저는 그 부분은 하지 않거든요. 그러나 정보 처리는 실제로 노력과 불규칙성 모두에서 프로그램을 지배합니다. 데이터로그 엔진이 수월한 하루를 보낼 수 있도록 모든 불규칙성을 제거하는 것이 바로 이 정보 부분입니다. 이제 모든 것이 완벽해졌으니까요. 완벽한 것을 볼 수 있으니까요. 누군가 문제가 발생하기 전에 해결해 주었으니까요.
이 일을 가볍게 여기고 싶지 않아요. 정말 중요한 일인 것 같죠? 구글의 가장 멋진 검색 알고리즘이 웹 페이지에 표시되지 않고 사용자가 무언가를 입력하고 엔터키를 눌렀을 때 합리적인 작업을 수행하지 못한다면 아무도 신경 쓰지 않을 것입니다. 그렇죠? 바로 여기에서 알고리즘의 가치 제안이 전달됩니다. 매우 중요한 부분입니다. 하지만 제 경험상
that's a small part of the programming. Programs are dominated by information processing. Unless they have UIs, in which case, there's this giant circle around this, where this looks like a dot.
[audience laughter]
But I'm not gonna go there.
[audience laughter]
Actually, because I don't do that part. But the information processing actually dominates programs both in the effort, the irregularities often there, right? It's this information part that, like, takes all the irregularity out of the way so my Datalog engine can, like, have an easy day. Cuz everything's now perfect, cuz I see a perfect thing, cuz somebody fixed it before it got to me.
And I don't want to make light of this. I think this is super-critical, right? Your best...Google's coolest, you know, search algorithm, if they couldn't get it to appear on a web page and do something sensible when you type, you know, something and pressed enter, no one would care. Right? This is where the value proposition of algorithms gets delivered. It's super important. But in my experience,

이것은 비율인 반면
while this is the ratio
문제를 해결하기 위해 필요한 비율은 다음과 같습니다.
it probably needs to be to solve the problem, this is the ratio

제 경험에 비추어 보면 종종 그렇습니다. 사실 이것도 좀 더 크게 보면 사각형이 점이라고 할 수 있습니다. 프로그램의 정보 부분이 필요 이상으로 커진다는 것은 당시에도 그랬고 지금도 그렇지만 프로그래밍 언어가 대부분 형편없기 때문입니다. 결국 이 작업을 수행하기 위해 엄청난 양의 코드를 작성해야 했습니다. 왜냐하면 이러한 언어의 설계자들이 이 작업을 수행하지 않았기 때문입니다.
it often is, and was in my experience in my work. Actually, this is also sort of bigger, the square would be more of a dot. That the information part of our programs is much larger than it needs to be because the programming languages we had then and still have mostly are terrible at this. And we end up having to write a whole ton of code to do this job. Because it's just not something the designers of those languages took on.
물론 아직 끝나지 않았죠? 우리는 처음부터 프로그램을 작성하지 않으므로 라이브러리를 다루기 시작해야 합니다. 그렇게 하면 이제 "우리가 모든 것을 정의할 수 있다"는 영역에서 벗어나기 시작한 것이죠? 이제 우리는
And of course we're not done, right? We don't write programs from scratch, so we have to start dealing with libraries. When we do that, now we've started to cross out of "we get to define everything" land, right? Now we have
관계를 정의해야 합니다. 그리고 우리는 도서관과 어떻게 대화하고 도서관이 우리에게 어떻게 대화할지 정의해야 하지만 대부분 우리가 도서관과 대화합니다. 이제 선이 있죠? 이 도서관과 어떻게 대화해야 하는지에 대한 프로토콜이 있습니다. 그리고 우리는 여전히
relationships. And we have to define how those, we're going to talk to libraries and how they may talk to us, but mostly we talk to them. So now there are lines, right? There's some protocol of how do you talk to this library. And we're still not
끝났죠? 앞서 말했듯이 이러한 위치 프로그램에는 데이터베이스가 포함됩니다. 정보 처리와 로직, 라이브러리가 모두 프로그래밍 언어를 공유했을 수도 있겠죠? 아니면 적어도 런타임인 JVM 같은 것에서 말이죠. 이제 우리는 그것을 벗어났고(?), 이제 분명히 저기 있는 데이터베이스가 있고, 다른 언어로 작성되었으며, 메모리에 배치되지 않았기 때문에 와이어가 있습니다. 이 데이터베이스는 세상을 바라보는 고유한 관점을 가지고 있으며, 이 데이터베이스와 대화하기 위한 프로토콜이 있습니다. 그리고 그 프로토콜이 무엇이든 항상 우리는 그것을 고치고 싶어 합니다.
[청중 웃음]
그 이유는 무엇인가요? 나중에 '교파주의'라고 부르는 것에 대해 이야기할 텐데, 우리가 채택한 세계관, 프로그래밍 언어가 데이터베이스가 생각하는 방식과 맞지 않기 때문입니다. "우리 쪽이 틀렸나 봐요"라고 말하기보다는 "아, 저 관계형 대수학을 고쳐야겠어... 좋은 생각이 아닐 거야"라고 말하죠.
done, right? Cuz we said, these situated programs, they involve databases. Now, while the information processing and the logic and the libraries may have all shared a programming language, right? Or at least, you know, on the JVM, something like the JVM, a runtime. Now we're out (?) it, now we have a database that's clearly over there, it's written in a different language, it's not colocated in memory, so there's a wire. It has its own view of the world, and there's some protocol for talking to it. And invariably, whatever that protocol is, we want to fix it.
[audience laughter]
And why is that? Well it's something I'm going to talk about later called "parochialism", you know, we've adopted a view of the world, our programming language put upon us and it's a misfit for the way the database is thinking about things. And rather than say, "I wonder if we're wrong on our end", we're like, "oh no, we got to fix that...that relational algebra, it can't possibly be a good idea".
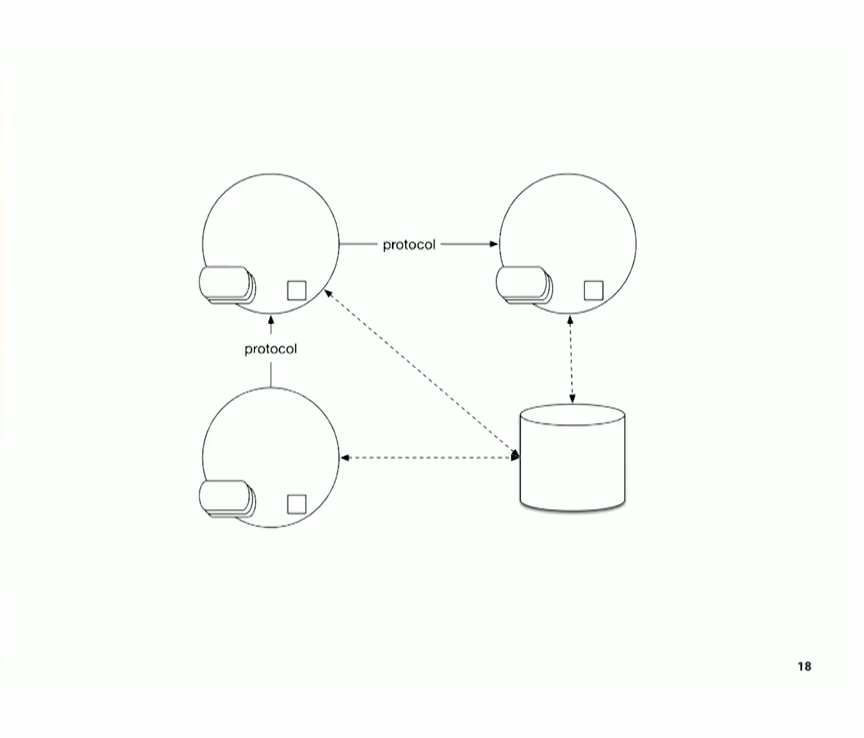
좋아요, 하지만 아직 끝나지 않았습니다. 이 프로그램들은 혼자 있지 않고 다른 프로그램과 대화한다고 말씀드렸습니다. 이제 세 개 이상의 프로그램이 생겼는데 같은 프로그래밍 언어로 작성되지 않았을 수도 있겠죠? 모두 세상을 바라보는 관점이 다르죠. 로직이 어떻게 작동해야 하는지에 대한 아이디어가 모두 다릅니다. 라이브러리와 대화하거나 라이브러리를 사용하는 방법에 대한 아이디어가 모두 다르며, 더 많은 전선과 프로토콜이 있습니다. 데이터베이스 공급업체가 최소한 ORM으로 수정할 수 있는 와이어 프로토콜을 제공하는 것이 아니라 자체 프로토콜을 만들어야 합니다. 그렇게 하면 결국 어떤 결과가 나올까요? JSON이죠? 좋지 않죠.
하지만 적어도 지금은
Ok, but we're still not done. I said these programs, they're not, they don't sit by themselves, they talk to other programs. So now, now we have three or more of these things, and now they may not be written in the same programming language, right? They all have their view of the world. They all have their idea of how the logic should work. They all have their idea of how they want to talk to libraries or use libraries, and there's more wires and more protocols. And here we don't get the database vendor at least giving us some wire protocol to start with that we'll fix with ORM, we have to make up our own protocols. And so we do that and what do we end up with? JSON, right? It's not good.
But at least now
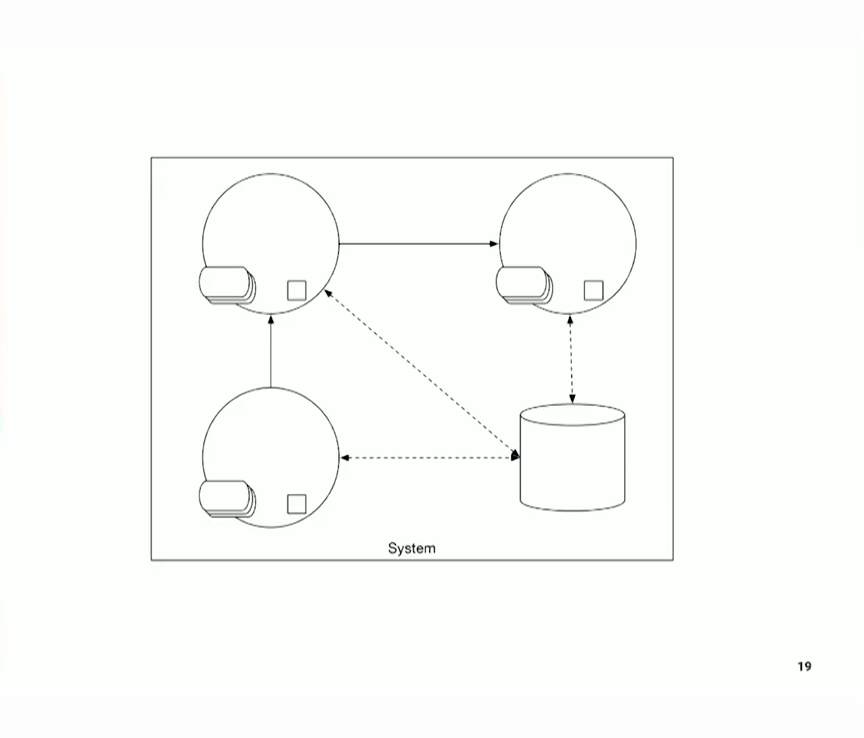
그래서 제가 프로그래밍할 때는 이걸 프로그래밍하는 거죠. 저에게는 이것이 프로그램입니다. 이것은 문제를 해결할 것이고, 이것의 하위 집합으로는 문제를 해결할 수 없습니다. 이것이 문제 해결을 시작하는 첫 번째 지점입니다. 하지만 문제가 끝난 게 아닙니다...
we have something...so when I program, this is what I'm programming. This is a program, to me. This is going to solve a problem and like no subset of this is going to solve the problem. This is the first point you start solving the problem. But you're not done with problems...
단발성, 일회성, 한 순간, 하나의 훌륭한 아이디어로 버튼을 누르고 출시하고 넘어가는 그런 세상이 아니기 때문이죠? 시간이 지남에 따라 모든 측면이 변화하죠? 규칙이 바뀌고, 요구 사항이 바뀌고, 네트워크가 바뀌고, 컴퓨팅 성능이 바뀌고, 사용 중인 라이브러리가 바뀌고, 프로토콜이 바뀌지 않기를 바라지만 때로는 프로토콜이 바뀌기도 합니다. 따라서 우리는 시간이 지남에 따라 이 문제를 해결해야 합니다. 저에게 있어 효과적인 프로그래밍이란 시간이 지남에 따라 이 작업을 잘 수행하는 것입니다.
Because it's not a one-shot, one-time, one-moment, one great idea, push the button, ship it, move on, kind of world, is it? Every single aspect of this mutates over time, right? The rules change, the requirements change, the networks change, the computing power changes, the libraries that you're consuming change, hopefully the protocols don't change but sometimes they do. So we have to deal with this over time. And for me, effective programming is about doing this over time well.

"옳고 그른 방법이 있고, 클로저는 옳고 다른 모든 것은 그르다"라고 말하려는 것이 아니라, 우리 모두 범용 프로그래밍 언어를 작성하고자 하는 열망이 있기 때문에 분명해야 하지만 그렇지 않을 수도 있다고 생각합니다. 예를 들어 클로저로 정리 증명자를 작성할 수도 있겠죠. 물론 그럴 수 있다고 생각합니다. 하지만 컴파일러와 정리 증명자를 대상으로 하거나 장치 드라이버나 전화 스위치를 대상으로 한다면 분명 다른 언어가 필요할 것입니다. 클로저의 타깃은 정보 기반 위치 프로그램이죠? 딱히 눈에 띄는 문구는 없습니다. 하지만 그게 제가 하던 일이었고, 제 친구들도 모두 그렇게 하고 있었어요. 이 방에 있는 사람들 중 몇 명이나 그렇게 하고 있나요? 네. 그러니 프로그래밍 언어를 볼 때는 정말... 무엇을 위한 언어인가를 살펴봐야 합니다. 그렇죠? 적합성 제약 같은 내재적 장점 같은 건 없어요.
So, you know, I'm not trying to say, "there's a right and wrong way, and, like, Clojure is right and everything else is wrong, right?", but it should be apparent, but may be it isn't, because I think we all aspire to write programming languages that are general purpose. You could probably write, you know, a theorem prover in Clojure, actually I'm sure you could. But you certainly would get a different language if your target were compilers and theorem provers or your target were device drivers or phone switches. Clojure's target is information-driven situated programs, right? There's not a catchy phrase for that. But I mean that's what I was doing, all my friends were doing that. How many people in this room are doing that? Yeah. So when you look at programming languages, you really should look at...what are they for? Right? There's no like inherent goodness, like suitability constraints.
# The Problems of Programming
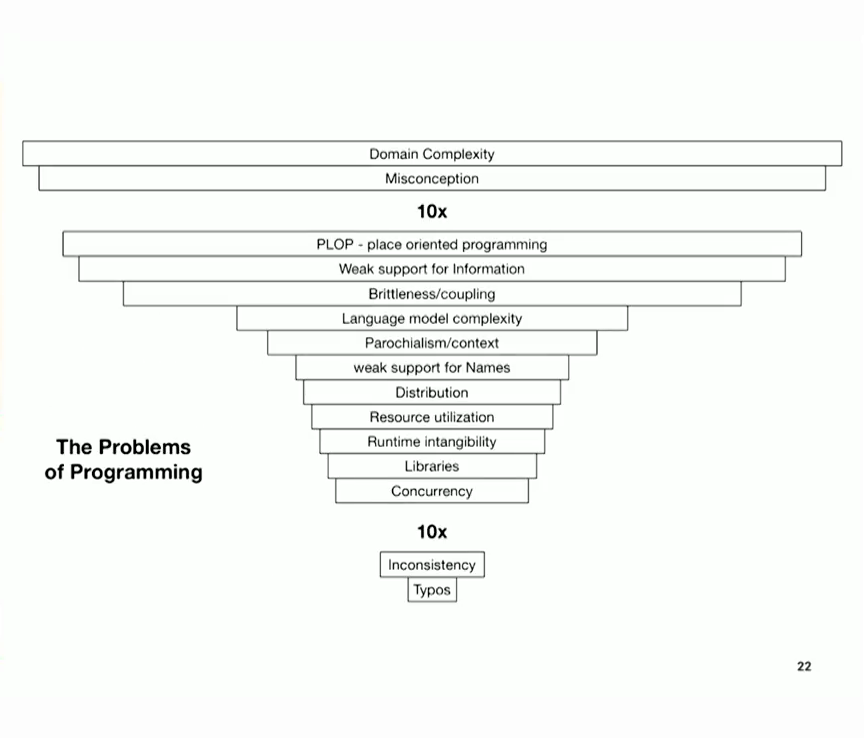
그래서 클로저를 시작하기 전에 이 다이어그램을 그렸는데... 실제로는 그렇지 않았습니다. 만약 그렸다면 놀라운 예지력을 발휘했을 거예요. 하지만 문제를 해결하려고 하지 않는다면 새로운 프로그래밍 언어를 작성할 이유가 없다고 생각하기 때문에 문제가 무엇인지 살펴봐야 합니다. 18년 동안 프로그래머로 일하면서 "커먼 리스프 같은 것으로 전환할 수 없다면 직업을 바꾸겠다"고 말했던 이유는 무엇이었을까요? 제가 왜 그런 말을 할까요? 제가 사용하던 언어의 여러 가지 한계에 좌절감을 느꼈기 때문입니다.
여러분은 이를 문제라고 부를 수 있지만 저는 프로그래밍의 문제라고 부를 것입니다. 제가 여기에 정리해 놓은 것을 읽어 보셨으면 좋겠습니다. 읽을 수 있나요? 네, 알겠습니다. 심각도별로 정리해 보았습니다. 심각도는 몇 가지 방식으로 나타납니다. 가장 중요한 것은 비용입니다. 이 문제를 잘못 해결하면 어떤 비용이 발생할까요? 맨 위에는 아무것도 할 수 없는 도메인 복잡성이 있습니다. 이것이 바로 세상입니다. 그만큼 복잡합니다.
하지만 바로 그 다음 단계가 바로 우리가 프로그래밍을 시작하는 곳입니다. 우리는 세상을 바라보며 "이 세상이 어떻게 되어 있고, 어떻게 되어 있어야 하며, 내 프로그램이 어떻게 하면 이 문제를 효과적으로 해결할 수 있을지 아이디어가 있다"고 말합니다. 문제는 세상이 어떻게 돌아가는지 제대로 파악하지 못하거나 이를 솔루션에 잘 매핑하지 못하면 그 이후의 모든 것이 실패할 수 있다는 것입니다. 이러한 오해의 문제에서 살아남을 수 있는 방법은 없습니다. 그리고 오해에 대처하는 데 드는 비용은 엄청나게 높습니다.
따라서 프로그래밍 언어가 도움을 줄 수 있는 영역에 속한다고 생각되는 일련의 문제에 도달하기 전에 심각도가 10배, 즉 완전히(?) 줄어든 것입니다. 슬라이드를 하나씩 살펴보면서 잠시 후에 모두 읽어보실 수 있기 때문에 지금 다 읽어드리지는 않겠습니다. 하지만 중요한 것은 프로그래밍의 사소한 문제들을 살펴볼 수 있는 또 다른 휴식 시간이 있다는 것입니다. 오타나 일관성이 없는 것, 예를 들어 문자열 목록이 있을 거라고 생각했는데 거기에 숫자를 넣는 것 같은 것들 말이죠. 이런 실수는 누구나 할 수 있는 실수이고, 꽤 흔한 실수입니다.
So before I started Clojure, I drew this diagram...which I did not. That would have been an amazing feat of prescience. But as I try to pick apart, you know, what was Clojure about -- cuz I think there's no reason to write a new programming language unless you're going to try to take on some problems, you should look at what the problems are. I mean, why was I unhappy as a programmer after 18 years and said, "if I can't switch to something like Common Lisp, I'm going to switch careers". Why am I saying that? I'm saying it because I'm frustrated with a bunch of limitations in what I was using.
And you can call them problems, and I'm going to call them the problems of programming. And I've ordered them here -- I hope you can read that. Can you read it? Yeah, ok. I've ordered them here in terms of severity. And severity manifests itself in a couple of ways. Most important, cost. What's the cost of getting this wrong? At the very top you have the domain complexity, about which you could do nothing. This is just the world. It's as complex as it is.
But the very next level is the where we start programming, right? We look at the world and say, "I've got an idea about how this is and how it's supposed to be and how, you know, my program can be effective about addressing it". And the problem is, if you don't have a good idea about how the world is, or you can't map that well to a solution, everything downstream from that is going to fail. There's no surviving this misconception problem. And the cost of dealing with misconceptions is incredibly high.
So this is 10x, a full order of magnitude reduction in (?) severity before we get to the set of problems I think are more in the domain of what programming languages can help with, right? And because you can read these they'll all going to come up in a second as I go through each one on some slide so I'm not going to read them all out right now. But importantly there's another break where we get to trivialisms of problems in programming. Like typos and just being inconsistent, like, you thought you're going to have a list of strings and you put a number in there. That happens, you know, people make those kinds of mistakes, they're pretty inexpensive.
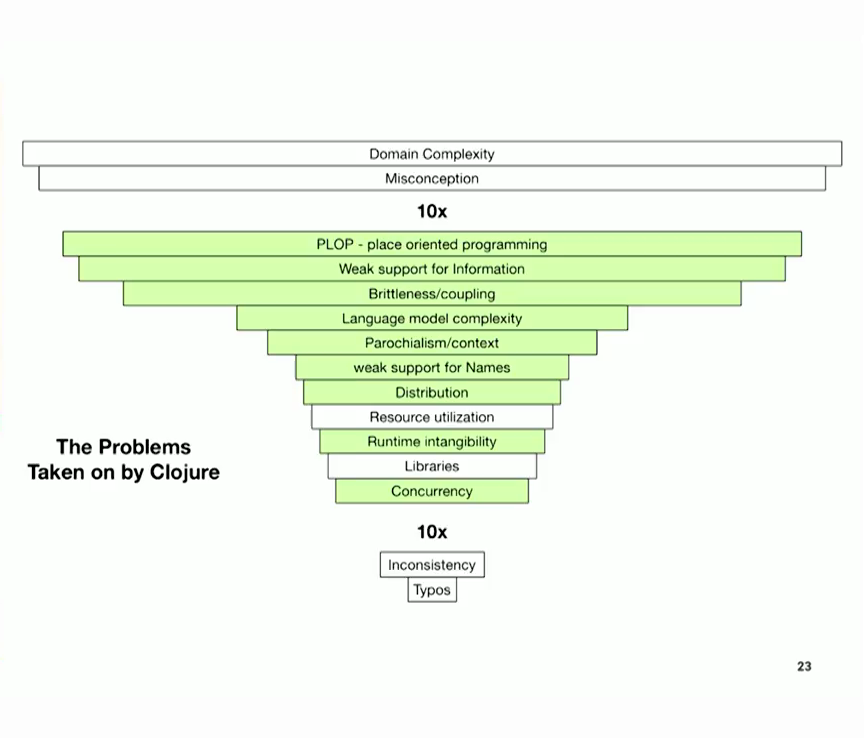
그렇다면 클로저가 해결한 문제들은 무엇이었을까요? 잠시 후에 다시 녹색 문제를 모두 살펴보겠지만, 중간에 있는 문제 중에서 클로저는 리소스 활용에 대해 자바가 했던 것과는 다른 시도를 하지 않았다고 생각합니다. 그 런타임과 비용 모델을 채택한 셈이죠. 저는 클로저가 좋은 라이브러리 언어가 되기를 바랐지만, 클로저의 일부로서 라이브러리 생태계 문제를 생각하지 않았습니다. 그리고 작년에 제가 라이브러리에 대해 이야기한 것은 이것이 여전히 프로그램에서 큰 문제라고 생각한다는 것을 의미합니다. 남은 과제 중 하나죠? 클로저와 데이터마이크로를 사용하고 나면 남은 문제는 무엇인가요?
[청중 웃음]
라이브러리, 라이브러리는 있죠. 하지만 불일치나 오타 같은 건 그다지 많지 않죠. 클로저로 충분히 해결할 수 있죠. 사실 클로저는 오타를 수정할 수 있는 꽤 좋은 도구입니다.
So, what were the problems that Clojure took on, these green ones. And again I'll go through all the green ones in a moment, but I would say, amongst the ones in the middle, I don't think that Clojure tried to do something different about resource utilization than Java did. Sort of adopted that runtime and its cost model. And I don't think that...I mean I wanted Clojure to be a good library language, but I didn't think about the library ecosystem problems as part of Clojure. And, you know, my talk last year about libraries implies that I still think this is still a big problem for programs. It's one of the ones that's left, right? After you do Clojure and Datomic, what's left to fix?
[audience laughter]
# Clojure Design Objectives
And the libraries, the libraries are there. But not the inconsistency and typos, not so much. I mean we know you can do that in Clojure. It's actually pretty good, letting you make typos.

그렇다면 근본적으로 클로저는 무엇에 관한 것일까요? 더 간단한 것으로 프로그램을 만들 수 있을까요? 18년 동안 C++와 Java를 사용했다면 지칠 대로 지쳤을 겁니다. 18년 동안 프로그래밍을 해온 사람이 몇 명이나 될까요? 그렇군요. 20년 이상은 몇 명이나 될까요? 25년 이상? 알겠어요? 5명 미만? 맞습니다(?), 그래서 정말 흥미롭습니다. 클로저가 초보자를 위한 언어라는 것을 반증하는 것일 수도 있고, 클로저가 짜증나고 피곤하고 나이 많은 프로그래머를 위한 언어라는 것일 수도 있습니다.
[청중 웃음과 박수]
그리고 그거 아세요? 저는 그게 사실이라고 해도 부끄럽지 않아요. 왜냐하면, 아시다시피 저는 제 자신을 위해 만들었고, 그게 중요한 일이라고 생각하니까요. 다른 사람의 문제를 해결하고 그 문제를 이해했다고 생각하는 것은 어려운 일입니다.
그래서 C++를 사용하다가 커먼 리스프를 알게 되었을 때 "이 질문에 대한 답은 '네, 물론입니다'라고 확신합니다."라고 말했죠. 인지 부하를 줄이면서 그렇게 할 수 있을까요? 저도 "네, 물론이죠"라고 생각합니다. 그 다음 질문은 "Java나 C# 대신 사용할 수 있는 Lisp를 만들 수 있는가?"입니다. 방금 제 이야기를 들으셨겠지만, 저도 커먼 리스프를 몇 번(?) 사용했지만 그때마다 프로덕션에서 퇴출되거나, 퇴출되지는 않았지만 기회를 얻지 못했거든요. 그래서 사람들이 받아들일 수 있는 런타임을 목표로 삼아야 한다는 걸 알았죠.
So fundamentally, what is Clojure about? Can we make programs out of simpler stuff? I mean, that's the problem after 18 years of using, like, C++ and Java, you're exhausted. How many people have been programming for 18 years? Ok. How many for more than 20 years? More than 25? Ok? Fewer than 5? Right (?), so that's really interesting to me. It may be an indictment of Clojure as a beginner's language or may be that Clojure is the language for cranky, tired, old programmers.
[audience laughter and applause]
And, you know what? I would not be embarrassed if it was, that's fine by me. Because, you know, I did make it for myself, which I think is an important thing to do. Trying to solve other people's, you know, problems and think you understand what they are, you know, that's tricky.
So, when I discovered Common Lisp, having used C++, I said that, "I'm pretty sure to the answer to this question is, 'yeah, absolutely'". And can we do that with a lower cognitive load? I also think, "yes, absolutely". And then the question is, "can I make a Lisp I can use instead of Java or C#?". Cuz you just heard my story, and I used Common Lisp a (?) couple of times, every time it got kicked out of production, or just ruled out of production, really not kicked out, it didn't get a chance. So I knew I had to target a runtime that people would accept.

이런 메타 문제가 있죠? 프로그래밍 문제에 도전해 볼 수는 있지만 언어를 채택하는 데는 항상 문제가 있습니다. 저는 클로저가 받아들여질 거라고 생각하지 못했어요. 정말 솔직히 말해서요. 하지만 저를 미쳤다고 생각하는 친구, 즉 저 말고 다른 사람도 시도하게 하려면 수용성 문제와 전력 문제에 대한 신뢰할 수 있는 답이 있어야 한다는 걸 알았어요. 그렇지 않으면 "리치, 그건 멋지지만 우린 할 일이 있어"와 같이 실용적이지 않으니까요.
[청중 웃음]
"이걸 전문적으로 사용할 수 없다면 정말 취미일 뿐이죠." 그래서 우리는 수용성이 있고, 그것은 성능과 관련이 있다고 생각하며, 저에게는 배포 플랫폼이라고 생각했습니다. 이 부분에 대해서는 나중에 다시 이야기하겠습니다. 그리고 호환성 문제도 있습니다. 이 역시 수용성의 일부입니다. 하지만 "그냥 자바 라이브러리일 뿐"이라고 말할 수 있는 클로저의 능력은 대단했습니다. 얼마나 많은 사람들이 처음부터 조직에 클로저를 몰래 도입했나요? 그렇군요. 성공했죠!
[청중 웃음]
So there are these meta problems, right? You can try to take on some programming problems but there are always problems in getting a language accepted. I did not think Clojure would get accepted. Really, honestly. But I knew, if I wanted my friend who thought I was crazy even doing it, like, person number one other than myself to try it, I'd have to have a credible answer to the acceptability problems and the power problems. Because otherwise it's just not practical, it's like, "that's cool Rich, but, like, we have work to do".
[audience laughter]
"If we can't use this professionally, really it's just a hobby". So we have acceptability, I think that goes to performance, and for me, I thought it was also the deployment platform. There's a power challenge that you have to deal with, and that's about leverage and I'll talk about that later. And also compatibility. Again that's part of acceptability. But, you know, Clojure's ability to say "it's just a Java library", was big. How many people snuck Clojure into their organization to start with? Right, ok. Success!
[audience laughter]
# Non-problems

그리고 제가 절대 문제가 되지 않는다고 생각한 다른 것들도 있었는데, 그 중 첫 번째가 괄호죠? 얼마나 많은 사람들이... 그리고 인정해도 괜찮죠? 모든(?) 괄호에는 사연이 있습니다. 괄호가 문제가 될 거라고 생각했다가 지금은 그게 미친 생각이었다고 생각하는 사람이 얼마나 될까요? 그렇죠. 괜찮아요, 누구나 다 겪는 일이라고 생각해요. Lisp를 보는 모든 사람은 "멋지지만 시작하기 전에 이 부분을 고쳐야겠어... 시작하기 전에, 가치 제안을 전혀 이해하기 전에 이 부분을 고쳐야겠어"라고 생각하는데, 이는 프로그래머에 대한 무언가를 말해줍니다. 정확히 뭔지는 잘 모르겠습니다. 하지만 저는 이것이 문제라고 생각하지 않으며, 사실 이 강연의 중반에 이르면 이것이 문제와는 정반대라고 생각한다는 것을 알게 될 것입니다. 이것이 바로 클로저의 핵심 가치 제안입니다. 그리고 저는 나쁜 것이 무엇이든 간에 파묻어버리는 것은 끔찍한 생각이라고 생각합니다. 초보자가 기능인 문제를 해결하려고 시도하는 것은 좋지 않다고 생각합니다.
제가 문제가 되지 않는다고 생각한 또 다른 이유는 동적이라는 점이었죠? 저는 C++에서 일했는데, 컴파일만 되면 '아마 작동할 거야'라고 말하는(?) 일이 있었죠? 하스켈에 대해 말하는 것처럼요. 그때도 그랬고 지금도 마찬가지입니다.
[청중 웃음]
하지만 저희는 정말 믿었습니다. 정말 그랬죠. 그리고 그것은 도움이 되지 않습니다. 큰 문제에는 정말 도움이 되지 않죠.
And then there were other things I considered to be absolute non-problems and the first of these is the parentheses, right? How many people...and it's ok to admit, right? Every (?) has a story. How many people thought the parentheses were going to be a problem and now think that was crazy thinking? Yeah. Which is fine, I think everybody goes through that. Everybody who looks at Lisp is like, "this is cool but I'm going to fix this part before I get going...before I start, before I understand the value proposition of it at all, I'm going to fix this", and that says something about programmers. I'm not sure exactly what. But I don't believe this is a problem and in fact when we get to the middle of this talk you'll see that I think this is the opposite of a problem. This is the core value proposition of Clojure. And I think things like, par-make-it-go-away whatever that is a bad...it's a terrible idea. And it's not good for beginners to do that, to, you know, to try to solve a problem that's, that's a feature.
The other thing I considered not a problem is it being dynamic, right? I worked in C++, you know, we had a thing where (?) we said, "if it compiles it will probably work", right? Like they say of Haskell. And it was equally true then as it is now.
[audience laughter]
But we really did believe it. We totally did. And it doesn't help. It really does not help for the big problems.
# PLOP - Place Oriented Programming

맨 위, 크고 넓은 것들.
자, 그 목록의 첫 번째 문제는 장소 지향 프로그래밍이었습니다. 당연히 이것이 문제입니다. 제가 작성한 거의 모든 프로그램, 그 목록에 있는 많은 것들이 멀티 스레드 프로그램이었죠. C++에서는 정말 어렵습니다. 일반적인 가변성 접근 방식, 즉 가변 객체를 채택하면 제대로 구현하기가 불가능합니다. 그래서 이것이 가장 큰 자해적 프로그래밍 문제입니다. 함수형 프로그래밍과 불변 데이터를 기본 관용구로 삼는 것이 해답이라는 것이 분명해 보였습니다. 그래서 제가 직면한 과제는 "이 데이터를 저 데이터로 바꿀 수 있다"고 말할 수 있을 만큼 빠른 데이터 구조가 있느냐는 것이었습니다. 그리고 제가 세운 목표는 읽기는 2배, 쓰기는 4배 이내로 줄이는 것이었습니다. 저는 이 부분에 대해 많은 연구를 했는데, 사실 이것이 클로저의 주요 연구 작업이었으며, 이러한 영구 데이터 구조에 관한 것이었습니다. 결국 저는 오카사키의 자료와 완전한 기능적 접근 방식을 살펴봤지만 여기에는 아무것도 들어 있지 않다는 것을 알게 되었습니다. 그러다 백웰의 구조가 지속적이지는 않지만 그렇게 만들 수 있다는 것을 깨달았고, 지속성과 배치 방식, 메모리 작동 방식이 결합된 매우 훌륭한 특성을 가지고 있다는 것을 알게 되었습니다. 그들은 그것을 만들었습니다. 그들은 이 바를 만들었고, 저는 제 친구에게 프로그래밍 언어를 시험해 볼 수 있었습니다. 이를 지원하기 위한 대규모 순수 함수 라이브러리와 변경 불가능한 로컬 바인딩이 있죠. 기본적으로 클로저에 빠지면 첫 번째 장애물은 괄호가 아니죠? 이 함수형 패러다임은 모든 것이 사라지고 가변 변수, 상태, 가변 컬렉션 등 모든 것이 사라졌지만 많은 지원이 있고 큰 라이브러리가 있습니다. 관용구만 익히면 됩니다. 클로저의 가장 큰 차이점은 제가 클로저를 사용할 무렵에는 이 기술을 개발한 사람들이 클로저를 훨씬 더 많이 채택하고 있었다는 점입니다. 함수형 프로그래밍 커뮤니티의 대부분의 지지자들은 함수형 프로그래밍을 타입 함수형 프로그래밍, 정적 타입 함수형 프로그래밍이 함수형 프로그래밍이라고 생각했습니다. 그리고 저는 그렇게 생각하지 않습니다. 이것은 80/20 규칙에 명확하게 해당한다고 생각합니다. 그리고 여기서 분할은 99/1에 더 가깝다고 생각합니다. 가치 소품은 모두 이쪽에 있고, 클로저 사용자라면 그 점을 느낄 수 있을 것입니다. 이것이 바로 여러분을 밤에 잠들게 하는 것입니다.
The top, the big wide ones.
Ok, so, problem number one on that list was place oriented programming. Absolutely, this is the problem. Almost all the programs I wrote, lots of the things on that list were multi-threaded programs, you know, they're crazy hard in C++. Just impossible to get right, when you adopt a normal mutability approach, you know, mutable objects. So, this is the number one self-inflicted programming problem. It seemed, you know, clear to me that the answer was to make functional programming and immutable data the default idiom. So the challenge I had was, were there data structures that would be fast enough to say, "we could swap this for that". And the objective I had, the goal I had was to get within 2x for reads and 4x for writes. And I did a lot of work on this, this was actually the main research work behind Clojure, was about these persistent data structures. Eventually I found...you know I looked at Okasaki's stuff and, you know, the fully functional approach and none of that gets here. And then I found Bagwell's structures were not persistent, but I realized could be made so, and they just have tremendously great characteristics combining the persistence with the way they're laid out, the way memory works. They made it. They made this bar, and I was able to get my friend to try my programming language. You know, we (?) have large library of pure functions to support this, and, you know, immutable local bindings. Basically if you fall into Clojure, your first hurdle is not the parentheses, right? It's this, this functional paradigm, everything is gone, there's no mutable variables, there's no state, there's no mutable collections and everything else, but there's a lot of support, there's a big library. You just have to, you know, sort of learn the idioms. So I think this was straight-forward, the critical thing that's different about Clojure is, by the time I was doing Clojure, the people who invented this stuff had adopted a lot more, right? I think most of the adherents in the functional programming community considered functional programming to be about typed functional programming, statically typed functional programming is functional programming. And I don't think so, I think that this is, you know, this falls clearly in the 80/20 rule. And I think the split here is more like 99/1. The value props are all on this side, and I think Clojure users get a sense of that, they get a feel for that. This is the thing that makes you sleep at night.
# Information

두 번째 문제는 가장 미묘한 문제인데, 정적으로 타입이 지정된 프로그래밍 언어에 대해 제가 가장 짜증나는 점은 정적으로 타입이 지정된 프로그래밍 언어가 정보에 꽝이라는 점입니다. 그럼 정보가 무엇인지 살펴봅시다. 본질적으로 정보는 희소합니다. 정보는 우리가 알고 있는 것, 세상에서 일어난 일입니다. 세상이 양식을 작성하고 모든 것을 대신 채워주나요? 여러분이 알고 싶은 모든 것을요? 아니요! 그렇지 않습니다. 지금도 그렇고 앞으로도 그럴 것입니다.
다른 하나는 "무엇을 알 수 있는가?"입니다. 무엇을 알 수 있을까요? 이 질문에는 정답이 없습니다. 원하는 건 뭐든지요? 열려 있죠? 또 뭐가 있을까요? 알아야 할 게 뭐가 있냐고요? 지금 몇 시죠? 매초가 지날 때마다 알아야 할 것이 더 많아지고, 더 많은 일이 일어나고, 더 많은 사실이 밝혀지고, 더 많은 일이 우주에서 일어나고 있습니다. 그래서 정보는 계속 쌓여만 갑니다. 정보에 대해 우리는 또 무엇을 알고 있을까요? 우리는 이름을 사용하는 것 외에는 정보를 다룰 수 있는 좋은 방법이 없죠? 사람으로서 정보를 다룰 때 이름은 매우 중요하죠? 제가 그냥 "47"이라고 말하면 이제 의사소통이 전혀 이루어지지 않아요. 우리는 그것을 연결해야 합니다. 그리고 또 다른 큰 문제는 제가 자주 고민하는 부분입니다. 시스템이 있고 어떤 데이터에 대한 클래스나 유형을 만들었는데, 여기서 그보다 조금 더 많은 데이터를 알고 있다면 파생이 있다면 그와 비슷한 다른 것을 만들어야 할까요, 아니면 파생하여 다른 것을 만들어야 할까요? 만약 내가 지금 다른 컨텍스트에 있고 어떤 것의 일부와 다른 것의 일부를 알고 있다면, 이것의 일부와 저것의 일부의 유형은 무엇일까요? 그리고 나서 폭발이 일어나겠죠. 물론 이러한 언어에는 구성 가능한 정보 구조가 없기 때문에 이러한 문제가 발생합니다.
Ok, problem number two -- and this is the most subtle problem, this is the thing that annoys me the most about statically typed programming languages -- is they are terrible at information. So let's look at what information is. Inherently, information is sparse. It's what you know, it's what happened in the world. Does the world fill out forms and fill everything out for you? All the things you'd like to know? No! It doesn't. It doesn't and not ever is probably more correct.
The other thing is, "what can you know?". What are you allowed to know? There's no good answers to that. Whatever you want, right? It's open, right? What else is there? What IS there to know? Well I mean, what time is it, right? Cuz every second that goes by, there's more stuff to know, more things happen, more facts, more things happen in the universe. So information accretes, it just keeps accumulating. What else do we know about information? We don't really have a good way of grappling with it, except by using names, right? When we deal with information as people, names are super-important, right? If I just say, "47", now there's no communication going on. We have to connect it. And then the other big thing, and this is the thing I struggle with so often, right? I have a system, I made a class or a type about some piece of data, then over here I know a little bit more data than that, do I make another thing that's like that if I have derivation, do I derive to make that other thing? What if I'm now in another context and I know part of one thing and part of another thing, what's the type of part of this and part of that. And then, you know, there's this explosion. Of course these languages are doing this wrong, they don't have composable information constructs.
# The Information Programming Problem

그렇다면 정보와 호환되는 방식으로 프로그래밍할 때 어떤 문제가 있을까요? 그것은 정보의 컨테이너를 시맨틱 드라이버로 격상시킨다는 점입니다. 예를 들어 "이 사람은 사람이고, 이 사람은 이름이 있고, 이 사람은 이메일이 있고, 이 사람은 주민등록번호가 있다"라고 하면, 이 세 가지에 대한 의미는 사람 클래스나 유형 등 그것이 무엇이든 간에 그 맥락 외에는 없습니다. 그리고 프로그래밍 언어에 따라 이름이 없는 경우도 많죠? 예를 들어 사람 x, x - 문자열, x - 인트, x - 문자열, x - 문자열, x - 인트, x - 플로트, x - 플로트, 제품 유형과 같은 제품 유형이 있는 경우입니다. 사람, 이름, 인간의 사고에 대해 완전히 냉담하게(?) 무시하는 것 같은, 미친 짓입니다. 또는 프로그래밍 언어에 이름이 있긴 하지만 그냥 컴파일되는 거죠? 일류도 아니고, 인자로 사용할 수도 없고, 조회 벡터로 사용할 수도 없죠? 그 자체로 함수로 사용할 수도 없죠? 참고로 프로그래밍 언어에는 구성 대수학이 없습니다. 그래서 우리는 다른 목적을 위해 존재했던 이 구조들을 우리에게 주어진 전부이고 관용적인 것이기 때문에 사용해야만 합니다. 클래스를 꺼내고, 유형을 꺼내고, 이런 일을 하죠. 하지만 가장 중요한 것은 집계가 의미를 결정한다는 것인데, 이는 완전히 잘못된 생각입니다. 양식을 작성할 때, 그 양식에 입력하는 정보에 대한 어떤 것도 의미론적으로 그 양식에 의해 지배되지 않습니다. 그것은 수집 장치일 뿐 의미론적 장치는 아니지만 그렇게 됩니다. 그리고 정보를 둘러싼 거대한 집합이 구체화되면 어떻게 될까요? 자바 라이브러리를 작성하는 사람들은 자바 프레임워크가 멋지고 상대적으로 작으며 모든 것이 기계적인 것에 관한 것이라고 생각합니다. Java는 기계적인 것, 즉 메커니즘에 능숙합니다. 하지만 정보에 기반한 프로그램 문제를 해결하려는 가난한 애플리케이션 프로그래머에게 같은 언어를 건네주면 그들이 가진 것은 그것뿐입니다. 그리고 그들은 필요한 모든 것, 모든 조각, 모든 작은 정보 집합에 대해 수업을 듣게 되죠? 1500개가 넘는 클래스가 있는 Java 라이브러리를 본 사람이 얼마나 될까요? 네, 모두 다요. 그리고 이것이 제 경험입니다. 제 경험상(?) 어떤 언어를 사용하든 상관없습니다. 이러한 유형이 있고 정보를 다루고 있다면, 컴포저블하지 않은 유형이 확산될 것이고, 각 유형은 구성되지 않는 작은 데이터 조각을 중심으로 약간의 교파주의를 갖게 될 것입니다.
프로그래밍 문헌에서 "추상화"라는 단어는 두 가지 의미로 쓰이는데, 저는 이 점이 정말 마음에 들지 않습니다. 한 가지 방법은 "무언가에 이름을 붙이는 것이 추상화"라는 것인데, 저는 이에 동의하지 않습니다. 추상화란 일련의 예제에서 어떤 본질적인 것을 도출하는 것이어야 하죠? 단순히 이름을 짓는 것이 아니라구요. 그리고 실제로 여기서 일어나는 일은 데이터 추상화가 아니라 데이터 구체화가 일어나고 있다는 것이죠? 관계형 대수학은 데이터 추상화입니다. 데이터로그는 데이터 추상화입니다. RDF는 데이터 추상화입니다. 사람 클래스, 제품 클래스는 데이터 추상화가 아닙니다. 구체화입니다.
So what is the problem with programming in a way that's compatible with information. It's that we elevate the containership of information to become the semantic driver. Okay, we say, "this is a person, and a person has a name, and a person has an email, and a person has a social security number", and there's no semantics for those three things except in the context of the person class or type, whatever it is. And often, depending on the programming language, the names are either not there, right? If you got these product types where it's like, person is string x, x - string, x - int, x - string, x - string, x - int, x - float, x - float, product type. Like, a (?) complete callous disregard for people, names, human thinking, it's crazy. Or your programming language may be has names, but they compile away, right? They're not first class, you can't use them as arguments, you can't use them as look-up vectors, right? You can't use them as functions themselves, right? There's no compositional algebra in programming languages, for information. So we're taking these constructs, I think were there for other purposes, we have to use them because it's all we're given, and it's what's idiomatic, right? Take out a class, take out, you know, a type and do this thing. But the most important thing is that the aggregates determine the semantics, which is dead wrong, right? If you fill out a form, nothing about the information you put on that form is semantically dominated by the form you happen to fill out. It's a collecting device, it's not a semantic device, but it becomes so. And what happens if you get these giant sets of concretions around information. You know, people that write, you know, Java libraries, you look at the Java Framework it's cool, it's relatively small and everything's about sort of mechanical things. Java's good at mechanical things, well mechanisms. But then you hand the same language to the poor application programmers who are trying to do this information situated program problem, and that's all they've got. And they take out a class for like everything they need, every piece, every small set of information they have, right? How many people have ever seen a Java library with over 1500 classes? Yeah, everybody. And this is my experience. In (?) my experience, it doesn't matter what language you're using. If you have these types, and you're dealing with information, you're going to have a proliferation of non-composable types, that each are a little parochialism around some tiny piece of data that doesn't compose. And I'm really not happy with this, you know...in programming literature, the word "abstraction" is used in two ways. One way is just like, "naming something is abstracting", I disagree with that. Abstracting really should be drawing from a set of exemplars some essential thing, right? Not just naming something. And what I think is actually happening here is we're getting not data abstractions, you're getting data concretions, right? Relational algebra, that's a data abstraction. Datalog is a data abstraction. RDF is a data abstraction. Your person class, your product class, those are not data abstractions. They're concretions.
# Clojure and Information

실제로 클로저는 "그냥 맵(Map)만 사용하세요"라고 말합니다. 이 말은 실제로는 "클로저가 다른 것을 제공하지 않는다"는 뜻이었죠? 사용할 다른 것이 없었습니다. 클래스도 없었고, 타입도 없었고, 대수 데이터 타입 같은 것도 없었고, 디프타입이라고 할 만한(?) 것도 없었습니다. 맵(지도)이 있었고, 이를 지원하는 거대한 함수 라이브러리가 있었고, 구문 지원이 있었습니다. 따라서 이러한 연관 데이터 구조로 작업하는 것은 실체적이고, 잘 지원되며, 기능적이고, 고성능의 작업이었습니다. 그리고 그것들은 일반적입니다. 여기에는 일부 정보만 있고 저기에는 일부 정보만 있는데(?) 이 두 가지가 모두 필요한 경우 클로저에서는 어떻게 해야 할까요? 우리는 "뭐가 문제야?"라고 말합니다. 문제 없습니다. 일부 정보, 일부 정보를 가져와서 병합해서 전달하면 되니까요. 그 중 일부가 필요하면 일부만 가져와서 전달합니다. 키를 호출하고 선택 키를 누르면 하위 집합을 얻을 수 있습니다. 연관 데이터와 관련된 대수학이 있기 때문에 원하는 것은 무엇이든 결합할 수 있습니다. 이름은 일류급이죠? 키워드와 기호는 함수이며, 연관 컨테이너의 함수이고, 스스로 찾는 방법을 알고 있습니다. 그리고 이 세 가지를 찾기 위해 자바나 하스켈 패턴 매칭을 작성하는 방법을 아는 프로그램을 작성하지 않고도 프로그램에서 "이 세 가지를 골라내라"고 말할 수 있도록 재정의되어 있습니다. 프로그램 언어와는 별개잖아요? 그냥 인수일 뿐입니다. 그냥 데이터 조각일 뿐이죠. 하지만 이런 기능이 있습니다.
그리고 제가 생각하는 클로저의 또 다른 잠재력(?)은 - 정도는 다르지만, 이 작업을 수행하기 위한 원재료는 존재합니다 - 의미를 집계가 아닌 속성과 연관시킬 수 있다는 것입니다. 왜냐하면 우리는 정규화된 기호와 키워드를 가지고 있기 때문입니다. 그리고 분명히 스펙은 그것에 관한 것입니다.
So, you know, we know in practice, Clojure says, "just use maps". What this meant actually was, "Clojure didn't give you anything else", right? There was nothing else to use. There were no classes, there weren't (?) the thing to say deftype, there weren't types, there wasn't algebraic data types or anything like that. There were these maps, and there was a huge library of functions to support them, there was syntactic support for it. So working with these associative data structures was tangible, well-supported, functional, high-performance activity. And they're generic. What do we do in Clojure if we have just some of the information here and just some of the information there (?) we need both those things over there? We say, "what's the problem?". There's no problem. I take some information, some information and merge them, I hand it along. If I need a subset of that, I take a subset of that. I call keys, and you know, select-keys and I get a subset. I can combine anything that I like, there's an algebra associated with associative data. The names are first-class, right? Keywords and symbols are functions, they're functions of associative containers, they know how to look themselves up. And they're reified so you can tangibly flow them around your program and say, "pick out these three things" without writing a program that knows how to write Java or Haskell pattern matching to find those three things. They're independent of the program language, right? They're just arguments. They're just pieces of data. But they have this, they have this capability.
And the other thing which I think is a potential of (?) Clojure -- it's realized to varying degrees, but the raw materials for doing this are there -- is that we can associate the semantics with the attributes and not with the aggregates, right? Because we have fully qualified symbols and keywords. And obviously spec is all about that.
# Brittleness/coupling

좋아요, 취성과 커플링, 이것도 제 개인적인 경험에 따르면(?) 정적 유형 시스템이 훨씬 더 많은 커플링을 생성한다는 것입니다. 그리고 우리가 어떤 문제를 해결하려고 하는지에 대한 최종 다이어그램의 시간적 측면의 큰 부분은 유지보수를 할 때 커플링이 지배적이지 않습니까? 흐르는 유형 정보는 프로그램에서 커플링의 주요 소스입니다. 프로그램에서 수백 군데에 있는 구조적 표현의 패턴을 일치시키는 것도 커플링이죠? 20년 동안 프로그래밍을 해오면서 얻은 감성이 커플링을 싫어하는 것을 보면 정말 화가 나요. 커플링은 최악의 상황이고, 그 냄새를 맡으면 그 어떤 것도 원하지 않죠. 그리고 이것은 큰 문제입니다.
더 미묘한 문제라고 생각되는 또 다른 문제는 위치 시맨틱이 확장되지 않는다는 것입니다. 위치 의미론의 예는 무엇일까요? 인자 목록이죠? 대부분의 언어가 가지고 있고(?) 클로저에도 몇 가지가 있죠? 인수가 17개인 함수를 누가 호출하고 싶겠습니까? 아니요.
[청중 웃음]
모든 방에 하나씩은 있죠.
[청중 웃음]
누구도 그렇게 하지 않죠, 우리 모두는 그것이 고장난다는 것을 알고 있습니다. 어디가 고장 났나요? 다섯, 여섯, 일곱? 어느 순간 우리는 더 이상 행복하지 않아요. 하지만 그게 전부라면, 제품 유형만 있다면 그 한계에 도달할 때마다 고장이 나겠죠? 얼마나 많은 사람들이 병원에 가서 양식을 작성하는 것을 좋아하나요? 싫지 않으세요? 공란으로 된 큰 종이에 "42번 줄에 사회보장번호를 적고 17번 줄에 이름을 적으라"는 규칙이 적혀있는데, 그게 바로 세상이 작동하는 방식이죠? 그게 세상이 돌아가는 방식이고, 우리가 다른 사람들과 대화하는 방식이죠? 아니요! 그건 확장되지 않아요. 우리가 하는 방식이 아니에요. 우리는 항상 물건 바로 옆에 레이블을 붙이고 레이블이 중요하지만, 위치 의미론에서는 "아니요, 중요하지 않습니다(?) 그냥 (?) 세 번째는 이것을 의미하고 일곱 번째는 저것을 의미합니다."라고 말하죠.
그리고 유형은 도움이 되지 않죠? 이것, 부동 소수점, 부동 소수점, 부동 소수점, 부동 소수점, 부동 소수점, 부동 소수점... 어느 순간부터는 아무 의미가 없죠. 그래서 그것들은(?) 확장되지 않지만... 다른 곳에서 발생하므로 인수 목록이 있고 제품 유형이 있고 다른 곳이 있습니까? 매개변수화, 맞죠? 타입 인자가 7개 이상인 제네릭 타입을 본 사람 있나요? 아니면 C++나 자바에서(?) 보셨나요? 네, 자바에서는 사람들이 매개변수화를 포기하기 때문에 잘 보지 않는 경향이 있죠?
[청중 웃음]
그리고 그들은 무엇으로 전환하나요? 스프링!
[청중 웃음]
아니요, 농담이 아니라 사실입니다. 인젝션을 위해 더 동적인 시스템으로 전환한 거죠? 매개 변수화가 확장되지 않는 이유 중 하나는(?) 매개 변수에 레이블이 없기 때문입니다. 관습적으로 이름을 붙이긴 하지만 제대로 된 이름을 붙이지는 않습니다(?). 매개변수가 있는 유형을 재사용하려면 다음과 같이 이름을 지정해야 합니다.
[오디오 컷오프]
Alright, brittleness and coupling, this is another thing that's just my personal experience that (?) static type systems yield much more heavily coupled systems. And that a big part of that time aspect of the final diagram of what problem we're trying to solve, is dominated by coupling when you're trying to do maintenance, right? Flowing type information is a major source of coupling in programs. Having a de-, you know, pattern matching of a structural representation in a hundred places in your program is coupling, right? Like, this stuff I'm siezing up when I see that the sensibilities you get after 20 years of programming, you hate coupling. It's like the worst thing and you smell it coming and you want no part of it. And this is a big problem.
The other thing I think is more subtle, but I put it here because unless you see this, is positional semantics don't scale. What's an example of positional semantics? Argument lists, right? Most languages have them (?), and Clojure has some too, right? Who wants to call a function with 17 arguments? Nope.
[audience laughter]
There's one in every room.
[audience laughter]
Nobody does, we all know it breaks down. Where's it break down? Five, six, seven? At some point, we're no longer happy. But if that's all you have, right, if you only have product types, they're going to break down every time you hit that limit, right? How many people like going to the doctor's office and filling out the forms, right? Don't you hate it? You get this big lined sheet of paper that's blank, then you get this set of rules, that says, "put your social security on line 42, and your name on line 17", that's how it works, right? That's how the world works, that's how we talk to other people? No! It doesn't scale. It's not what we do. We always put the labels right next to the stuff and the labels matter, but with positional semantics we're saying, "no, they don't matter (?) just (?) remember the third mean this and the seventh thing means that".
And types don't help you, right? They don't really distinguish this, float x, float x, float x, float x, float...at a certain point it's not telling you anything. So they (?) don't scale but they...it occurs in other places, so we have argument lists, we have product types, where else? Parameterization, right? Who's seen the generic type with more than 7 type arguments? Or see (?) it (?) in C++ or Java, yeah, we tend not to see it in Java because people give up on parameterization, right?
[audience laughter]
And what do they switch to? Spring!
[audience laughter]
No, I mean, that's not a joke, it's just a fact, right? They switched to a more dynamic system for injection, right? Because parameterization doesn't scale and (?) one of the reasons why it doesn't scale is there are no labels on these parameters. They may get names by convention, but they're not properly named (?). When you want to reuse the type with parameters, you get to give them names
[audio cut off]
(?)를 다시 입력합니다. 패턴 매칭에서처럼요. 끔찍하네요. 끔찍한 생각입니다. 그리고 확장성도 없습니다. 따라서 매개변수나 위치 정보만으로는 결국 한계에 부딪히게 될 것입니다. 사람들과 대화할 수 있는 능력이 부족해지거나 사람들이 여러분이 하는 일을 이해할 수 있는 능력이 부족해지겠죠. 그래서 저는 유형이 프로그램 유지 관리와 확장성을 위한 안티 패턴이라고 생각합니다. 유형은 이러한 결합을 도입하기 때문에 프로그램을 유지 관리하기 어렵게 만들고 애초에 이해하기 더 어렵게 만듭니다.
그래서 클로저는 동적으로 타이핑됩니다. 이러한 증명 부담이 없습니다. 내가 여기서 무언가를 만들었고 저쪽에서 누군가가 관심을 갖고 있기 때문에 중간에 있는 모든 사람이 그것을 건드리지 않았다는 것을 증명할 필요가 없습니다. 대부분 건드리지 않죠. 우리가 무엇을 보호하고 있는지는 모르겠지만, 저쪽에는 여전히 줄이 있다는 것을 증명할 수 있습니다.
구조체는 개방되어 있죠? 저희는 다중 메서드나 프로토콜을 통한 런타임 다형성이나 명령문 전환, 패턴 매칭 등을 훨씬 더 선호합니다.
맵(지도)은 열려 있습니다. 반드시 알아야 합니다. 모르는 것이 있으면 클로저에서는 어떻게 해야 할까요? 그냥 빼버리면 됩니다. 모르는 거죠. 이것이 아닐 수도 있고 저것이 아닐 수도 있습니다. 실제로 정보 시스템을 매개변수화했다면 모든 것이 그럴 수도 있습니다. MayBe 모든 것은 더 이상 의미가 없으며 단지 그렇지 않을 뿐입니다. 그리고 메이비 썸머 타입의 어떤 것도 존재하지 않죠? 주민등록번호가 문자열이라면 그것은 문자열입니다. 여러분은 그것을 알거나 모르거나 둘 중 하나입니다. 이 두 가지를 섞는 건 말이 안 돼요. 그런 게 아니에요. 현관문 프로토콜의 일부일 수도 있고, 필요할 수도 있고 아닐 수도 있지만(?) 그런 종류의 것은 아닙니다. 그래서 지도는 열려 있습니다. 꼭 필요한 것만 알려드리고 나머지는 여러분이 전파하는 습관을 들이면 됩니다. 물건을 더 건네주실 수도 있는데 제가 신경 써야 하나요? 아니요. UPS 트럭이 왔는데 트럭에 내 TV가 실려 있는데 트럭에 다른 물건이 뭐가 있든 신경 써야 하나요? 아니요, 알고 싶지 않아요. 하지만 다른 물건이 있어도 괜찮아요.
(?) again. Just like in pattern matching. That's terrible. That's a terrible idea. And it does not scale. So anywhere parameters, anywhere positionality is the only thing you've got, you're eventually goning to run out of steam. You're going to run out of the ability to talk to people or they're going to run out of the ability to understand what you're doing. So I think types are an anti-pattern for program maintenance and for extensibility. And because they introduce this coupling and it makes programs harder to maintain and even harder to undersand in the first place.
So Clojure is dynamically typed. You do not have this burden of proof. You don't have to prove that, you know, because I made something here and somebody cares about it over there, every person in the middle didn't mess with it. You know, mostly they don't mess with it. I don't know what we're protecting against, but we can prove now that, you know, they're still strings over there.
The constructs are open, right? We much prefer runtime polymorphism either by multi-methods or protocols to switch statements, pattern matching, and things like that.
The maps are open. They're need-to-know. What do we do in Clojure if we don't know something? We just leave it out. We don't know it. There's no MayBe this MayBe that. If you actually parameterized the information system, it would be MayBe everything. MayBe everything no longer is meaningful, it just isn't. And nothing is of type MayBe something, right? If your social security number is a string, it's a string. You either know it or you don't. Jamming those two things together, it makes no sense. It's not the type of the thing. It may be part of your front-door protocol, that you may need it or not, but (?) it's not the type of the thing. So the maps are open. We deal with them on a need-to-know basis and you get into the habit of propagating the rest. May be you handed me more stuff, should I care? No. The UPS truck comes and my TV is on the truck, do I care what else is on the truck? No. I don't want to know. But it's ok that there's other stuff.
# Language Model Complexity

또 다른 문제는 언어 모델의 복잡성입니다. C++는 매우 복잡한 언어이고 하스켈도 그렇고 자바도 그렇고 대부분의 언어가 그렇죠. 클로저는 매우 작습니다. Scheme만큼 작지는 않지만 다른 언어에 비해서는 작습니다. 그리고 기본적인 람다 미적분학에 불변의 함수 핵심이 있는 것일 뿐입니다. 함수가 있고, 값이 있고, 값에 함수를 호출하고 다른 값을 얻을 수 있습니다. 그게 다입니다. 계층 구조도 없고, 매개변수화도 없고, 실존 유형도 없고, 어쩌고저쩌고 하는 것도 없습니다.
그리고 실행 모델도 까다롭죠? Java에서도 프로그램의 성능을 추론하기가 점점 더 어려워지는 시점에 도달하고 있죠? 리소스 때문이죠. 안타깝게도 C의 좋은 점 중 하나는 프로그램이 충돌하는 경우 문제가 무엇인지 알 수 있고 알아낼 수 있지만 RAM에서 무엇을 차지할지 알 수 있고 계산할 수 있으며 추적하기 쉽다는 점입니다. 프로그래머에게는 이런 점이 중요하죠? 프로그래밍은 수학이 아닙니다. 수학에서는 어떤 동형도 다른 동형으로 바꿀 수 있지만, 프로그래밍에서는 그렇게 하면 해고당하잖아요, 그렇죠?
[청중 웃음]
다르죠. 성능이 중요하고 프로그래밍의 일부이며 큰 문제입니다. 그래서 이걸 만들면 적어도 "자바 같네"라고 말할 수 있고 비난할 수 있죠.
[청중 웃음]
글쎄요(?) 괜찮습니다. 하지만 모든 툴이 도움이 되었다는 뜻이기도 하죠? 모든 자바 도구가 클로저에서 작동하죠. 얼마나 많은 사람들이 Clojure에서 YourKit과 그런 프로파일러를 사용하나요? 그렇게 할 수 있다는 것은 정말 대단한 일이죠.
So the other problem is, you know, language model complexity. You know C++ is a very complex language and so is Haskell and so is Java and so is, well, most of them. Clojure is very small. It's not quite Scheme-small but it's small compared to the others. And it's just, you know, the basic lambda calculus kind of thing with, you know, immutable functional core. There are functions, there are values, you can call functions on values and get other values. That's it. There's no hierarchy, there's no parameterization, there's no, you know, existential types, blah blah blah blah blah.
And the execution model is another tricky thing, right? We're getting to the point even in Java where it gets harder and harder to reason about the performance of our programs, right? Because of resources. And that's unfortunate, you know, at least one of the nice things about C was, you know, you knew if your program crashed if was your problem and you just figure it out but you knew what it was going to take up in RAM and you could calculate things and it was quite tractable. And that matters to programmers, right? Programming is not mathematics. In mathematics you can swap any isomorphism for any other, in programming you get fired for doing that, right?
[audience laughter]
It's different. Performance matters, it's part of programming, it's a big deal. So making this something at least I could say, "it's like Java", and blame them.
[audience laughter]
Well (?) it's fine. But it also meant all the tooling helped us, right? All the, you know, all the Java tooling works for Clojure. I mean how many people use YourKit and profilers like that on Clojure? That's pretty awesome to be able to do that.
# Parochialism - names

좋아요, 이제 제가 마음에 들지 않아서 생략한 것들에 대한 진짜 핵심을 살펴 보겠습니다. 이런 유형은 어디에나 존재하며 제가 생각해낸 이름은 "교구주의"입니다. "나는 이 언어를 가지고 있고, 이 언어에는 대수적 데이터 유형을 사용하여 사물을 생각하는 방법, 상속을 사용하여 사물을 생각하는 방법에 대한 멋진 아이디어가 있다"는 생각입니다. 이렇게 강렬한 교구주의를 낳게 되죠? 사물에 대한 이 언어의 규칙의 맥락에서만 의미가 있고 다른 사람의 아이디어와 결합되지 않는 사물의 표현, 정보의 표현을 가지기 시작하죠? 데이터베이스에 부딪힙니다. 전선에 부딪히고 다른 프로그래밍 언어와도 부딪히게 되는데, 이는 사물에 대해 생각하는 방식에 대한 특유의 지역적 관점을 가지고 있기 때문입니다. RDF는 이를 제대로 해냈습니다. 그리고 그들은 목표가 있었기 때문에 그렇게 했죠? 그들은 무언가를 성취하려고 합니다. 서로 다른 소스의 데이터를 병합할 수 있기를 원하고, 스키마가 의미를 지배하는 것을 원하지 않죠? 같은 회사에서 같은 메일을 받고 "데이터베이스에 무슨 문제가 있는 거죠?"라고 생각한 사람이 얼마나 될까요? 그렇죠. 뭐가 문제일까요? 한 회사가 다른 회사를 인수했기 때문이죠? 이제 같은 회사에서 두 개의 데이터베이스를 갖게 된 거죠. 한 데이터베이스에는 내 이름이 개인 정보에 있고 다른 데이터베이스에는 내 이름이 개인 테이블에 있고 또 다른 데이터베이스에는 내 이름이 메일링 리스트 테이블에 있지 않나요? 메일링 리스트 테이블 이름과 사람 이름이 실제로 같은 정보라는 것을 누가 알 수 있을까요? 아무도 모릅니다. 그들은 회의를 해야 하고, 이것은 큰 돈이고, 큰 티켓 문제입니다. 작은 문제가 아니라... 웃어넘길 문제가 아니죠?
[청중 웃음]
그렇죠? 이러한 대기업들은 이러한 시스템을 병합하기 위해 엄청난 노력을 기울이고 있습니다. 왜냐하면 테이블의 교구성은 클래스 및 대수적 데이터 유형과 동일하기 때문입니다. 같은 문제이지 다른 문제가 아닙니다. 제가 세상을 바라보는 관점을 정하던 날, 저는 이름이 사람의 일부라고 결정했고, 여러분은 이름이 메일링 리스트의 일부라고 결정했습니다. 이제 우리는 이 문제를 해결해야 합니다. 많은 회사들이 이 문제를 어떻게 해결하는지 아십니까? 그들은 세 번째 데이터베이스, 보통 RDF 데이터베이스를 페더레이션 포인트로 도입하여 이제 이 두 가지가 동일하다는 것을 알아낼 수 있습니다. 그리고 결국에는 같은 메일을 두 번 보내는 것을 중단합니다.
자, 이것이 주어, 술어, 목적어이며 이것이 데이터믹에 미치는 영향을 분명히 알 수 있습니다.
Alright, now we're into the real nitty gritty of things I didn't like and therefore I left out. This type thing, it goes everywhere and the name I came up for it is "parochialism", right? This idea that "I have this language, and, you know, it's got this cool idea about how you should think about things, you should think about things using algebraic data types or you should think about things using inheritance". It yields this intense parochialism, right? You start to have representations of things, manifestations of representations of information that they only make sense in the context of this language's rules for things and they don't combine with anybody else's ideas, right? You smash against the database. You smash against the wire. You smash against this other programming language, because you've got this idiosyncratic, local view of how to think about things. RDF did this right. And they did it because they had this objective, right? They're trying to accomplish something. We want to be able to merge data from different sources, we don't want the schemas to dominate the semantics, right? How many people have ever gotten the same piece of mail from the same company and been like, "what is wrong with your databases, dudes?", right? Yeah. What is wrong? What's wrong is, one company bought another company, right? Now they're the same company, they now have these two databases. In one database, your name is in the person thing and in another database your name is in the person table and in another database your name is in the mailing list table, right? Who knows that mailing list table name and person name are actually the same piece of information? Nobody. They have to have meetings, I mean this is a big dollar, this is a big ticket problem. It's not a small...it's not a laughing matter, right?
[audience laughter]
Right? These big companies have giant jobs trying to merge these systems because, because table parochiality, it's the same as classes and algebraic data types. It's the same problem, it's not a different problem. It's all like, I had this view of the world and on the day I decided how the world is I decided that names were parts of person, and you decided that names were parts of mailing lists. And now we need to fix this. And you know how a lot of those companies fix it? They introduce a third database, usually an RDF database as a federation point so they now can figure out these two things are the same. And eventually they will stop sending you two pieces of mail...the same piece of mail twice.
Right, so this is subject, predicate, object and obviously you can see the influence of this on Datomic.
# Parochialism - types and contexts

맞아요, 하지만 더 나아갈 수 있죠? 유형 시스템이 정교할수록 유형이 더 교구적이라고 말할 수 있겠죠? 덜 일반적일수록, 이동성이 떨어지고, 다른 시스템에서 이해하기 어렵고, 재사용성이 떨어지고, 유연성이 떨어지고, 전선 위에 얹기 어렵고, 일반적인 조작의 대상이 되지 않겠죠? 타입을 다루는 거의 모든 다른 언어는 앞서 이야기한 컨테이너의 이러한 횡포를 조장합니다. 클로저에서는 선택의 여지가 있는데, 사람들은 어느 쪽을 선택하겠죠? 하나는 컨테이너가 지배하는 것이고, 다른 하나는 문맥이 의미를 지배하는 개념입니다. 예를 들어, 이 문맥에서 이것을 이 의미라고 불렀으니 저 의미라는 식이죠. 하지만 클로저에는 이름 공간 정규화 키를 사용하는(?) 이보다 더 나은 방법을 사용할 수 있는 레시피가 있습니다. 네임스페이스 정규화 키를 사용하면 이제 데이터를 병합할 수 있고, 데이터가 사용되는 컨텍스트에 관계없이 그 의미를 알 수 있습니다.
그리고 이 모든 것이 앞서 말씀드린 구성을 방해합니다.
특히 나중에 보게 되겠지만, 우리가 이 프로그램-메인퓰레이팅-프로그램 아이디어를 지향하고 있기 때문에 더 어렵게 만듭니다.
Right, but it goes further, right? I would say that the more elaborate your type system is, the more parochial your types are, right? The less general they are, the less transportable they are, the less understandable by other systems they are, the less reusable they are, the less flexible they are, the less amenable to putting over wires that they are, the less subject to generic manipulation that they are, right? Almost every other language that deals with types encourage this tyranny of the container I talked about before. We have a choice in Clojure, I think people go either way, right? There's two things, one is the container dominates, the other is just sort of the notion of context dominating the meaning, like, because I called it this in this context, it means that. But we have the recipe in Clojure for doing better than that, in (?) which you use namespace-qualified keys. With namespace-qualified keys we now can merge data and know what things mean regardless of the context in which they're used.
And anything about this thwarts the composition I talked about before.
And in particular because we're pointed at this program-mainpulating-program idea, as you'll see later, it makes this harder.
# Clojure Names

그래서 클로저에는 일류(?)의 이름들이 있습니다. 이것은 Lisp에 있던 것들입니다. 단지 연관 데이터 유형에 대한 액세스(?)가 되었기 때문에 더 지배적입니다. 그것들은 그 자체로 함수입니다. 키워드가 함수가 되는 것은 일종의 큰 문제입니다.
키워드가 사라지지도 않고, 오프셋으로 컴파일되지도 않으며, 전달할 수 있습니다. 적어두면 되죠. 클로저를 모르는 사용자도 텍스트 파일에 입력해서 저장해두면 클로저를 배우지 않고도 의미 있는(?) 프로그램을 만들 수 있습니다.
우리는 이 네임스페이스 자격을 가지고 있습니다. 안타깝게도 아직 많은 클로저 라이브러리가 따르지 않고 있는 이 역 도메인 이름 체계, 즉 자바 이름과 동일한 규칙을 따르면 모든 클로저 이름은 다른 클로저 이름뿐만 아니라 자바 이름과도 충돌이 없습니다. 이는 환상적으로 좋은 아이디어이며, 이름에 URI를 사용하는 RDF의 아이디어와 유사합니다.
그리고 별칭은 이를 덜 부담스럽게(?) 만드는 데 도움이 됩니다.
So Clojure has names that are (?) first-class. This is, you know, stuff that was in Lisp. It just dominates more because they became the accesses (?) for the associative data type. They are functions in and of themselves. Keywords being functions is sort of the big deal.
They don't disappear, they're not compiled away into offsets, we can pass them around. We can write them down. A user who doesn't know Clojure can actually type one into a text file and save it, and do something meaningful with a (?) program without learning Clojure.
We have this namespace qualification. If you follow the conventions, which unfortunately a lot of Clojure libraries are not yet doing, of this reversed domain name system, which is the same as Java's, all Clojure names are conflict-free not only with other Clojure names, but with Java names. That's a fantastically good idea, and it's similar to the idea in RDF of using URIs for names.
And the aliases help to (?) make this less burdensome.
# Distribution

그리고 최근에 더 많은 일을 하기 위해(?) 몇 가지를 더 했습니다.
그리고 배포 문제가 있습니다. 여기서 제가 "프로그램 설계를 언어별로 바라보는 것은 끔찍한 실수"라고 말하는 이유는 여러분이 그 작은 상자 안에 있기 때문입니다. 여러분은 이 큰 그림을 무시하고 있습니다. 한 발 물러서자마자 이 문제가 발생하면 유선으로 이야기해야 합니다. 원격 객체 기술을 사용하는 사람이 얼마나 되나요? 정말 죄송합니다.
[청중 웃음]
잔인하잖아요, 그렇죠? 아주 잔인하죠. 엄청나게 깨지기 쉽고 깨지기 쉬우며 복잡하고 오류가 발생하기 쉽고 구체적입니다. 자신이 고용하지 않은 사람과 대화할 때 이런 기술을 사용하는 사람이 얼마나 될까요? 아니요, 작동하지 않습니다. 인터넷은 그런 식으로 작동하지 않잖아요? 분산 객체는 실패했죠? 인터넷은 유선을 통해 일반 데이터를 전송하는 것입니다. 그리고 지금까지 유선으로 처리했던 거의 모든 것이 이 방식으로 전환되었을 때만 성공했습니다. 그리고 이것은 매우 성공적이었습니다. 결국 프로그램의 일부 하위 집합의 일부 하위 집합만 표현하면 되는데, 우리가 미리 알지 못했던 하위 집합을 유선을 통해 표현해야 한다면 왜 이렇게 매우 복잡한 방식으로 프로그래밍해야 할까요? 우리가 항상 이런 식으로 프로그램 내부를 "데이터 구조를 전달하자"라고 프로그래밍하는데, 누군가 "아, 프로그램의 절반을 와이어를 통해 전달하거나 6대의 머신에 복제할 수 있으면 좋겠어요"라고 말하면 클로저에서는 뭐라고 말해야 할까요? 잘됐네요, 소켓을 통해 일부 edn을 전송하기 시작하면 끝입니다. 반대로, 모든 것을 다시 해야 합니다.
And we've (?) done some more recently to (?) do more with that.
Then there's this distribution problem. And here's where I start saying, "taking a language-specific view of program design is a terrible mistake", because you're in that little box. You're ignoring this big picture. As soon as you step back, now you have this problem, you have to talk over wires. How many people use, you know, remote object technology? I'm really sorry.
[audience laughter]
Cuz it's brutal, right? It's very brutal. It's incredbilty brittle and fragile and complex and error-prone and specific. How many people use that kind of technology to talk to people not under their own employ? No, it doesn't work. That's not how the Internet works, right? Distributed objects failed, right? The Internet is about sending plain data over wires. And almost everything that ever dealt with wires only succeeded when it moved to this. And this is very successful. Why should we program in a way that's all super-parochial if we only need to eventually represent some subset of a portion of some subset of a program, may be a subset we didn't know in advance, over wires, right? If we program this way all the time, we program the inside of our programs as "let's pass around data structures", and then somebody says, "oh, I wish I could put half of your program across a wire, or replicated over six machines", what do we say in Clojure? That's great, I'll start shipping some edn across a socket and we're done. As opposed to, you gotta do everything over.
# Runtime tangibility

그래서 런타임에 대한 영감과 예제(?)가 많았는데, C++에서 커먼 리스프를 배울 때 정말 흥미로웠던 것 중 하나가 바로 이 런타임의 실체성입니다. 스몰토크와 커먼 리스프는 분명 사람을 위한 프로그램을 작성하고자 하는 사람들이 만든 언어입니다. 이들은 언어 이론가가 아닙니다. 그들은 글을 쓰고, GUI를 작성하고, 데이터베이스를 작성하고, 논리 프로그램과 언어도 작성했습니다. 하지만 스몰토크와 커먼 리스프에는 부인할 수 없는 시스템 감성이 있습니다. 특히 저처럼 뒤늦게 발견했을 때 그 감성은 정말 놀랍습니다. 그리고 이것은 학계에서 거의 사라진 전통이라고 생각합니다. 같은 사람들이 시스템과 언어를 함께 만드는 경우는 거의 없으니까요. 이 언어들에서 훔쳐갈 수 있는 것이 아직 많이 남아 있기 때문에 정말 안타까운 일이죠. 이 언어들은 매우 실체적인 것이었죠? 환경이 통합되어 있었고, 모든 이름을 볼 수 있었고, 돌아가서 코드를 찾을 수 있었고, 네임스페이스가 확실했고, 런타임에 코드를 로드할 수 있었죠. 한 가지씩 한 가지씩 발전해 나갔죠? "충분히 큰 C 또는 C++ 프로그램에는 Common Lisp가 제대로 구현되어 있지 않다"는 오래된 Perlis의 말은 정말 사실입니다. **다시 말하지만, 스프링이죠? 시간이 지남에 따라 더 큰 시스템을 유지 관리하고 앞서 설명한 모든 복잡성을 처리하려면 결국 역동성을 원하게 되고, 역동성은 선택 사항이 아니라 반드시 갖춰야 합니다. 역동성은 선택이 아니라 필수입니다. ** 하지만 클로저를 구현하면서 특히 흥미로웠던 점은 런타임에 얼마나 많은 실체와 위치 감각이 JVM 설계에 반영되었는지였습니다. JVM은 실제로 매우 역동적인 존재입니다. 자바가 C#이나 C++처럼 보이는 것과는 달리, JVM은 "이 프로그램을 셋톱박스에 내장하고 네트워크에 연결하여 코드를 보내면 기능을 업데이트할 수 있다"는 생각으로 작성되었기 때문에 어디를 둘러보아도 어디에나 배치되어 있습니다. 그리고 런타임은 이를 위한 수많은 훌륭한 지원을 제공합니다. 그래서 클로저와 같은 언어를 위한 훌륭한 플랫폼입니다. 그리고 다행히도 사람들이 Self에서 했던 작업이 죽지 않고 그대로 이어져 여기까지 이어졌다는 점이 정말 다행입니다. 모든 것이 다 그런 것은 아닙니다. 하지만 이것은 매우 중요하며 누군가가 "그냥 정적 컴파일 기술로 JVM을 대체하자"고 말하는 날은 슬픈 날이 될 것입니다. JVM과 CLR을 타깃으로 삼아 말씀드리자면, CLR은 정적 사고이고 JVM은 동적 사고라는 점은 분명합니다.
So there were plenty of inspirations and examples for me of (?) this runtime tangibility is one of the things I really got excited about when I learned Common Lisp coming from C++. Smalltalk and Common Lisp are languages that were obviously written by people who were trying to write programs for people. These are not language theoreticians. You can tell, they were writing, they were writing GUIs, they were writing databases, they were writing logic programs and languages also. But there's a system sensibility that goes through Smalltalk and Common Lisp that's undeniable. And when you first discover them, especially if you discover them late as I did, it's stunning to see. And I think it's a tradition that's largely been lost in academia. I just don't see the same people making systems AND languages, you know, together. They've (?) sort of split apart and that's really a shame, because there's so much still left to pilfer from these, these languages. They were highly tangible, right? They had reified environments, all the names you could see, you could go back and find the code, the namespaces were tangible, you could load code at runtime. I mean, one thing after another after another, right? And the old Perlis, you know, quip about, you know, "any sufficiently large C or C++ program, you know, has a poorly implemented Common Lisp", is so true. Again, Spring, right? You eventually...as you get a larger system that you want to maintain over time and deal with all those complexities of, you know, that I showed before, you want dynamism, you have to have it, it's not like an optional thing. It's, it's necessary. But was particularly interesting for me in implementing Clojure was how much runtime tangibility and situated sensibilities were in the JVM design. The JVM is actually a very dynamic thing. It's not just Java looks like say, C# or C++, the JVM, you know, it was written with an idea of "well we're going to embed these programs on set top boxes and network them and need to send code around (?) you could update their capabilities", that's like, it's situated everywhere you turn. And the runtime has got a ton of excellent support for that. Which makes it a great platform for languages like Clojure. And thank goodness, you know, that the work that the people did on Self, and it didn't die, that it actually got carried through here. Not everything did. But it's quite important and it will be a sad day when, you know, somebody says, "well let's just replace the JVM with, you know, some static compilation technology". And I'll tell you, targeting the JVM and the CLR, it's plain, the CLR is static thinking and the JVM is dynamic thinking.
# Concurrency

그래서 이 모든 것에는 위치 감성이 있습니다.
첫 번째 슬라이드의 마지막 문제는 동시성 문제였는데, 대부분의 동시성 문제는 기본적으로 기능적이고 불변하는 것으로 해결된다고 생각합니다.
So there's situated sensibilities in all of these.
The last problem on my initial slide was concurrency, and I think mostly concurrency gets solved by being functional and immutable by default.
또 한 가지 필요한 것은 상태 전환을 처리할 수 있는 방법과 언어가 필요하다는 것입니다. 이것이 바로 획기적인 시간 모델입니다. 여기서 다시 설명하지는 않겠지만 이전에 이에 대해 강연한 적이 있습니다. 그래서 클로저에는 이런 기능이 있습니다. 이 모든 것이 합쳐져서 "친구에게 합리적인 답을 찾은 것 같아요"라고 말할 수 있게 해줬죠. 그가 "이걸로 어떻게 실제 프로그램을 작성할 수 있을까요?"라고 묻는다면, 저는 "멀티 스레드 프로그램을 포함해 실제 프로그램을 작성하고 미치지 않는 방법은 다음과 같습니다."라고 말할 수 있습니다.
The other thing you need, is you need some way to, some language for dealing with state transitions. And that's the epochal time model. I'm obviously not going to get into this again here, but I've given talks about this before. So Clojure has this. And it was a combination of those things that let me say, "I think I have a reasonable answer for my friend". If he says, "how can I write a real program with this?", I can say, "here's how you can write a real program, including a multi-threaded program and not go crazy".
# Lisp - the good parts

그래서 제가 Lisp에서 가져오고 싶었던(?) 것들이 많았고, 이런 것들에 대해 많이 이야기했던 것 같습니다. 동적이고, 작고, 일류 이름을 가지고 있고, 매우 유형적이며, 코드가 데이터이고, 읽기/프린트가 있는데, 이에 대해 조금 더 이야기하려고 합니다.
So there's lots of stuff I've wanted to (?) take from Lisp, and I think I talked about a lot of these. It's dynamic, it's small, it had first-class names, it's very tangible, there's this code is data, and read/print, and I'm going to talk a little bit more about that.

하지만 REPL이 있잖아요. 아직도 많은 사람들이 "REPL은 다양한 시도를 할 수 있어서 멋지다"라고 말하는데, 그건 사실이지만 REPL은 그보다 훨씬 더 멋지다고 생각합니다. 약어이기 때문에 그보다 더 멋지고 읽기 자체가 그 자체로 멋지다는 점에서 더 멋집니다. 그리고 클로저는 더 풍부한 데이터 구조 세트를 추가함으로써 읽기/프린트를 강력한 기능으로 만들었습니다. 단순히 편리함이나 사람들과 상호 작용하는 방법, 프로그램을 쉽게 스트리밍하거나 프로그램 조각을 쉽게 만들 수 있는 방법만이 아닙니다. 이제는 "여기 무료 유선 프로토콜이 있습니다"라고 말하는 것과 같습니다. 얼마나 많은 사람들이 유선으로 EDN을 전송했나요? 네. 가능하지 않다고 생각할 필요 없이 그냥 할 수 있다는 사실에 얼마나 많은 사람들이 좋아하나요? 그리고 다른 것으로 바꾸고 싶으면 바꿀 수 있죠. 하지만 큰 문제입니다.
데이터에서 코드로 전환할 수 있고 매크로의 근원이기도 하지만, 다시 한 번 말씀드리지만 매크로의 응용보다 훨씬 더 크다고 생각합니다.
마지막으로 다른 방향인 인쇄가 있습니다.
But there's the REPL. And I think that still people are like, "the REPL's cool cuz I get to try things", and that's true but the REPL is much cooler than that. It's cooler than that because it's an acronym and it's cooler than that because read is its own thing. And what Clojure did by adding a richer set of data structures, is it made read/print into a super power. It wasn't just a convenience, it isn't just a way to interact with people, it isn't just a way to make it easy to stream programs around or program fragments around. It's now like, "here's your free wire protocol", for real stuff. How many people ever sent edn over wire? Yeah. How many people like the fact that like they don't need to think that's a possibility, they can just do it? And, you know, if you want to switch to something else you can. But it's a huge deal.
Eval obviously we know, it lets us go from data to code and that's the source of macros, but I think again, it's much bigger than the application to macros.
And finally there's print which is just the other direction.

하지만 제 생각에 Lisp에는 고쳐야 할 점이 많았습니다. 더 많은 추상화와 CLOS 등의 설계는 대부분 기반 위에 만들어졌기 때문입니다. 언더파운딩은 이를 활용하지 않았기 때문에 하단에서 다형성을 원한다면 다시 개조해야 합니다. 코어에서 불변성을 원한다면 처음부터 다른 무언가가 필요합니다. 그렇기 때문에 클로저를 커먼 리스프용 라이브러리로 사용하는 대신 클로저를 사용할 가치가 있었습니다. 리스프는 대부분 관습에 따라 기능적인 종류였습니다. 하지만 다른 데이터 구조는 그렇지 않았고, 목록에서 적절한 해시 테이블로 전환하려면 기어를 바꿔야 했습니다. 그리고 목록은 정말 형편없는 데이터 구조입니다. 매우 약해서 프로그래밍의 기본 원리로 사용할 이유가 없습니다. 또한 패키지와 인턴십은 매우 복잡했습니다.
But Lisp had a bunch of things that needed to be fixed in my opinion. It was built on concretions, you know, a lot of the design of more abstractions and CLOS and stuff like that came after the underpinnings. The underpinnings didn't take advantage of them so if you want polymorphism at the bottom, you have to retrofit it. If you want immutability at the core, you just need to, you need something different to, you know, from the ground up. And that's why Clojure was worth doing as opposed to trying to do Clojure as a library for Common Lisp. The Lisps were functional kind of, mostly by convention. But the other data structures were not, you had to switch gears to go from, you know, assoc with lists to, you know, a proper hash table. And lists are crappy data structures, sorry, they just are. They're very weak, and there's no reason to use them as a fundamental primitive for programming. Also packages and interning were very complex there.

클로저에서 중요한 또 다른 부분은 레버리지입니다.
시간이 부족하네요. 그 얘기는 하지 않겠습니다.
The other part about Clojure that is important is leverage.
Oh I'm running out of time. I'm not going to talk about that.

또는 그것도.
Or that.

따라서 edn 데이터 모델은 클로저의 작은 부분이 아니라 클로저의 핵심이라고 할 수 있죠? 이러한 많은 문제에 대한 해답입니다. 유형화되어 있고, 유선을 통해 작동하며, 다른 세계와 호환되지 않습니다. 다른 언어에도 지도가 있나요? 연관 데이터 구조와 벡터, 문자열과 숫자가 있나요? 그래서 영어는 행복한 공용어처럼 보이죠. 그렇다면 프로그램에서 공용어를 사용하면 안 되는 이유는 무엇일까요? 왜 다른 언어를 사용해야 하나요? 사실 그다지 나은 것도 아니고 계속 번역을 해야 하죠.
So the edn data model is not like a small part of Clojure, it's sort of the heart of Clojure, right? It's the answer to many of these problems. It's tangible, it works over wires, it's not incompatible with the rest of the world. Do other languages have maps? Associative data structures and vectors and strings and numbers? So it seems like a happy, you know, lingua franca. And why shouldn't we use the lingua franca in a program? Why should we have, you know, a different, a different language. It's actually not that much better and you have to keep translating.
# Static Types

이제 됐어요. 마지막으로 한 가지 더 있습니다.
Alright. Here's the final thing.

사이먼 페이튼 존스는 훌륭한 강연 시리즈에서 타입의 이러한 장점을 나열했습니다. 클로저의 가장 큰 장점은 바로 타입이 없다는 점입니다. 유형은 특정 유형의 오류가 없음을 보장하며, 이는 사실입니다. 그리고 그는 정적 타이핑의 이점이 "이것이 가장 적다"고 말할 것입니다. 정적 타입은 부분적인 기계 검사 사양의 역할을 하며 여기서 '부분적'이라는 단어는 매우 중요한 단어입니다. 매우 부분적입니다. 정적 타입은 디자인 언어잖아요? 문제를 생각할 수 있는 프레임워크를 통해 사고하는 데 도움을 줍니다. 인텔리센스 같은 대화형 개발을 지원합니다. 하지만 가장 큰 장점은 소프트웨어 유지 관리에 있습니다.
Simon Peyton Jones, in an excellent series of talks, listed these advantages of types. Cuz this is the big thing that's left out of Clojure, there's no types. They guarantee the absence of certain types of errors, which is true. And he would say, he does say, "this is the least benefit" of static typing. They serve as a partial machine-checked specification and "partial" is the operative word here. It's very partial. They're a design language, right? They help you think, you have a framework in which you can think about your problems. They support interactive development like IntelliSense. But the biggest merit is in software maintenance.
# But...

그리고 저는 이 중 많은 부분에 동의하지 않습니다. 제 경험은 그렇지 않았습니다. 가장 큰 오류는 이러한 유형의 시스템으로 포착되지 않습니다. 실제 효과를 확인하려면 광범위한 테스트가 필요합니다. 이름은 의미론을 지배하며, A에서 A로, A의 목록에서 A의 목록으로, 아무 의미도 없고 아무 것도 알려주지 않습니다. '역'이라는 단어를 제거하면 아무것도 알 수 없습니다. 그리고 이것을 "아, 이게 중요한 거야, 이 모든 속성을 가지고 있어"라고 말하는 것은 사실이 아닙니다. a의 목록을 받아 a의 목록을 반환하는 함수는 수천 개가 있는데, 그게 무슨 뜻일까요? 아무 의미도 없습니다. 그리고 확인해보면... 만약 a-s의 목록만 있다면 어디에서 다른 것을 반환할 수 있을까요? 다른 곳에서 무언가를 가져오는 것이 아니라면 당연히 a-s 목록을 반환할 것이고, 기능적이라면 그렇지 않을 것입니다. 얼마나 많은 사람이 UML을 좋아하나요? UML 다이어그램 도구를 사용해 본 사람이 얼마나 될까요? 그렇죠? 재미없죠? "안 돼, 저것과 저것을 연결하면 안 돼", "안 돼, 저런 화살표를 사용해야 해", "안 돼, 이렇게 하면 안 돼", "안 돼, 이렇게 하면 안 돼..."처럼 끔찍하죠. 옴니그래플이 훨씬 낫습니다. 원하는 대로 그리세요. 무슨 생각하세요? 그려봐요. 뭐가 중요해? 그걸 적어. 그게 작동하는 방식이죠? 네, IntelliSense는 정적 유형과 성능 최적화에 많은 도움을 받았는데, 그가 나열하지는 않았지만 이것이 가장 큰 장점 중 하나라고 생각합니다. C++에서도 이 기능이 마음에 들었습니다. 그리고 유지 관리에 대해서는 그렇지 않다고 생각합니다. 이제는 타입을 사용해 문제를 해결하고 있다고 생각합니다. 아, 이걸 500군데 패턴 매칭했는데 중간에 다른 걸 추가하고 싶어요. 다행히도 그 500곳을 찾을 수 있는 유형이 있어서 다행이죠. 하지만 사실 제가 추가한 것은 그것을 소비하는 새로운 코드를 제외하고는 아무도 신경 쓰지 않았어야 했고, 다른 방식으로 했다면 생산자와 소비자 외에는 아무것도 변경할 필요가 없었을 것입니다. 새롭습니다.
And I really disagree just a lot of this. It's not been my experience. The biggest errors are not caught by these type systems. You need extensive testing to do real-world effectiveness checking. Names dominate semantics, a to a, list of a to list of a, it means nothing, it tells you nothing. If you take away the word "reverse", you don't know anything, you really don't. And to elevate this to say, "oh this is important thing, we have all these properties", it's not true, it just isn't true. There are thousands of functions that take a list of a and return a list of a. What does that mean? It means nothing. And checking it...I mean, if you only had a list of a-s, where you gonna get something else to return? I mean, obviously you're going to return a list of a-s, unless you're, you know, getting stuff from somewhere else, and if you're functional, you're not. How many people like UML? How many people have ever used a UML diagramming tool? Right? It's not fun, right? It's like, "no, you can't connect that to that", "oh no, you have to use that kind of arrow", "no, you can't do this", "no, you can't...", it's terrible. OmniGraffle is much better, draw whatever you want. What are you thinking about? Draw that. What's important? Write that down. That's how it should work, right? Yes, IntelliSense is much helped by static types and performance optimization, which he didn't list, but I think is one of the biggest benefits. We loved that in C++. And maintenance, I think it's not true. I think that they've created problems that they now use types to solve. Oh, I pattern-matched this thing 500 places and I want to add another thing in the middle. Well thank goodness I have types to find those 500 places. But the fact was that thing I added, nobody should have cared about except the new code that consumed it and if I did that a different way I wouldn't have had to change anything except the producer and the consumer, not everybody else who couldn't possibly know about it, right? It's new.

젊은 프로그래머들은 다들 지치고 늙어서 더 이상 이런 건 중요하지 않죠. 하지만 제가 젊었을 때는 정말, 젊을 때는 여유가 많았어요. 예전에는 '머리가 텅 비었다'고 말하곤 했는데 그건 옳지 않아요. 여유 공간이 많으니 원하는 것으로 채울 수 있죠. 엔도르핀의 관점에서 보면 퍼즐을 푸는 것과 문제를 푸는 것은 똑같고, 같은 쾌감을 주기 때문에 이런 유형의 시스템은 꽤 재미있어요. 퍼즐을 푸는 것은 정말 멋집니다.
So I mean for young programmers, if everybody's tired and old, this doesn't matter any more. But when I was young, when I was young, I really, you know, when you're young you've got lots of free space. I used to say "an empty head", but that's not right. You've got a lot of free space available and you can fill it with whatever you like. And these type systems they're quite fun, because from an endorphin standpoint solving puzzles and solving problems is the same, it gives you the same rush. Puzzle solving is really cool.
# Spec

하지만 그게 전부는 아닙니다.
저는 이런 종류의 검증이 매우 중요하다고 생각하지만 단품으로 제공되어야 한다고 생각합니다. 필요한 것에 따라, 지출해야하는 금액에 따라, 표현하고 싶은 것에 따라 다양한 종류의 검증 기술을 선반에서 꺼내서 적용 할 수 있어야합니다. 내장되어서는 안 되겠죠? 다양한 요구가 있고, 다양한 접근 방식이 있으며, 비용도 다양합니다. 또한 이러한 도구가 언어적 편협함이 아닌 시스템 수준의 문제를 지적할 수 있는 정도까지만 사용한다면 투자 대비 더 많은 효과를 얻을 수 있다고 생각합니다. 와이어 프로토콜을 지정하기 위해 스펙을 사용해본 사람이 얼마나 되나요? 네. 앞으로 더 많은 일이 벌어질 겁니다. 사양에 대해서는 더 이상 말씀드리지 않겠지만, 다음 버전에서는 프로그래밍 기능이 향상될 것입니다.
But that's not what it should be about.
I think that this kind of verification what-not, it's incredibly important, but it should be à la carte, right? Depending on what you need to, depending on the amount of money you have to spend, depending on what you want to express, you should be able to pull different kinds of verification technology off the shelf, and apply it. It should not be built in, right? There's a diversity of needs, there's a diversity of approaches of doing it, and a diversity of costs. In addition, I think to the extent these tools can be pointed at the system level problem and not some language parochialism, you get more bang for your buck, right? How many people have used spec to spec a wire protocol? Yeah. There's going to be a lot more of that going on. And I won't talk much more about spec, but the next version will increase programmability.
# Information vs Logic

마지막으로 정보 대 논리입니다. 결론은 "우리가 프로그래밍에서 어디로 가고 있는가?"입니다. 사실 우리는 자동차를 운전하는 방법을 잘 모릅니다. 자동차를 운전하는 방법을 설명할 수 없습니다. 바둑을 두는 방법도 설명할 수 없습니다. 그러니 기존의 논리를 인코딩에 적용하여 이를 성공적으로 수행하는 프로그램을 만들 수도 없습니다. 그냥 할 수 없습니다. 우리는 지금 어떻게 해야 할지 모르는 프로그래밍 문제에 접근하고 있습니다. 어떻게 해야 하는지 설명할 방법이 없습니다. 자동차를 운전하는 방법은 알지만 어떻게 운전해야 하는지 설명할 방법을 모르는 것과 마찬가지입니다. 그래서 우리는 정보로 훈련된 두뇌로 이동하고 있는 것이죠? 딥러닝과 머신러닝, 통계 모델 등이 바로 그것입니다. 정보를 사용하여 부정확성과 추측으로 가득 찬 모델을 구동하지만, 작동 방식을 반드시 설명할 수는 없지만 적절한 결정을 내릴 수 있도록 훈련하는 데 사용된 데이터의 양이 많기 때문에 여전히 효과적입니다. 하지만 이러한 프로그램에도 팔과 다리, 눈이 필요하겠죠? 대규모 딥 러닝 네트워크를 학습시킬 때 자체 데이터를 가져올 수 있을까요? 자체 ETL을 수행하나요? 아니요, 그렇죠? 그런 일은 전혀 하지 않습니다. 무엇을 해야 할지 결정이 내려지면 어떻게 실행할까요? 스카이넷에 도착하면 더 이상 문제가 되지 않을 겁니다.
[청중 웃음]
하지만 지금은 문제입니다. 그리고 저는 그 자체로 프로그래밍이 가능한 프로그래밍 언어로 작업하는 것이 매우 중요하다고 생각합니다. 다른 프로그램에서 조작할 수 있잖아요? 클로저를 사용해 글을 쓰면서 두뇌를 키우는 것도 재미있을 거예요. 하지만 정보 조작과 준비에 클로저를 사용할 수 있을 뿐만 아니라 클로저 프로그램과 프로그램 구성 요소를 이러한 의사 결정의 실행 대상으로 사용할 수 있는 것도 유용할 것입니다. 결국 실제 안전은 경험에서 나오는 것이지 증명에서 나오는 것이 아닙니다. 무대에 올라가서 타입 시스템이 안전한 시스템을 만들어낸다는 말을 하는 사람이 있는데, 여기서 '안전'은 실제 세계를 의미하나요? 그건 사실이 아닙니다.
So finally, Information vs Logic. The bottom line is, "where are we going in programming?", right? The fact is, we actually don't know how to drive a car. We can't explain how to drive a car. We can't explain how to play Go. We can't...and then, therefore we can't apply traditional logic to encoding that and make a program that successfully does it. We just can't do it. We're approaching problems in programming now that we don't know how to do. We don't know how to explain how to do. Like, we know how to drive a car, but we don't know how to explain how to drive a car. And so we're moving to these information-trained brains, right? Deep learning and machine learning, statistical models and things like that. You use information to drive a model that's full of imprecision and speculation but that is still effective because of the amount of data that was used to train it at making decent decisions, even though it also couldn't explain necessarily how it works. These programs though are going to need arms and legs and eyes, right? When you train a big deep learning network, does it get its own data? Does it do its own ETL? No. Right? It doesn't do any of that. When it's made a decision about what to do, how's it going to do it? Well, when we get to Skynet, it won't be our problem anymore.
[audience laughter]
But for right now, it is. And I think it's quite critical to be working in a programming language that is itself programmable. That's amenable to manipulation by other programs, right? It'll be fun to use Clojure to write, you know, to do brain building. But it'll also be useful to be able to use Clojure for information manipulation and preparation as well as use Clojure programs and program components as the targets of action of these decision-making things. In the end real-world safety is going to come from experience, it's not going to come from proof. Anybody who gets on stage and makes some statement about type systems yielding safe systems where "safe" mean real-world? That is not true.
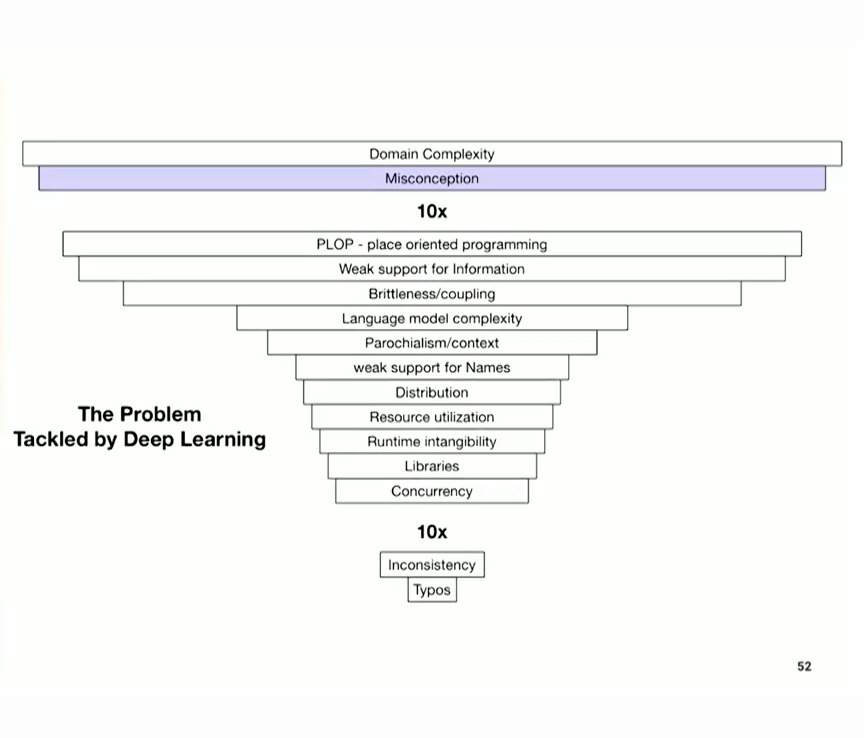
그래서 이것이 정말 흥미로운 부분입니다. 딥 러닝과 이와 같은 기술들은 10배 이상, 그 상위 10배를 넘어서서 오해의 문제를 지적하고 있습니다. "우리는 바둑을 두는 방법도 모르고, 자동차를 운전하는 방법도 모르니 어떻게 해야 하는지 알아낼 수 있는 시스템을 만들어 학습시키자, 그렇지 않으면 틀릴 테니까"라고 말하죠.
So, this is what's really interesting. Deep learning and technologies like that are pointed above the line, above that top 10x, they're pointed at the misconception problem. They say, "you know what? you're right, we don't know how to play go, we do not know how to drive a car, let's make a system that could figure out how, and learn it, because otherwise we're just gonna get it wrong".

그래서 저는 우리가 프로그래밍 가능한 프로그램을 작성한다는 점과 클로저가 이에 적합하다는 점을 강조하고 싶습니다. 정보와 강조를 표현하는 일반적인 방법이 있습니다. 타입 체계를 채택하지 않고도 인수를 구성할 수 있는 일반적인 방법이 있지 않습니까? 자동차를 운전하는 것도 어려운데, 모나드까지 이해해야 한다면 그건 불가능할 겁니다. 재정의된 시스템은 동적으로 발견될 수 있으며, 사양과 클로저의 나머지 부분이 재정의되면 다른 시스템이 학습하여 사용할 수 있는 시스템을 만들 수 있는 좋은 방법이라고 생각합니다. 물론 시간이 지남에 따라 프로그램을 개선할 수 있는 능력도 마찬가지입니다.
So, I'm going to emphasize that we write programmable programs and that Clojure is well-suited to that. We have a generic way to represent information and emphasis. We have a generic way to compose arguments without adopting the (?) type system, right? It's hard enough to drive a car, if you have to understand monads too, you're, you know, it's just not going to work. A reified system is subject to dynamic discovery, and I think spec combined with the rest of Clojure being reified is a great way to make systems that other systems can learn about and therefore learn to use. And of course we have the same ability to enhance our programs over time.

따라서 여러분 모두 클로저가 다르다는 사실을 받아들이시길 바랍니다. 증명에 겁먹지 마세요, 그렇죠? 프로그래밍은 해결된 문제가 아니니까요. 논리는 도구일 뿐이지 주인이 되어서는 안 되며, 논리 체계가 잘 작동한다고 해서 그 밑에 깔려서는 안 됩니다. 시스템 수준에서 설계하라고 말씀드리는 거죠? 프로그래밍 언어가 전부는 아닙니다. 우리 모두는 프로그래밍 언어에 열광하죠. 하지만 사실 저는 프로그래밍 언어가 프로그래밍의 핵심이라는 것에 회의적입니다. 프로그래밍 언어가 프로그래밍의 전부라고 생각하지 않아요. 프로그래밍의 원동력은 아니죠. 그리고 새로운 기회를 받아들이세요. 컨퍼런스 기간 동안 딥 러닝에 대한 많은 강연이 있을 예정이니 이를 적극 활용하세요. 프로그래밍 가능한 프로그램을 만들고
So, I would encourage you all to embrace the fact that Clojure is different. Don't be cowed by the proof people, right? It is, it's not a, programming is not a solved problem, ok? Logic should be your tool, it shouldn't be your master, you shouldn't be underneath your logic system when it works out for you. I'm encouraging you to design at the system level, right? It's not all about your programming language. We all get infatuated with our programming languages. But you know what, I'm actually skeptical about programming languages being the key to programming. I don't think they are, they're a small part of programming. They're not, you know, the driver of programming. And embrace these new opportunities. There's going to be a bunch of talks during the conference about Deep Learning and take advantage of them. Make programmable programs and

퍼즐이 아닌 문제를 해결하세요. 감사합니다.
[청중 박수]