# Component 충분한 구조 (Components Just Enough Structure)
- Speaker: Stuart Sierra (opens new window)
- Conference: Clojure/West (opens new window) - March 2014
- Video: https://www.youtube.com/watch?v=13cmHf_kt-Q (opens new window)

저는 스튜어트 시에라입니다. 저는 Cognitect에서 일하고 있으며, 컴포넌트에 대해 이야기하기 위해 이 자리에 섰습니다. 우리 모두 알다시피, 여러분이 작성하고자 하는 모든 소프트웨어 애플리케이션은 이 3계층 아키텍처 패턴에 부합하기 때문입니다.
I'm Stuart Sierra. I work at Cognitect, and I'm here to talk about components, and I'm here to talk about software architecture because, as we all know, every software application you could ever possibly want to write fits into this three layer architectural pattern.
[청중 웃음]
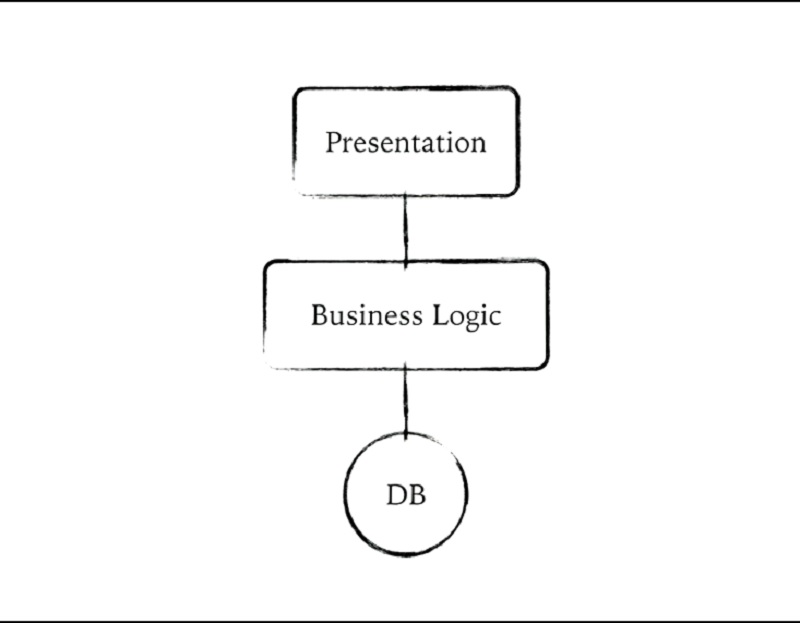
감사합니다. 고마워요. 네, UI가 있죠. 비즈니스 로직이 무엇이든 간에 그 밑에는 데이터베이스가 있습니다. 마지막으로 이런 앱을 만든 게 언제였나요? 그럴 리가 없죠? 네, 제가 작업하는 대부분의 앱은 이와 비슷하게 생겼습니다.
[Audience laughter]
Thank you. Thank you. Yes, you know, you have your UI. You have some business logic, whatever that is, and then a database underneath it all. When was the last time you wrote an app that looked like that? Not likely, huh? Yeah, most of the apps I work on tend to look a little more like this.
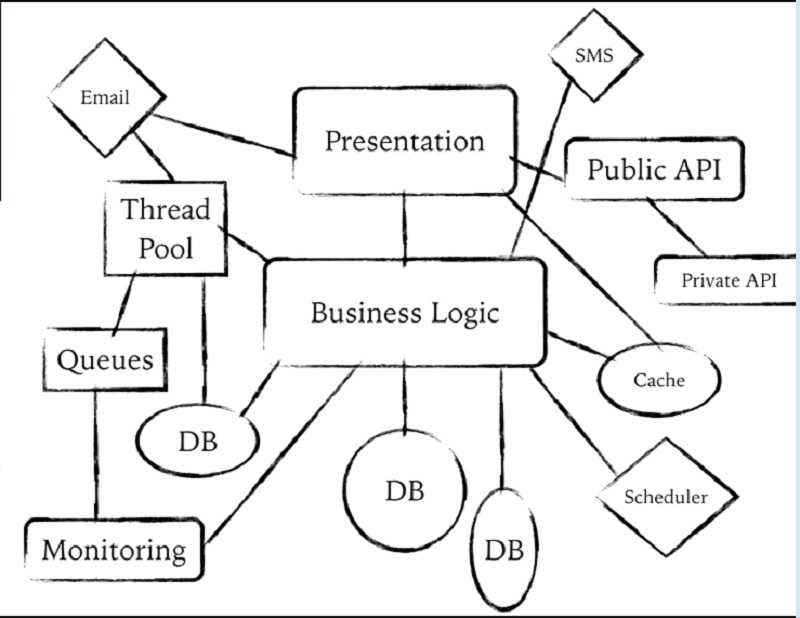
이메일을 보내야 합니다. SMS 메시지도 보내야 하고요. 여기에는 다른 데이터베이스와 데이터 웨어하우스, 스케줄러와 모니터링도 있습니다. 앱은 많은 작업을 수행해야 합니다. 그리고 비즈니스 로직이 조금이라도 있다면 이 모든 요소에 분산되어 있습니다.
You know, they've got to send email. They've got to send SMS messages. There's this other database over here, and a data warehouse, and a scheduler and monitoring. You know, apps have to do a lot of stuff. And if there's any business logic at all, it kind of gets splayed across all of these different pieces.
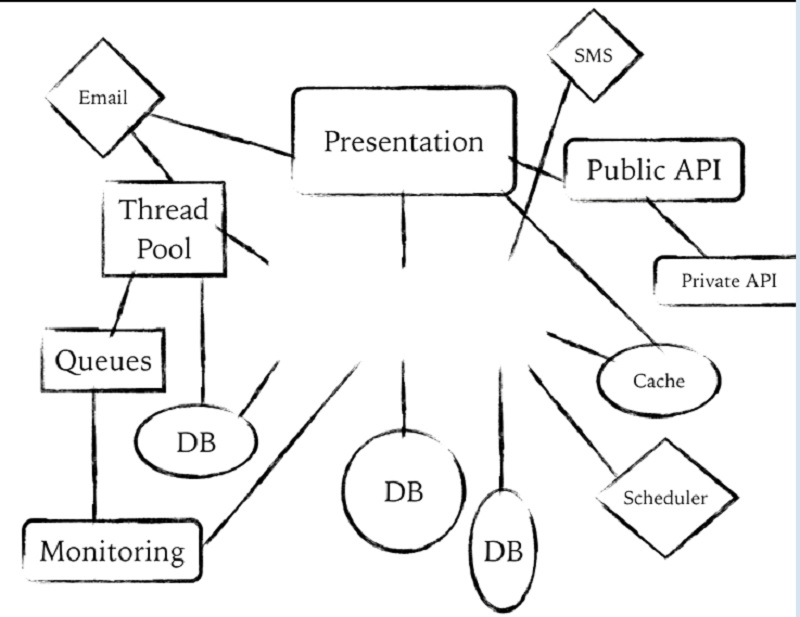
이것이 바로 세상입니다. 이것이 우리가 살고 있고, 우리가 처리해야 하는 것입니다. 그리고 우리 앱의 많은 기능에는 상태가 포함되어 있습니다. 이제 일부는 쉽습니다.
So this is the world. This is what we live with, what we have to deal with. And a lot of these pieces of functionality in our app have state in them. Now some of it's easy.
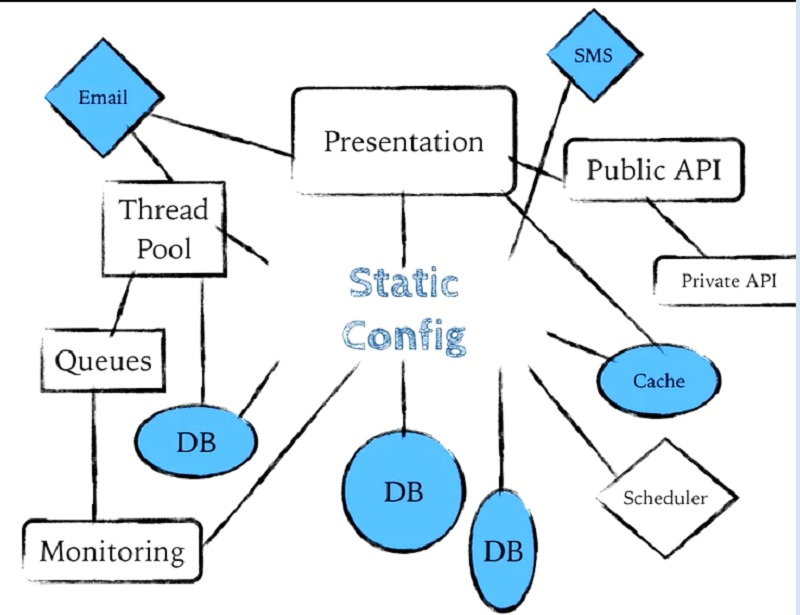
정적 구성일 뿐이지만 데이터베이스 연결 URL, API 키, 사용자 이름, 비밀번호 등 모든 것을 추적해야 합니다.
It's just static configuration, but we have to keep track of things like database connection URLs, API keys, user names, passwords, all that stuff.
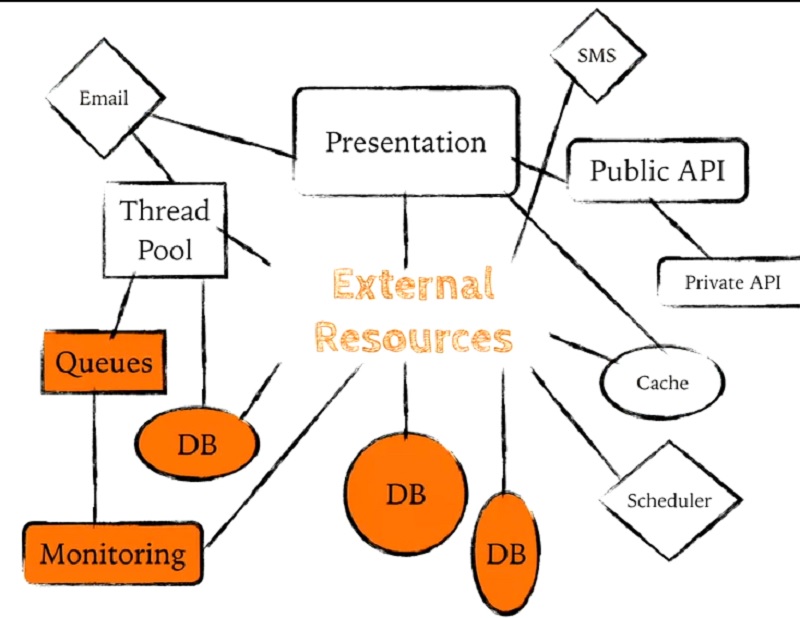
그리고 필요한 외부 리소스가 많이 있습니다. 연결 객체나 세션 객체, 심지어 소켓 연결이나 파일 핸들과 같은 단순한 서비스용 클라이언트 API가 있을 때마다 애플리케이션이 사용하고 추적해야 하는 상태 저장 리소스입니다.
Then we have a lot of external resources that we need. Any time you have a client API for some service that has a connection object or a session object, or even something simple like a socket connection or a file handle, these are all stateful resources that our applications need to use and keep track of.
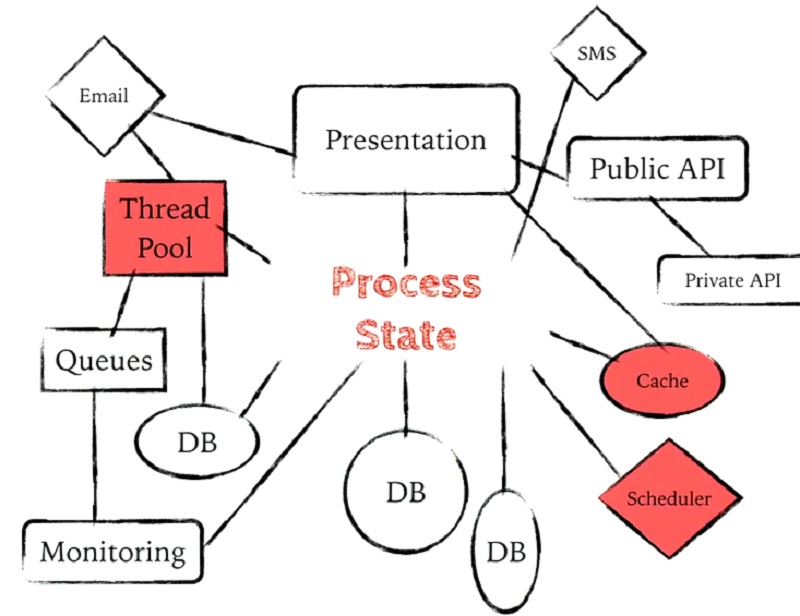
마지막으로, 애플리케이션에서 본질적으로 상태 저장된 것을 가질 수 있습니다. 스레드를 생성할 수 있습니다. 참조, 원자, 에이전트와 같은 변경 가능한 참조 유형을 사용할 수 있습니다. core.async 채널을 사용할 수 있습니다. 우리 프로그램에는 본질적으로 상태 저장성이 있는 것들이 있고, 어딘가에서 그 상태를 추적해야 합니다.
Finally, we can have things that are inherently stateful in our applications. We can create threads. We can use mutable reference types like refs and atoms and agents. We can use core.async channels. We have things in our program that are inherently stateful, and somewhere we have to keep track of that state.

따라서 클로저 프로젝트를 시작할 때마다 직면하게 되는 질문이 있습니다: 어디에 넣을까? 상태는 어디로 갈까요? 저는 이 부분에서 객체 지향 언어가 유리하다고 생각합니다. 객체 지향 언어는 명확하거든요.
So the question that sort of confronts us every time we start a Clojure project is: Where do we put it? Where does the state go? And this is really someplace where I think object oriented languages kind of have the leg up. They make it obvious.

Java와 같은 객체 지향 언어가 있고 어떤 사물이 필요한데 'Foo'가 필요하다면 어떻게 해야 할까요? 클래스를 만들어야 합니다. 그게 당신이 할 수 있는 유일한 일입니다. 그리고 클래스에는 이런 구조가 내장되어 있습니다.
If you have an object oriented language like Java, and you need a thing, you need a Foo, well, what do you do? You make a class. That's the only thing you can do. And a class has this structure built into it.

정적 구성, 런타임 상태를 저장할 수 있는 분명한 장소가 있습니다. 해당 상태를 초기화하는 생성자 함수가 있습니다. 그리고 라이프사이클에서 해당 객체를 여러 상태로 전환하는 메서드가 하나 이상 느슨하게 정의되어 있을 수 있습니다. 따라서 클로저에서는 많은 함수형 언어와는 매우 다른 세계입니다.
You have an obvious place to put static configuration, runtime state. You have a constructor function to initialize that state. And you may have one or more methods loosely defined that are going to transition that object between different states in its lifecycle. So, in Clojure it's a very different world, in a lot of functional languages, actually.

언어에 내재된 구조가 훨씬 적습니다. 여기 이 코드를 이전 슬라이드의 Java 클래스를 매우 순진하게 번역한 것으로 생각하면 됩니다. 비슷해 보이지만 실제로는 매우 다른 일을 하고 있습니다.
There's a lot less structure inherent in the language. If I took this code here as a very naïve translation of the Java class on the previous slide. It looks like it's kind of the same, but it's actually doing something very different.

클로저 네임스페이스는 클래스가 아닙니다. 인스턴스화할 수 없습니다. 네임스페이스의 인스턴스를 만들거나 다른 네임스페이스에 매개변수로 지정할 수 없습니다. 네임스페이스를 그런 식으로 모듈로 취급할 수 없습니다.
그리고 클로저에서는 무언가가 필요한 경우 어떻게 해야 할까요? 정의합니다. 이것이 우리가 Clojure에서 무언가를 만드는 기본 방법입니다. 하지만 우리가 정의하는 모든 것은 글로벌 싱글톤입니다. 그리고 이를 조작하기 위해 작성하는 모든 함수는 원자든 변수든 무엇이든 프로그램 전체에 걸쳐 전역 효과가 됩니다.
작년에 같은 컨퍼런스에서 저는 '대규모의 클로저'라는 강연을 통해 클로저 프로그램에서 이러한 기본 전역 동작으로 인해 발생하는 많은 문제를 설명했습니다. 그 강연에서 저는 모든 함수가 인자로 전달된 것들에만 의존하도록 상태를 로컬로 만들라는 한 가지 큰 권고를 했습니다. 안타깝게도 당시에는 이 방법이 어떻게 작동하는지 완전히 파악하지 못했고, 명확하게 설명하지도 못했습니다.
Clojure namespaces are not classes. They are not instantiable. We cannot create an instance of a name space or parameterize it on another name space. We can't treat name spaces as modules that way.
And, in Clojure, if we need a thing, well, what do we do? We def it. That's the default thing we know how to create stuff in Clojure. But anything we def is a global singleton. And any functions we write to manipulate that, whether it's an atom or a var or whatever, those are going to be global effects throughout our program.
Now, last year at this same conference, I did a talk called Clojure in the Large where I described a lot of the problems that result from this sort of default global behavior in Clojure programs. And I made one big recommendation in that talk, which was to make your state local, to make every function only depend on things that were passed to it in its arguments. Now, unfortunately, I hadn't completely figured out how that would work, and I didn't articulate it very clearly.

그래서 사람들은 결국 애플리케이션의 모든 상태를 하나의 맵으로 통합하는 방법을 사용했습니다. 그런 다음 이 맵을 프로그램의 모든 함수에 인수로 전달했습니다. 오해하지 마세요. 이것은 개선된 것입니다. 이렇게 하면 몇 가지 관리가 더 쉬워집니다. 이제 상태는 적어도 함수에 로컬로 저장됩니다.
So what people ended up doing in response to this was they would have all the state in their application and put it together in one map. And then they would pass that map as an argument to every function in the program. Now don't get me wrong. This was an improvement. This does make some things easier to manage. Now the state is at least local to the function.

하지만 맵을 하나만 만들면 매우 크고 복잡해진다는 문제가 있습니다. 깊게 중첩된 맵이 있고 그 안에 수많은 중첩된 맵과 다른 것들이 있습니다. 그리고 특정 함수에서 필요한 상태 조각을 얻기 위해 여러 레이어를 거쳐야 할 수도 있습니다.
But the problem with having just one of these is that it ends up being very big and complicated. You have this deeply nested map with lots of nested maps and other things inside it. And, in any given function, you may be reaching through several layers of that to get at the piece of state you need.
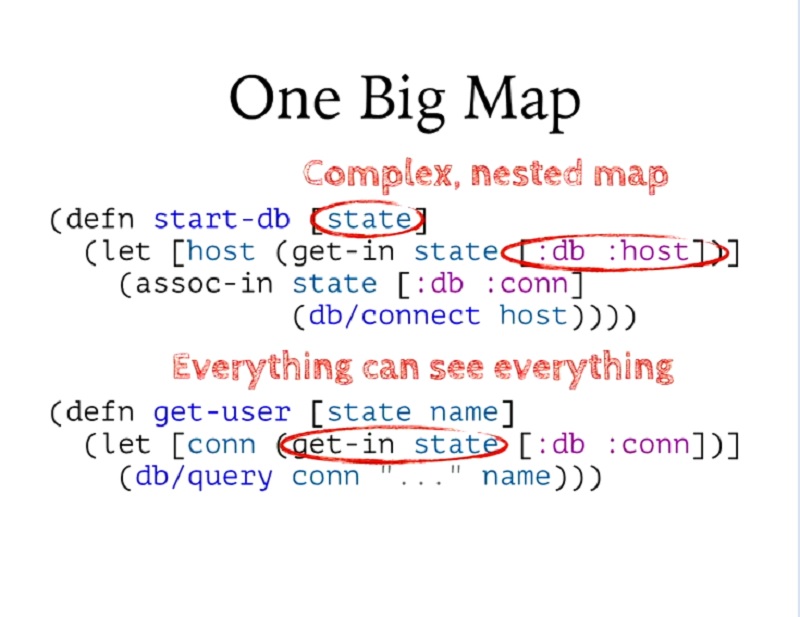
또한 모든 곳에서 동일한 지도를 사용한다면 모든 곳에서 모든 것을 볼 수 있다는 의미이기도 합니다. 모든 상태를 항상 사용할 수 있습니다. 사실상 이것은 글로벌 상태를 재현하는 또 다른 방법일 뿐입니다. 따라서 의도하지 않았는데도 모든 코드가 다른 코드와 매우 긴밀하게 연결되어 있고, 모든 코드가 이 상태를 공유하고 있으며, 어떤 코드가 어딘가에서 이 상태를 조작하고 있을 수 있는 애플리케이션을 만들게 되는 경우가 종종 있습니다.
It also means, if you're using the same map everywhere, that everything can see everything. Every piece of state is always available. Effectively, this is just another way of recreating global state. So what you end up with, often without intending it, is an application where every piece of code is very tightly coupled to every other piece of code because they're all sharing this state, and any piece of code might be manipulating it somewhere.

이 패턴의 또 다른 단점은 동일한 맵을 여러 함수에 전달하여 필요한 상태를 구축할 수 있는 좋은 기능이 있지만, 여전히 순서를 추적해야 한다는 것입니다.
Another downside to this pattern, although it does have this nice feature that you can just sort of pass this same map through a bunch of functions to build up the state that you need to carry around, you still have to keep track of the ordering.
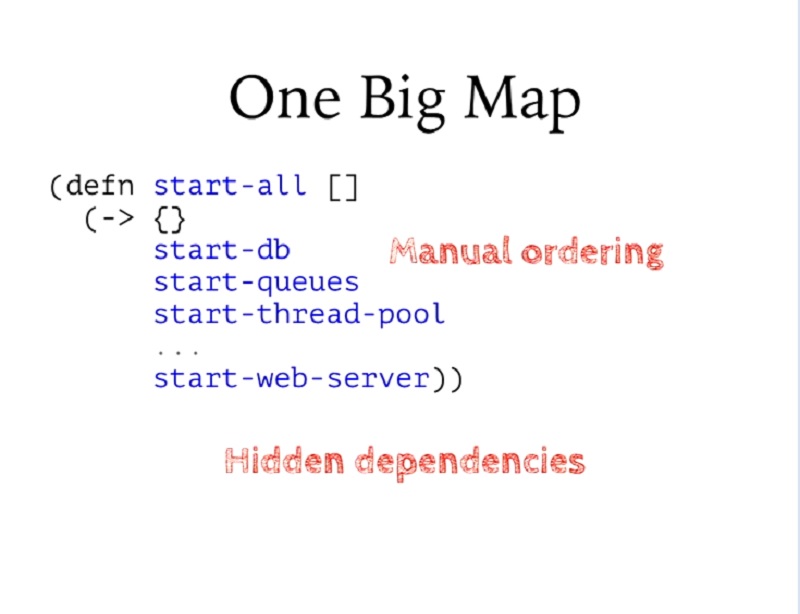
여기에는 DB가 웹 서버보다 우선해야 한다는 의미는 없습니다. 단지 기억해야 할 사항입니다. 또한 이러한 것들 사이에 숨겨진 종속성이 있을 수도 있습니다. 제가 코드를 작성했기 때문에 이 함수 중 하나가 이전 함수에서 생성된 상태 중 일부를 사용할 것이라는 것을 알아야 합니다. 그래서 더 나은 방법이지만, 크게 보면 Clojure의 설명에서 얻고자 했던 것을 얻지 못합니다.
There's nothing about this that's saying that DB has to come before Web server. That's just something you have to remember. You can also have hidden dependencies between these things. I just have to know, because I wrote the code, that one of these functions is going to use some of the state that was created by an earlier function. So it's better, but it doesn't really get what I was hoping to get out of the description in Clojure in the large.

그래서 저는 이러한 아이디어를 조금 더 발전시켜 다양한 애플리케이션에서 사용할 수 있는 재사용 가능한 코드 라이브러리로 코딩할 수 있는지 알아보고 싶었습니다. 그래서 저는 컴포넌트라는 아이디어를 중심으로 구축하기로 결정했습니다.
So I wanted to take those ideas and see if I could advance them just a little bit further and actually codify this into a library of reusable code that I could use in lots of different applications. So I settled on building it around this idea of a component.

컴포넌트는 제가 방금 정의한 개념입니다. 이것이 이 강연과 이 패턴의 목적상 컴포넌트에 대한 저의 정의입니다. 컴포넌트는 불변의 데이터 구조입니다. 사실, 클로저 맵 또는 레코드입니다. 그리고 그와 관련된 함수 집합이 있으며, 이를 이 컴포넌트의 공용 API라고 부르겠습니다. 생성자와 여러 상태 간에 컴포넌트를 전환할 수 있는 몇 가지 함수로 구성된 관리되는 수명 주기가 있습니다. 그리고 의존하는 다른 컴포넌트와의 관계가 있습니다.
A component is something that I've just given this definition. This is my definition of a component for the purposes of this talk and this pattern. It's an immutable data structure. In fact, it's a Clojure map or record. And then it has a set of functions associated with it, and I'll call those the public API of this component. It has a managed lifecycle consisting of a constructor and a couple of functions that can transition the component between different states. And then it has relationships to other components on which it depends.

이것이 객체 지향 프로그래밍의 객체 정의와 의심스러울 정도로 비슷해 보인다면, 바로 그 때문입니다. 저는 이 정의를 객체 지향 디자인 패턴에 관한 문헌에서 거의 그대로 가져왔지만 한 가지 중요한 차이점이 있습니다.
Now if this looks suspiciously like the definition of an object from object-oriented programming, that's because it is. I took this definition, or I stole this definition almost word-for-word from literature on object-oriented design patterns with one, one key difference.

컴포넌트를 사용하면 동작에만 관심이 있다는 것입니다. 객체 지향 패턴과 객체 지향 프로그래밍은 사물에 대한 데이터와 그 사물에 대해 작동하는 함수를 결합하는 경향이 있습니다. 저는 주로 동작과 프로세스에 관심이 있습니다. 물론 필요한 상태도 있겠지만 대부분 부수적인 것이죠.
And that is that, really, with components, I'm only interested in behavior. Object-oriented patterns and object-oriented programming tends to combine data about a thing and the functions that operate on it. I’m primarily interested in the behavior and the processes. There will be some state that I need to do that, but it's largely incidental.

그래서 제가 사용하는 가장 일반적인 유형의 컴포넌트이자 저를 이 길로 이끌었던 컴포넌트는 간단한 상태 래퍼입니다. 예를 들어 데이터베이스에 대한 연결과 같은 상태 저장 객체가 있는데 Datomic과 같은 멋진 데이터베이스를 사용하지 않기 때문에 실제로는 한 번 생성한 다음 프로그램의 모든 곳에 전달하는 값비싼 연결 객체를 추적해야 합니다.
So the most common type of component that I end up using, and the one that sort of sent me down on this path is a simple state wrapper. I have some stateful object, say a connection to a database, and I'm not using a nice database like Datomic, so I actually have to keep track of this expensive connection object that I create once and then pass everywhere in my program.

그래서 호스트 이름과 런타임 상태인 구성만 가져와서 DB라고 부르는 이 레코드에 함께 캡슐화하겠습니다. 그런 다음 이 객체, 이 DB 레코드는 대부분의 코드에서 불투명하다는 규칙을 채택할 것입니다.
So I'm going to take things: the configuration for this, which is just a host name and the runtime state, and encapsulate them together in this record, which I've called DB. Then I'm going to adopt a convention that this object, this DB record will be opaque to most pieces of my code.

그들은 그것을 사용할 것입니다. 그들은 그것을 가질 것입니다. 그들은 그것을 전달하겠지만 실제로 내부를 들여다보지는 않을 것입니다. 마치 이것이 Java 객체이고 해당 객체에서 호스트와 conn이 비공개 필드인 것과 같지만, 실제로는 그럴 필요가 없기 때문에 이를 강제하지 않을 것입니다.
They'll use it. They'll have it. They'll pass it around, but they won't actually be looking inside it. It's as if this were a Java object and those host and conn were private fields in that object, except I'm not actually going to enforce that because I don't need to.

이제 공개 API를 작성하겠습니다. 이 컴포넌트를 사용해 어떤 작업을 수행하는 몇 가지 함수를 작성하겠습니다.
So then I'll write my public API. I'll write some functions that use this component to accomplish some task.

이제 이러한 각 함수는 컴포넌트를 인자(보통 첫 번째 인자)로 받습니다. 따라서 이러한 함수는 실제로 DB 컴포넌트와 함께 작동합니다. 이 함수들은 API의 일부입니다.
Now, each of these functions is going to take the component as its argument, usually the first argument. So these functions are actually working with the DB component. They are part of its API.

부작용이 있을 수 있습니다. 계산을 할 수 있습니다. 내가 원하는 것은 무엇이든 할 수 있습니다.
They can have side effects. They can do computation. They can do whatever I want.

특히 이 컴포넌트의 내부 상태를 사용할 수 있습니다. 마치 클래스의 공용 메서드에 참조할 수 있는 비공개 필드가 있는 것과 같습니다. 그래서 저는 프로그램의 여러 부분 사이에 경계를 만드는 데 도움이 되는 것을 볼 수 있도록 이러한 가시성 규칙을 채택하고 있습니다.
And, in particular, they can use the internal state of this component. It's as if these were public methods on a class with private fields in that class that they can refer to. So I'm just adopting these conventions of visibility in what is allowed to see what that will help me create boundaries between different parts of my program.

그런 다음 컴포넌트에 대한 생성자를 제공해야 합니다. 이제 기본 def record 생성자를 재사용할 수도 있습니다. 하지만 이 경우에는 정적 구성을 사용하여 컴포넌트의 초기 상태를 생성하는 작은 생성자 함수를 작성하겠습니다.
Then I have to provide a constructor for my component. Now, I could just reuse the default def record constructor. But in this case I'm going to write a little constructor function that just uses the static configuration to create the initial state of the component.


특히 이 생성자에는 부작용이 없습니다. 이것이 제가 클로저 인 더 라지에서 설명한 시스템과 거기서 이야기한 패턴과 이 강연에서 이야기하는 패턴 사이의 몇 가지 차이점 중 첫 번째입니다. 그리고 계속 진행하면서 이러한 차이점을 계속 추적하려고 노력할 것입니다. 생성자에는 부작용이 없습니다.
In particular, this constructor does not have any side effects. Now this is the first of several differences between the system I described in Clojure in the Large and the patterns I talked about there and the patterns I'm talking about in this talk. And I'll try to keep track of those differences as I go on. So no side effects in the constructor.

그리고 제가 작성한 코드 중 가장 유명한 코드인 라이프사이클 프로토콜이 있습니다. 저는 Clojure in the Large에서 이에 대해 이야기했고, 다양한 버전이 존재했습니다. 사람들은 자신만의 확장과 변형을 생각해 냈습니다. 하지만 저는 실제로 컴포넌트라는 라이브러리에 넣어서 약간 다른 버전을 만들었습니다.
시작과 중지라는 두 가지 메서드가 있습니다. 이 두 메서드는 컴포넌트를 인자로 받고 컴포넌트를 반환값으로 반환합니다. 이 메서드의 기본 구현은 그냥 연산이 없는 것입니다. 이 메서드는 인자로 전달되는 모든 것을 반환합니다. 따라서 이 메서드를 구현하지 않으면 기본값은 아무것도 변경하지 않는 것입니다.
Then I have probably the most famous piece of code I ever wrote: the lifecycle protocol. Now I talked about this in Clojure in the Large, and there have been many different versions of it. People have come up with their own extensions and variations of this. But I have a slightly different version of it now that I've actually put into a library called component.
It's two methods: start and stop. They take a component as an argument, and they will return a component as a return value. There's also a default implementation of this that is just a no op. It returns whatever you pass in. So if you don't implement this, the default will be: don't change anything.


예를 들어 데이터베이스 컴포넌트에서 이 프로토콜을 구현하는 경우, 시작 및 중지 구현을 제공하면 부작용이 발생할 수 있습니다.
So if I'm implementing this protocol on my database component, for example, I provide start and stop implementations, which may have side effects.

그들은 일을 할 수 있습니다. 외부 리소스에 대한 연결을 만들 수 있습니다. 스레드나 채널과 같은 내부 리소스를 만들 수도 있습니다.
They can do things. They can create connections to external resources. They could create internal resources like threads or channels.

그런 다음 자신이 만든 새로운 것들을 컴포넌트 자체에 연결합니다. 이것이 클로저 인 더 라지와의 또 다른 주요 차이점입니다. 그 강연에서는 시작과 중지에 대한 부작용만 설명했습니다. 이제 시작과 중지에도 부작용이 있지만 반환 값도 있으며 나중에 중요해질 것이라고 말씀드리고 싶습니다.
따라서 전달받은 컴포넌트의 업데이트된 버전을 반환해야 합니다. 그리고 컴포넌트는 레코드이므로 불변의 데이터 구조라는 점을 기억하세요. 새 버전을 만들어서 반환할 수 있습니다.
And then they're going to assoc those new things they've created onto the component itself. This is another key difference from Clojure in the Large. In that talk, I only described start and stop for their side effects. Now I'm saying start and stop have side effects, but they also have a return value, and that will become important later.
So I have to return a possibly updated version of the component that was passed in. And remember, the component is a record, so it's an immutable data structure. I can create a new version of it to return.

다음 유형의 컴포넌트는 단순히 다른 컴포넌트에 서비스를 제공하는 컴포넌트입니다. 모든 애플리케이션이 이메일을 보내야 하므로 내 애플리케이션도 이메일을 보내야 한다고 가정해 봅시다. 그리고 엔드포인트 URL과 API 키라는 두 가지 구성이 필요한 이메일 API 서비스를 사용한다고 가정해 봅시다.
The next type of component is one that simply provides a service to other components. So let's say my application needs to send email because every application needs to send email. And let's say I'm using some email API service that requires these two bits of configuration, an endpoint URL and an API key.

이 두 가지를 조합할 수 있습니다. 실제로 추적할 런타임 상태는 없지만 이메일을 보내려면 이 두 가지 구성이 필요하다는 것을 알고 있습니다. 그래서 이메일이라는 레코드에 이 두 가지를 함께 캡슐화하겠습니다.
Well, I can put those two things together. There isn't actually any runtime state to keep track of, but I know that in order to send email, I need those two bits of configuration. So I'll encapsulate them together in this record called email.

그런 다음 이메일 컴포넌트를 인수로 받아 서비스를 제공하는 공용 API 함수를 작성하겠습니다. 이 함수는 필요한 작업을 수행합니다. 이 경우에는 이메일 전송입니다. 따라서 이메일을 보내려는 다른 사람은 이 레코드의 인스턴스가 필요하지만 엔드포인트나 API 키에 대해서는 아무것도 알 필요가 없습니다. 이메일 전송이 어떻게 작동하는지에 대한 메커니즘을 알 필요도 없습니다.
And then I'll write a public API function that takes the email component as its argument and provides the service. It does the thing that it needs to do. In this case, sending an email. So anyone else who wants to send email, they need an instance of this record, but they don't need to know anything about endpoint or API key. They don't need to know the mechanics of how sending email works.

마지막으로 가장 흥미로운 컴포넌트이자 설명하는 방법을 알아내는 데 가장 오랜 시간이 걸렸던 컴포넌트는 도메인 모델입니다. 애플리케이션에서 일부 기능의 하위 집합을 가져와 컴포넌트로 표현할 수 있습니다. 이를 데이터 구조로 만들 수 있습니다. 여기서부터 일반적인 객체 지향 접근 방식과 약간 차이가 나기 시작합니다.
Java와 같은 일반적인 객체 지향 앱에서는 단일 고객을 나타내는 데이터와 고객에 대해 수행할 수 있는 동작 및 작업을 정의하는 메서드가 모두 포함된 고객 클래스가 있을 것입니다.
Finally, probably the most interesting kind of component and the one that took me the longest to really figure out how to describe is a domain model. I can take some subset of functionality in my application and represent it as a component. I can make it into a data structure. Now, again, this is where we start to differ a little bit from the typical object-oriented approach.
In a typical object-oriented app like Java, you'd expect to have a customer class, which would both have data representing a single customer, and methods that define the behavior and the operations you can do on a customer.

이 고객 구성 요소는 모두 행동에 관한 것입니다. 기본적으로 고객에 대해 수행하고자 하는 일련의 종합적인 작업을 나타냅니다. 하지만 실제 고객 데이터 자체는 그냥 일반적인 Clojure 데이터일 수 있습니다. 저희는 그 점이 마음에 듭니다. 유용하거든요.
This customer's component is all about behavior. It basically represents a set of aggregate operations, things I might want to do with customers. But the actual customer data itself can just be ordinary Clojure data. We like that. It's useful.

따라서 이것이 주로 하는 일은 관련 종속성 집합을 캡슐화하는 것입니다. 예를 들어 애플리케이션에서 고객을 상대하고 고객에게 필요한 서비스를 제공하기 위해서는 데이터베이스에 액세스해야 하고 이메일을 보낼 수 있어야 합니다. 그래서 고객 컴포넌트에 이러한 기능을 필드로 넣겠습니다. 이제 여기에 실제로 지도를 사용할 수 있습니다. 맵도 똑같이 작동하지만 저는 이름을 붙이는 것을 좋아하므로 고객이라고 부르고 레코드를 사용하겠지만 맵도 똑같은 방식으로 작동할 것입니다.
So what this does primarily is encapsulate a set of related dependencies. So maybe I know, in my application, in order to deal with customers, to satisfy the services that I need for customers, I need access to the database, and I need to be able to send email. So I'll put those as fields in the customer's component. Now I could actually use a map here. It would work just as well, but I like giving things names, so I'll call it customers and use a record, but a map would work exactly the same way.

그런 다음 고객 컴포넌트에 대한 API를 정의할 수 있습니다. 고객에게 알림을 보내는 함수를 만들겠습니다. 고객에게 무언가를 알리고 싶습니다. 그리고 고객에게 이메일을 보내서 알리려고 합니다.
Then I can define the API for the customer's component. I'll have this function to notify a customer. I want to tell the customer something. And I'm going to do that by sending them email.

따라서 고객 컴포넌트는 이 함수의 첫 번째 인수가 되고, 그 다음에는 해당 필드를 사용하여 종속성을 가져옵니다. 따라서 로컬 상태에서 DB와 이메일을 가져옵니다. 이러한 것들을 찾기 위해 더 광범위하고 글로벌한 컨텍스트에 도달할 필요가 없습니다.
So the customer's component is the first argument to this function, and then it uses those fields to get its dependencies. So it gets DB and email out of its local state. It doesn't need to reach out to some broader, more global context to find those things.

그런 다음 구성 요소를 확보하면 해당 구성 요소의 공개 API를 통해 해당 구성 요소를 호출할 수 있습니다. 여기서 이 컴포넌트에 어떤 DB와 이메일이 들어있는지에 대해서는 아무 말도 하지 않았습니다. 어디에서 왔는지, 어떤 유형인지, 그 밖의 어떤 것도 말하지 않았습니다. 제가 아는 것은 이 컴포넌트에 제공될 것이고 이 함수를 사용하여 호출할 수 있다는 것뿐입니다. 따라서 DB는 쿼리를 호출할 수 있는 무언가이고 이메일은 보내기를 호출할 수 있는 무언가이며, 이 컴포넌트가 알아야 할 것은 그것뿐입니다.
Then once it has them, it can invoke those components through their public APIs. Now notice I haven't said anything here about what DB and email are in this component. I haven't said where they come from, what type they are, or anything else. All I know is that they will be provided to this component and that I can call them using these functions. So DB is something on which I can call query and email is something on which I can call send, and that's all this component needs to know.

이제 이 컴포넌트를 만들 때 새로운 것을 추가하겠습니다. 제 라이브러리에 있는 using이라는 함수를 사용하겠습니다.
Now when I construct this component, I'm going to add something new. I'm going to use this function that's in my library called using.

using은 기본 def record map to record 생성자를 사용하여 구성한 컴포넌트와 키 컬렉션을 가져옵니다. 그리고 그 키는 해당 컴포넌트의 종속성의 이름입니다. 실제로는 컴포넌트에 메타데이터를 추가하는 것뿐입니다. 하지만 저는 이 컴포넌트인 Customers가 :db라는 이름의 무언가와 :email이라는 이름의 무언가에 종속되어 있다고 선언하고 있습니다.
using just takes a component, which I've constructed using the default def record map to record constructor, and a collection of keys. And those keys are the names of that component's dependency. Actually, all it's doing is adding some metadata onto the component. But I'm declaring that this component, Customers, depends on something named :db and something named :email.

특히 생성자 함수에서 종속성을 전달하지 않습니다. 이것은 제가 클로저 대백과에서 설명한 것과 또 다른 차이점입니다. 제가 할 일은 종속성을 선언하는 것뿐이며 나중에 채워질 것입니다.
In particular, I am not passing the dependencies in the constructor function. This is another difference from what I described in Clojure in the Large. All I'm going to do is declare my dependencies and they'll get filled in later.

그래서 저는 이러한 컴포넌트를 가지고 있습니다. 지금까지 세 가지를 만들었고, 그 사이에 선언한 종속성 관계가 몇 가지 있습니다.
So I have these components. I've done three so far, and I have some dependency relationships that I've declared between them.

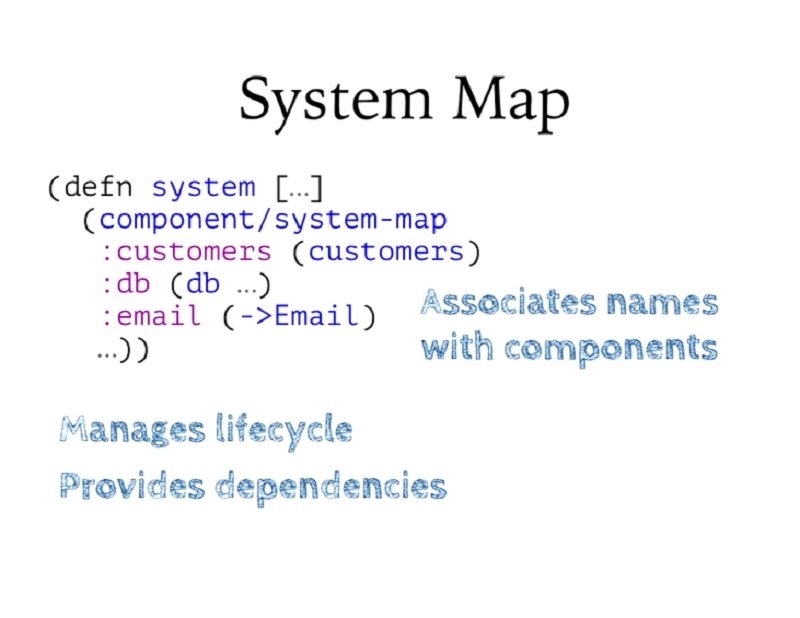
이제 저는 이러한 요소들을 한데 모아 시스템 또는 구성 요소 모음이라고 부르는 것을 만들고 싶습니다. 이 경우 시스템이란 그저 하나의 지도에 불과합니다.
Now I want to put them together, and I do that in what I call a system or a collection of components. A system, in this case, is just, really just a map.

저는 이를 구성하기 위해 이 작은 헬퍼 함수를 제공합니다. 기본적으로 그냥 레코드를 만듭니다. 그리고 모든 실용적인 목적을 위해 이 레코드를 클로저 맵처럼 취급할 수 있습니다.
I provide this little helper function to construct it. It basically just makes a record. And, for all practical purposes, I can treat that record like a Clojure map.

시스템의 목적은 컴포넌트를 이름과 연관시키는 것입니다. 이러한 이름은 일반적으로 키워드이지만, 반드시 키워드는 아니어도 됩니다. 따라서 이 시스템에는 세 가지 컴포넌트가 있으며, 시스템 범위 내에서 각 컴포넌트에 이름을 할당하고 있습니다.
The purpose of a system is to associate components with names. Those names are usually keywords, although they don't have to be. So I have three components, which I'm constructing for this system, and I'm assigning each one a name within the scope of the system.
따라서 시스템 자체는 포함된 구성 요소의 수명 주기를 관리하고 해당 종속성을 제공할 책임이 있습니다.
So the system itself is responsible for managing the lifecycle of the components it contains and providing them with their dependencies.
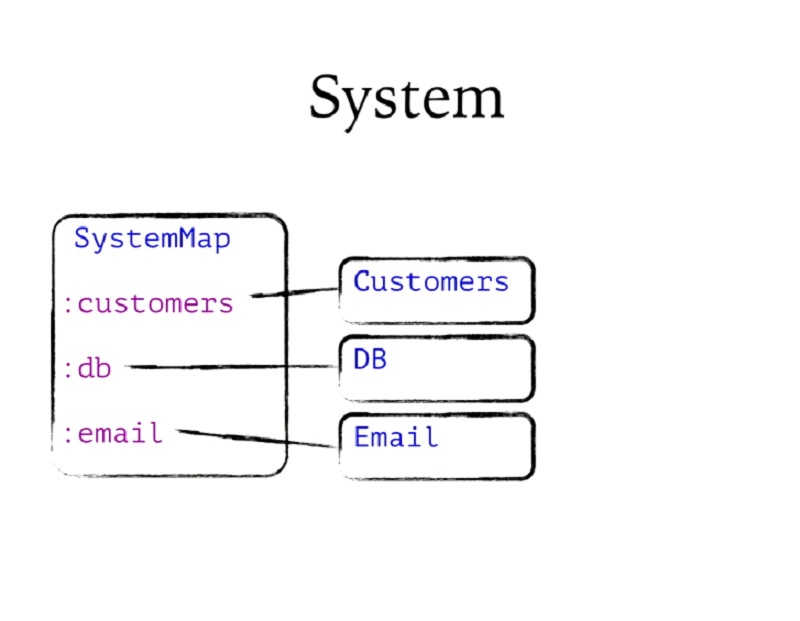
작동 방식은 다음과 같습니다. SystemMap은 그냥 함수입니다. 키와 값을 받아 제가 정의한 이 시스템 맵 레코드의 인스턴스를 반환합니다. 이제 기억하세요, 클로저 레코드는 맵입니다. 어떤 임의의 키라도 연결할 수 있으므로 고객, DB, 이메일이 이 시스템의 키가 될 것이라고 미리 말할 필요가 없었습니다. 그냥 그렇게 넣었을 뿐입니다.
SystemMap과 일반 맵의 유일한 차이점은 라이프사이클 프로토콜의 자체 구현이 내장되어 있다는 점입니다. 따라서 시스템은 스스로 시작하고 중지하는 방법을 알고 있습니다.
So here's how it works. SystemMap is just a function. It takes keys and values, and it returns an instance of this system map record that I've defined. Now remember, Clojure records are maps. They can have any arbitrary keys associated onto them, so I didn't need to say in advance that customers, DB, and Email were going to be the keys in this system. That's just what I happened to put in it.
The only difference with SystemMap, the only thing that distinguishes it from an ordinary map is it has its own implementation of the lifecycle protocol built in. So a system knows how to start and stop itself.
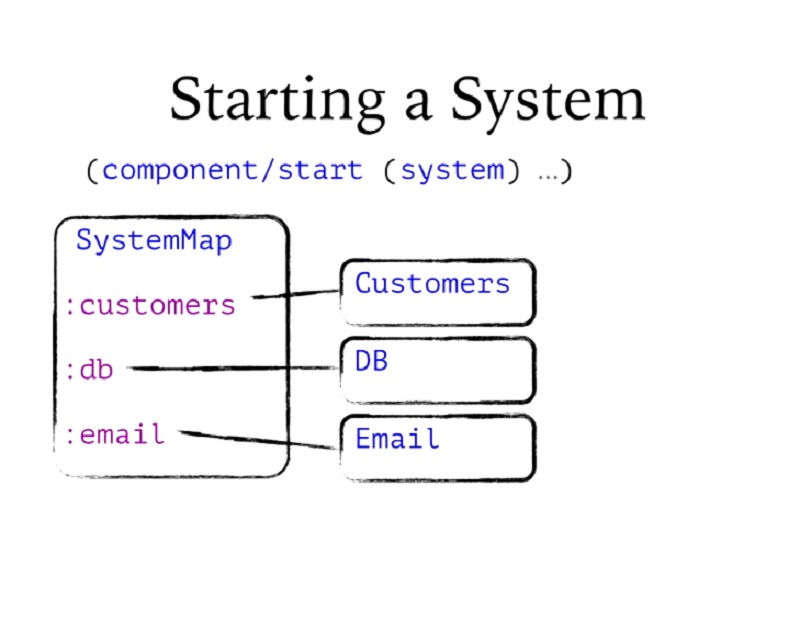
특히 포함된 모든 구성 요소를 시작하여 이를 수행하는 방법을 알고 있습니다. 따라서 시스템에서 시작을 호출하면 이 절차를 순서대로 거치게 됩니다.
And, in particular, it knows how to do that by starting all of the components it contains. So when I call start on a system, it's going to go through this procedure in order.
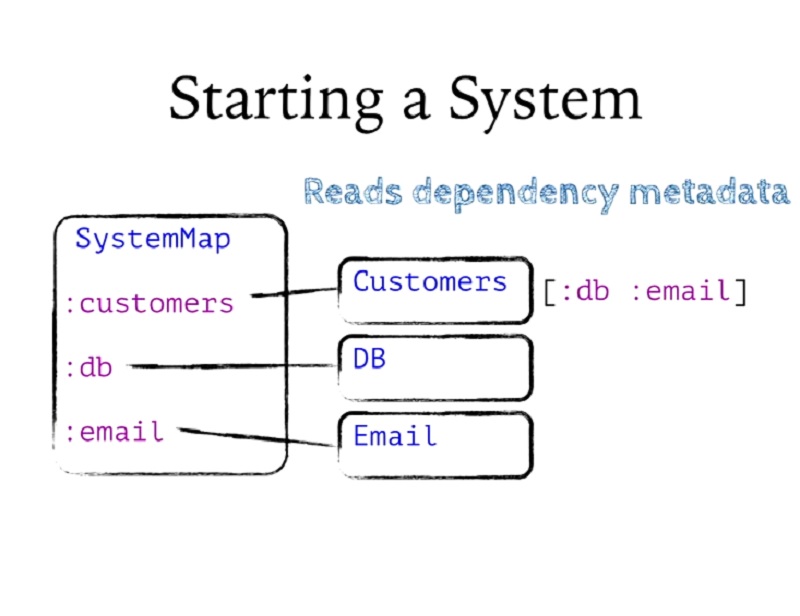
먼저, 포함된 컴포넌트를 살펴보고 그 종속성이 무엇인지 확인합니다. 그리고 사용 함수가 내 레코드에 추가한 메타데이터를 읽습니다. 따라서 고객이 DB와 이메일에 종속되어 있다는 것을 알 수 있으며, :db 및 :email이라는 항목이 있다는 것을 알 수 있습니다.
First, it's going to look at the components it contains and see what their dependencies are. It's going to read off that metadata that the using function added onto my records. So it sees that customers depends on DB and Email, and it knows that it has things called :db and :email.
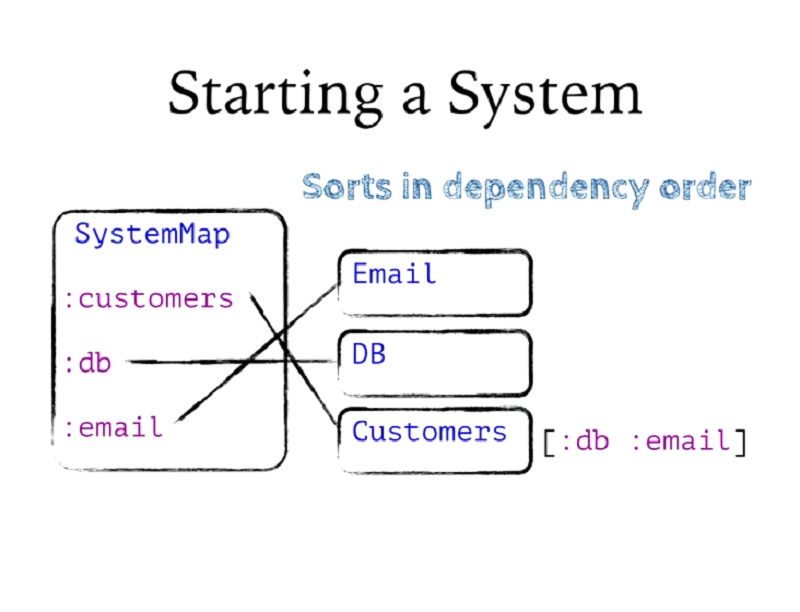
그런 다음 모든 컴포넌트를 순서대로 정렬합니다. 모든 종속성의 그래프를 작성한 다음 해당 그래프에서 토폴로지 정렬을 수행하여 구성 요소를 어떤 순서로 시작해야 하는지 파악합니다.
Then it's going to sort all the components in order. It's going to build a graph of all the dependencies and then do a topological sort on that graph to figure out what order the components should be started in.
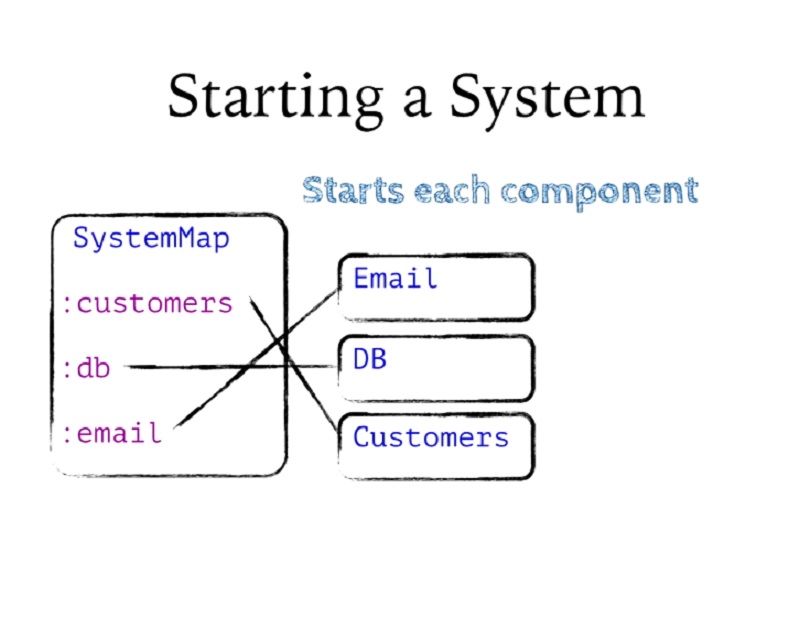
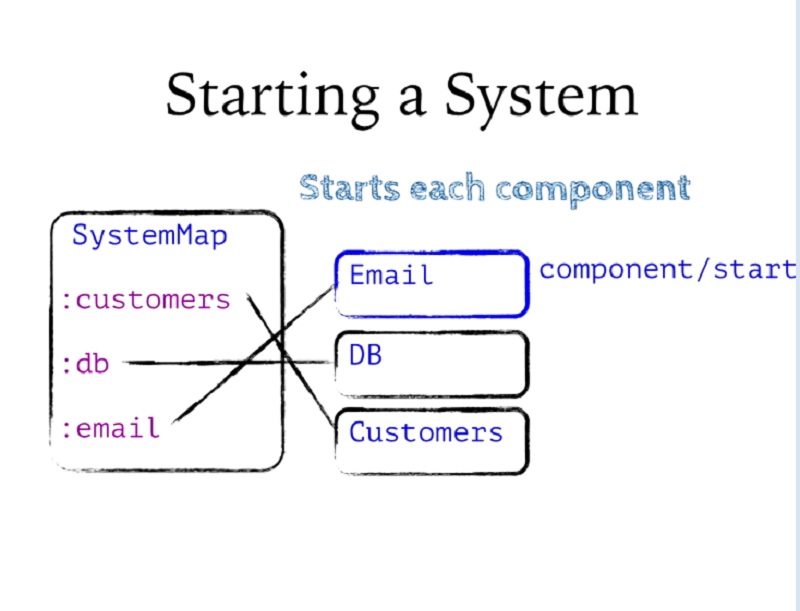
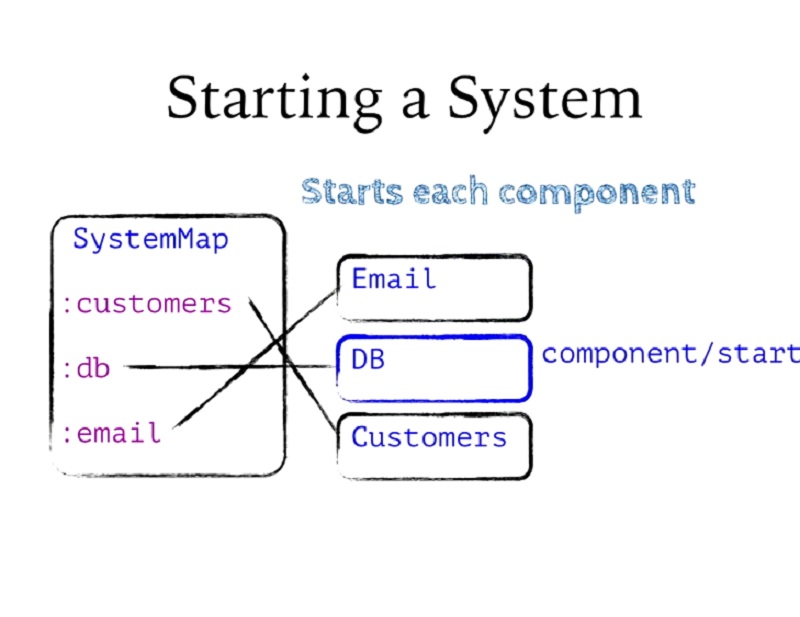
그런 다음 각 컴포넌트에서 시작을 순서대로 호출합니다. 종속성 순서대로 컴포넌트를 단계별로 살펴보고 라이프사이클 시작 메서드를 호출하여 모두 시작합니다.
Then it's going to call start on each component in order. It's going to step through the components in dependency order and start them all by calling the lifecycle start method.
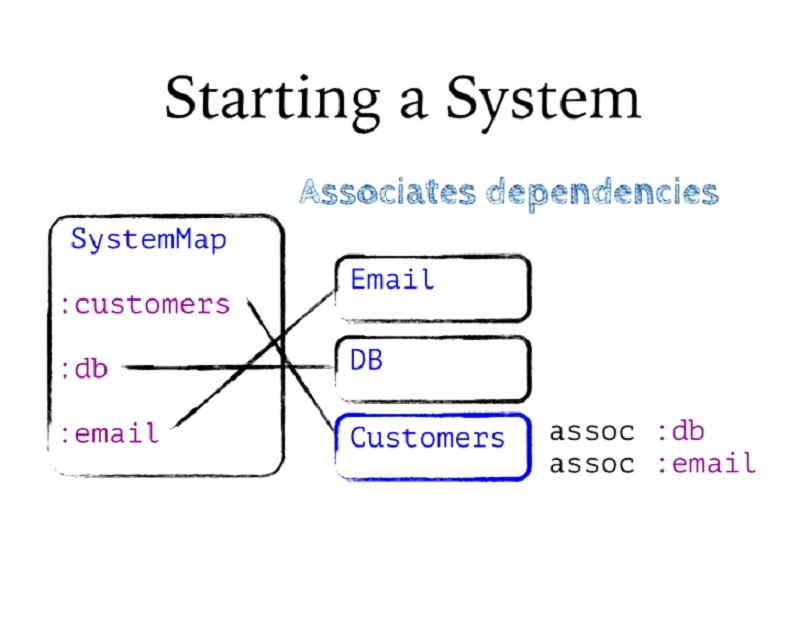
이 예제의 Customers와 같이 종속성이 있는 컴포넌트에 도달하면 먼저 해당 종속성을 해당 컴포넌트에 연결합니다. 레코드나 맵 등 어떤 것이든 그냥 연결할 수 있으며, 고객에게 DB와 이메일이 필요하다고 선언했으므로 시스템에서 DB와 이메일을 Customers에 연결하겠습니다.
When it gets to a component that has dependencies, like Customers in this example, it's going to first associate its dependencies into it. Remember, records or maps, whichever these are, I can just assoc onto them, and I've declared that customers needs DB and Email, so I'm going to assoc DB and Email from the system into Customers.
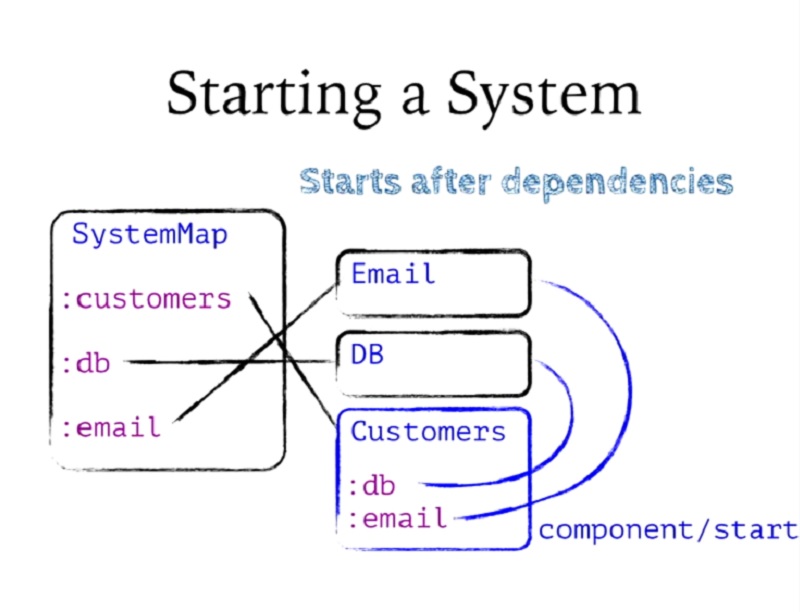
이 작업을 완료하면 Customers를 시작할 수 있으므로 Customers에서 구성 요소 시작을 호출할 때쯤이면 이미 DB와 이메일이 시작되어 Customers에 연결되었음을 알 수 있습니다.
And once I've done that, then I can start Customers, so I know that by the time I call component start on Customers, DB and Email have already been started and they've been assoc'ed into Customers.
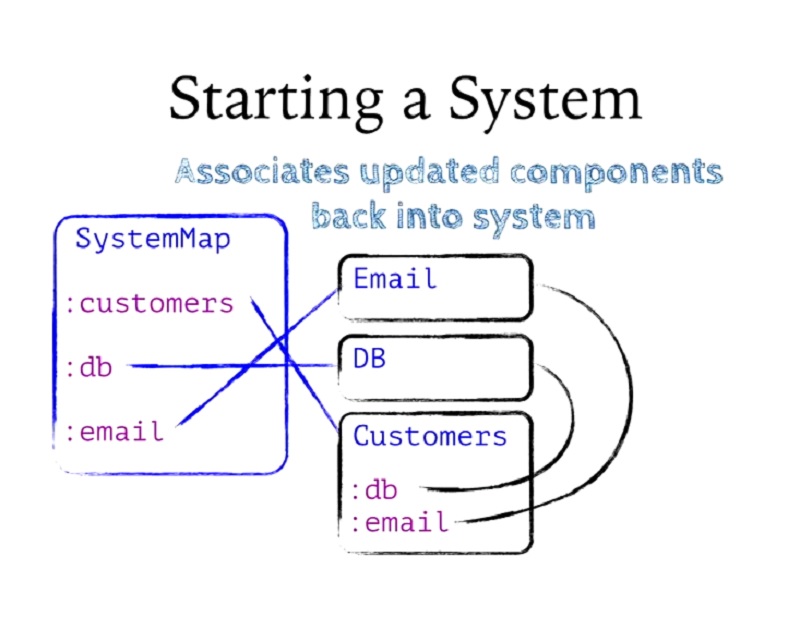
이렇게 시작 컴포넌트를 모두 가져옵니다. 시작을 호출할 때마다 새로운 상태가 포함된 새 버전의 컴포넌트가 반환된다는 점을 기억하세요. 이 모든 것을 다시 시스템에 할당합니다. 이것이 시스템이 시작될 때 수행하는 마지막 단계입니다. 이제 컴포넌트가 서로 연결되어 있고 모두 시작되었으며 모든 것이 올바른 순서로 진행되었습니다.
So we get all of these started components. Remember, each time we call start it returns potentially a new version of the component with some new state in it. We assoc all of those back into the system. That's the last step that the system does when it's starting itself. So now I have my components connected together, and they're all started, and it's all happened in the right order.
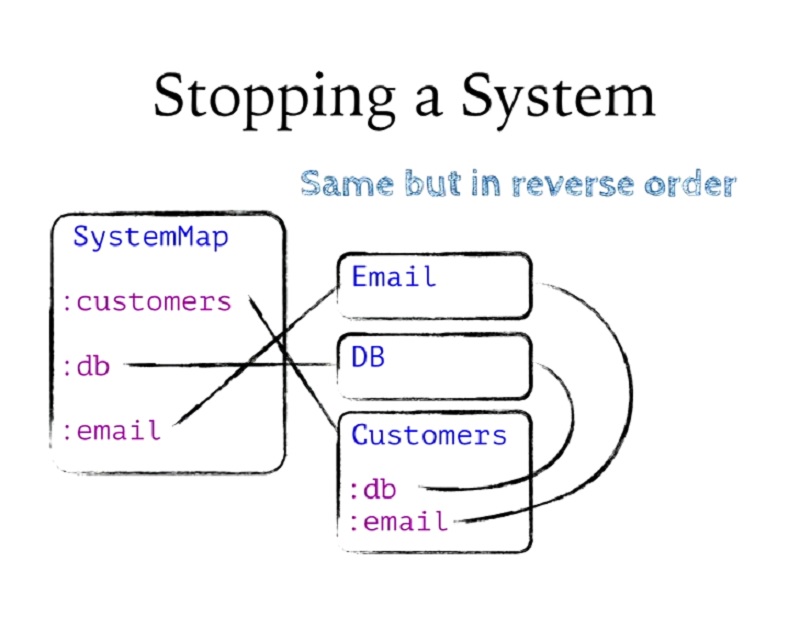
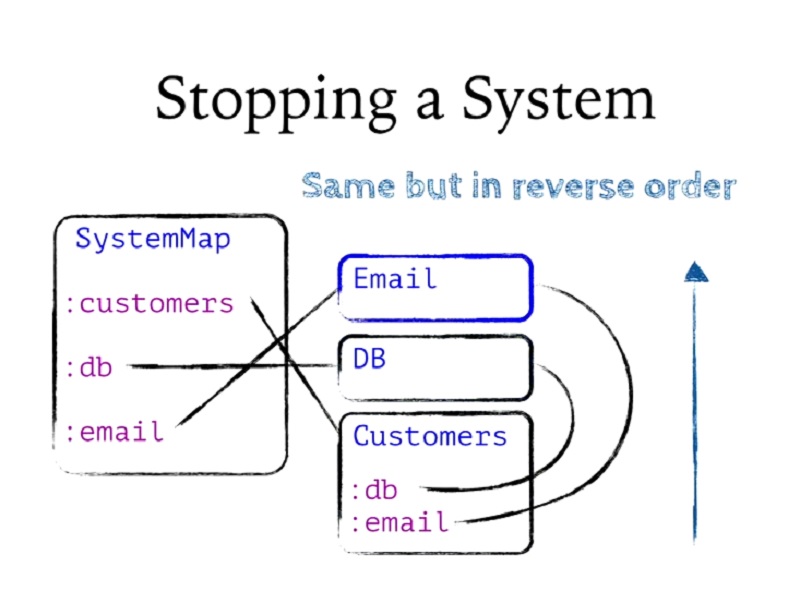
시스템을 중지하는 절차는 동일합니다. 다만 역순으로 진행됩니다. 고객부터 시스템에서 종속성이 가장 적은 것부터 백업합니다.
이 과정을 통해 구성 요소를 종속 요소에 연결할 수 있었습니다. 저는 기본적으로 이메일과 DB를 고객에 주입하여 시스템에서 고객을 찾았습니다.
Stopping a system is the same procedure. It just goes in the reverse order. It goes from customers back up to the least dependent things in the system.
So in -- this has allowed me to connect a component to its dependencies. I've basically injected Email and DB into Customers, finding them in the system.

패턴과 디자인에 관한 객체 지향 문헌에는 종속성 주입에 대한 많은 이야기가 있으며, 종속성 주입을 어떻게 해야 하는지에 대해 서로 경쟁하는 두 가지 학파가 있습니다. 객체를 생성할 때 객체의 종속성을 주입하는 생성자 기반 주입을 할 수도 있고, 객체를 실제로 변형하여 종속성을 부여하는 세터 주입을 할 수도 있습니다.
Now in the object-oriented literature about patterns and design, there's a lot of talk about dependency injection and these two sort of competing schools of thought on how you should do it. You can do constructor based injection where you inject dependencies of a thing when you construct that thing, or you can do setter injection where you actually mutate the thing to give its dependencies to it.

불변 맵을 구성 요소로 사용하면 다른 작업을 할 수 있습니다. 실제로 연관 주입을 할 수 있습니다. 세 가지 컴포넌트가 포함된 시스템이 있고 몇 가지 테스트를 작성하고 싶다고 가정해 보겠습니다. 하지만 테스트가 실제로 실제 이메일을 보내거나 실제 프로덕션 데이터베이스를 사용하는 것은 원하지 않습니다. 테스트 목적으로만 이러한 구성 요소의 새 버전을 만들 수 있습니다. 그런 다음 시스템에 포함하려면 일반적인 Clojure 어소시에이트를 호출하기만 하면 됩니다.
When we have immutable maps as our components, we can do something else. We can actually do associative injection. So say I've got my system with my three components in it, and I want to write some tests. But I don't want my tests to actually send real email, and I don't want them to use my actual production database. I can create new versions of these components that are just for testing purposes. And then, if I want to include them in my system, all I have to do is call assoc, ordinary Clojure assoc.

시스템은 기록이라는 사실을 기억하세요. 기록은 곧 지도입니다. 맵에 연결할 수 있으므로 시작하기 전에 이 작업을 수행하면 시스템의 이메일과 DB를 다른 구현으로 대체할 수 있습니다.
Remember, a system is a record. A record is a map. I can assoc onto a map, so I can replace Email and DB in my system with alternate implementations provided I do this before starting it.

내가 시작을 호출하면 모든 것이 함께 연결된다는 것을 기억하세요. 따라서 시작을 호출하기 전에 이 맵에 원하는 모든 것을 할 수 있습니다. 컴포넌트를 교체하고, 컴포넌트를 추가하고, 컴포넌트를 제거할 수 있습니다. 그리고 시작을 호출하면 모든 것이 연결되고 서로를 사용하기 시작합니다.
Remember, everything is going to get connected together when I call start. So before calling start, I can do whatever I want to this map. I can replace components, add components, remove components. And then when I start, that's when things will get connected and start using each other.

예를 들어 테스트 목적으로 이메일 서비스의 스텁 버전이 필요하다고 가정해 보겠습니다.
So just as an example, say I wanted a stub version of my email service for testing purposes.

먼저 한 가지를 해볼게요. 보내기 기능을 디스패치할 수 있는 기능으로 바꿔야 합니다. 이 경우에는 프로토콜로 바꾸겠습니다. 여러 가지 방법을 사용할 수도 있습니다. 같은 효과를 낼 수 있습니다. 하지만 이 구성 요소의 다른 구현으로 교체할 수 있는 경계를 설정해야 합니다. 이 경우에는 프로토콜을 사용하고 있습니다. 그러면 원래 이메일 서비스가 이 프로토콜을 구현할 것이고, 외부 부작용을 일으키지 않는 서비스의 스텁 구현을 작성할 수 있습니다.
Well, I'll do one thing first. I have to take my send function and turn it into something that I can dispatch on. I'll turn it into a protocol in this case. I could also use a multi-method. It would have the same effect. But I need to establish some boundary at which I can swap out a different implementation of this component. In this case, I'm using a protocol. So then my original email service would implement this protocol, and I can write a stub implementation of the service that doesn't do whatever the external side-effecty thing is.

실제로 이 스텁 이메일 구현은 제가 어떤 호출을 하든, 어떤 연산을 요청하든 데이터 구조(저기 가운데에 있는 작은 맵)로 변환하여 core.async 채널에 넣습니다. 그런 다음 버퍼가 있는 채널을 생성하여 이 컴포넌트에 대한 호출을 수집하고 예상한 대로 호출이 수행되었는지 확인할 수 있습니다. 이것을 테스트에서 모의로 사용할 수 있습니다.
In fact, what this stub email implementation does it take whatever calls I give to it, whatever operations I ask it to do, turn them into data structures -- that little map in the middle there -- and put them on a core.async channel. And then I create the channel with a buffer in it so that I can sort of collect any calls made to this component and verify that they were what I expected. I can use this as a mock in my test.

이제 데이터베이스 같은 경우에는 전체 데이터베이스를 모의해 보려고 하지 않겠습니다. 너무 많은 작업이 필요하기 때문입니다. 물론 데이터베이스가 데이터믹(Datomic)이 아니라면 너무 복잡하고, 지원해야 할 항목도 너무 많고, 지원해야 할 작업도 너무 많지만, 이 경우에는 정말 쉽습니다.
Now for something like a database, I'm not going to try to mock out an entire database. That's far too much work. It's too complicated, too many things, too many operations to support, unless of course your database is Datomic, in which case it's really easy.

하지만 제가 할 일은 데이터베이스 래퍼 컴포넌트의 대체 버전을 만들어서 사용하고자 할 때마다 데이터베이스의 고유한 복사본을 생성하고 삭제하는 것입니다.
So -- but what I will do is I'll create an alternate version of my database wrapper component that creates and destroys a unique copy of the database every time I want to use it.

테스트 또는 로컬 개발에 사용할 것입니다. 이 작업을 시작할 때마다 새롭고 고유한 이름의 데이터베이스를 생성한 다음 중지하면 데이터베이스를 삭제합니다. 그래서 저는 이것을 개발에 사용할 수 있습니다. 테스트에 사용할 수 있고 이 데이터베이스를 사용할 때마다 새롭고 잘 알려진 상태의 데이터베이스를 사용할 수 있다는 것을 확신할 수 있습니다.
이제 로컬 데이터베이스 서버를 사용하여 이 작업을 수행할 수 있습니다. 인메모리 데이터베이스를 사용할 수도 있습니다. 이 작업을 수행하는 가장 빠른 방법이 무엇이든, 저는 이 방법으로 애플리케이션을 개발하고 테스트할 것입니다.
So I'll use this for testing or local development. Every time I start this, it's going to create a new, uniquely named database, and then it's going to destroy it when I stop it. So I can use this in development. I can use it in my tests and be certain that every time I use this database it's going to be in a fresh, known, well-understood state.
Now, I might use a local database server to do this. I might use an in-memory database. Whatever is the quickest way to get this working, this is how I'll develop and test my application.

이제 실제로 비즈니스 로직을 테스트할 때 고객 구성 요소를 테스트하고 싶습니다. 단위 테스트에서 이를 테스트하고 싶습니다. 그렇게 하면 완전히 격리된 시스템을 만들어 실행할 수 있습니다.
So now when I get to actually testing the business logic, I want to test that customers component. I want to do that in a unit test. When I do that, I can create a completely isolated system in which to run it.

이 테스트를 위해 만든 테스트 시스템을 단독으로 시작할 수 있으며, 시스템의 다른 테스트에 영향을 받지 않는다는 것을 알 수 있습니다. 심지어 테스트를 병렬로 실행해도 서로 간섭하지 않습니다. 그래서 저는 제가 보고 싶은 것만 꺼내서 테스트합니다. 고객 구성 요소를 가져옵니다. 그리고 스텁 구현인 이메일 컴포넌트를 꺼내서 한 컴포넌트를 호출하고 다른 컴포넌트에서 결과를 확인할 수 있습니다.
I can start my test system that I create for this test alone, and I know it's not going to be affected by any other test in the system. I could even run my tests in parallel and they're not going to interfere with each other. So I just pull out the things that I want to look at. I pull out the Customers component. I pull out the Email component, which is my stub implementation, and then I can make a call to one component and verify the results in another.

또한 모든 종속성이 호출 체인을 통해 전달되기 때문에 전역 범위를 모두 살펴볼 필요가 없습니다. 따라서 비동기 연산을 포함할 수 있는 테스트를 매우 쉽게 작성할 수 있습니다. 이 특정 예제에서는 실제로 그렇게 하지는 않지만, 알림이 스레드 풀이나 채널 또는 메시지 큐로 디스패치하거나 나중에 언제 일어날지 모르는 다른 일 등 여러 계층의 비동기화를 거치고 있다고 가정해 보겠습니다. 이 체인의 마지막에 어떤 버전의 이메일이 도착하든 여기에서 이 테스트 시스템을 만들 때 전달한 버전과 동일해야 한다는 것은 확실합니다.
And because all of the dependencies get passed through the call chain, nothing is every looking at global scope. That makes it very easy to write a test that could include asynchronous operations. Now this particular example doesn't actually do that, but suppose that notify were going through several layers of asynchrony: dispatching to a thread pool or a channel or a message queue, or some other thing that might happen some point later in time; I don't know when. I can be sure that whatever version of email ends up at the end of that chain, it should be the same version that I passed in when I created this test system here.

또한 모든 종속성이 호출 체인을 통해 전달되기 때문에 전역 범위를 모두 살펴볼 필요가 없습니다. 따라서 비동기 연산을 포함할 수 있는 테스트를 매우 쉽게 작성할 수 있습니다. 이 특정 예제에서는 실제로 그렇게 하지는 않지만, 알림이 스레드 풀이나 채널 또는 메시지 큐로 디스패치하거나 나중에 언제 일어날지 모르는 다른 일 등 여러 계층의 비동기화를 거치고 있다고 가정해 보겠습니다. 이 체인의 마지막에 어떤 버전의 이메일이 도착하든 여기에서 이 테스트 시스템을 만들 때 전달한 버전과 동일해야 한다는 것은 확실합니다.
And the reason I like this is that pretty much the only other mechanism that I've seen commonly for doing this in Clojure for substituting in an alternate implementation operates at the level of individual vars. You can either use with-redefs, which is global across your entire program, or binding, which is confined to a thread.

그러나 두 경우 모두 재정의와 바인딩 모두 시간으로 구분됩니다. 이 대체 세계가 사실인 시간 범위를 지정합니다. 그리고 그것은 문제로 이어질 수 있습니다. 프로그램에서 서로 다른 시간 개념을 사용하는 경우, 다른 스레드에서 비동기적으로 일이 발생하거나 예측할 수 없는 시간에 일이 발생하면 테스트에서 잠재적인 경쟁 조건이 발생할 수 있습니다.
But in either case, both with redefs and binding, are delimited in time. They specify a scope of time in which this alternate world is true. And that can lead to problems. If I have different notions of time in my program, if I have things happening asynchronously on different threads or maybe happening at an unpredictable time, I could have potential race conditions in my test.

모의 또는 스텁이 있는 무언가를 테스트하려고 할 때 어떤 때는 작동하고 어떤 때는 작동하지 않는 경우가 많이 발생했습니다. 또는 개인적으로 가장 좋아하는 방법도 있습니다: 더 빠르거나 느린 컴퓨터에서 실행하면 모든 테스트가 실패하기 시작하는 경우입니다. 정말 짜증나는 일이죠.
그래서 이 도구들은 정말 유용합니다. 리정의와 바인딩은 모두 매우 유용하지만 비동기적인 데이터 흐름을 테스트하려고 할 때 문제가 발생할 수 있습니다.
And I've run into this a lot where I'm trying to test something that has mocks or stubs in place, and then it works some of the time, and it doesn't work other times. Or my personal favorite: You run it on a faster or slower machine and all the tests start failing. That's really annoying.
So, you know, these are useful tools. With redefs and binding both have very good uses, but if you're trying to test some data flow that could be asynchronous, they can run into problems.

var 수준에서 대체하는 것이 마음에 들지 않는 또 다른 이유는 세분화 수준이 잘못된 것처럼 느껴진다는 점입니다. 보통 저는 단일 함수를 대체하고 싶지 않습니다. 저는 함수 그룹 전체를 대체하고 싶습니다.
Another thing I don't like about substituting at the var level is it really feels like the wrong level of granularity. Usually I don't want to replace a single function. I want to replace a whole group of functions.

데이터베이스나 이메일 서비스를 교체하고 싶습니다. 따라서 테스트 내에서 개별 변수를 교체해야 하는 것만으로도 위험이 있습니다. 항상 그런 일은 일어나지는 않겠지만, 구현과 매우 밀접하게 연결된 테스트가 될 위험이 큽니다. 변수를 정의하는 코드에서 이러한 변수가 어떻게 사용되는지에 대한 미묘한 세부 사항을 변경하면 의도치 않게 테스트가 망가질 수 있습니다.
I want to replace the database or the email service. So just by having to replace individual vars within a tests, I have a risk. It won't happen all the time, but I have a strong risk that I'll end up with a test that's very tightly coupled to the implementation. If I change some subtle detail of how these vars get used in whatever code defines them, I might end up breaking my tests inadvertently.

이제 구성 요소가 완성되었습니다. 저는 그것들을 하나의 시스템에 모았습니다. 모두 함께 연결했으니 서로 대화하는 방법을 알고 있습니다. 이제 어떻게 해야 하나요? 제가 하고 싶지 않은 한 가지는 그 큰 시스템 맵을 가져다가 프로그램의 모든 함수에 인수로 전달하는 것입니다. 그러면 하나의 큰 맵으로 시작했던 원점으로 돌아가게 되고 똑같은 문제가 발생하게 됩니다.
대신 애플리케이션에서 주요 진입 지점을 찾고 해당 진입 지점에 특정 구성 요소를 삽입하려고 합니다.
So now I've got my components. I've put them together in a system. I've connected them all together, so they all know how to talk to each other. What do I do with them? The one thing I don't want to do is take that big system map and then pass it as an argument to every function in the program. That puts me right back where I started with the one big map, and it has all the same problems.
Instead, what I'm going to do is find key entry points in my application and insert specific components at those entry points.

엔트리 포인트는 코드가 실행되기 시작하는 모든 위치를 의미합니다. 가장 확실한 예는 메인 함수입니다. 메인 함수를 제어하면 애플리케이션이 어떻게 시작되는지 제어할 수 있고, 이 작업만 하면 됩니다. 시스템을 만들고 시작하기만 하면 됩니다. 끝입니다.
An entry point is just any place that your code starts running. The most obvious example is the main function. If you control the main, you control how your application starts up, and this is all it needs to do, then it's easy. Just create a system and start it. You're done.

만약 제가 어떤 종류의 관리 프레임워크를 사용하고 있다면, 예를 들어 Apache Commons 데몬이나 JSVC를 사용하고 있고 이를 애플리케이션의 컨테이너로 사용한다고 가정해 봅시다. 그러면 V의 메서드가 포함된 이 인터페이스를 구현해야 하고 시스템을 보관하기 위해 가변 컨테이너를 추가해야 할 수도 있습니다. 그래서 애플리케이션에 가변 상태 한 가지가 있는데, 이는 시스템 객체를 보유하여 시작과 중지 시 호출되는 V의 여러 진입점이 모두 작동하도록 하기 위한 것입니다.
If I'm using some sort of management framework, let's say I'm using Apache Commons Daemon or JSVC, and I'm using that as a container for my application, well, that requires that I implement this interface with V's methods in it, and I might need to add a mutable container to hold the system. So I have one piece of mutable state in my application and that's to hold the system object so that V's different entry points at which I get called in its start and stop will all work.

하지만 가장 일반적인 경우는 아마도 웹 앱일 것입니다. 처음에는 쉬워 보인다는 이유만으로 라우팅 테이블이나 웹 핸들러와 같은 것을 정적으로 정의하는 것은 일종의 불행한 습관이라고 생각합니다.
The most common case, though, probably is Web apps. And here this is sort of an unfortunate habit that I think we've fallen into just because it seems easy at first, and that is to define things like a routing table or a Web handler statically.

이 라우팅 테이블과 이 핸들러 함수는 여러 함수를 래핑하여 만들어집니다. 예를 들어 링 미들웨어를 함수에 감싸는 것입니다. 하지만 이 파일은 로드될 때 이 작업을 수행합니다. 컴파일 시 정적으로 수행되기 때문에 여기에는 런타임 상태를 주입할 수 있는 곳이 없습니다. 웹 처리 함수에 해당 상태를 다시 가져오려면 어딘가에 있는 전역 변수를 참조해야 합니다.
This routing table and this handler function are created by wrapping a bunch of functions. This is wrapping, say, ring middlewares around a function. But it's doing that when this file gets loaded. It's doing it statically at compile time, which means there's no place in here that I could inject any runtime state. I would have to refer to some global variable somewhere in order to get that state back into my Web handling function.

하지만 실제로는 이 문제를 꽤 쉽게 해결할 수 있습니다. 라우트 핸들러 함수를 정적으로 정의하는 대신 해당 함수를 빌드하는 생성자 함수를 제공해야 합니다. 여기서는 이 함수를 make-handler라고 부릅니다. 그리고 컴포넌트를 호출 체인에 연결하기 위해 해당 함수를 감싸는 작은 미들웨어를 하나 더 추가했습니다. 이 경우에는 링 요청이라고 가정하고 웹-앱이라는 컴포넌트를 해당 요청에 연결하겠습니다.
But it turns out you can actually work around this fairly easily. I need to, instead of defining that route handler function statically, I need to provide a constructor function to build that function. Here I've called it make-handler. And I've added an extra little piece of middleware that wraps that function in something that's just going to associate a component into the call chain. In this case, I'm assuming it's a ring request, and I'm going to associate a component called web-app into that request.

따라서 이 make-handler 함수는 애플리케이션을 시작할 때 호출하여 핸들러 함수를 동적으로 빌드할 것입니다. 그리고 그 시점에서 제가 구성한 웹앱 컴포넌트를 닫을 수 있습니다.
So this make-handler function, I'll call it when I'm starting up the application to build up the handler function dynamically. And, at that point, it can close over a web-app component that I've constructed.

따라서 제티 또는 네티를 사용하는 웹 서버 컴포넌트가 있을 수 있습니다.
So then I might have a Web server component that uses jetty or netty or whatever my Web server is.

그리고 이를 시작할 때 서버 인프라가 사용할 라우트 핸들러 함수를 실제로 생성하는 함수를 호출할 것입니다. 이제 이 예제에서는 web-app이라는 하나의 컴포넌트가 있고 이것이 전체 웹 애플리케이션을 대표한다고 가정했습니다. 다른 모든 요소에 따라 달라질 수도 있고 그렇지 않을 수도 있습니다. 하지만 다른 방식으로 할 수도 있습니다.
이것은 매우 개방적입니다. 애플리케이션의 모든 경로마다 다른 컴포넌트를 사용할 수 있습니다. 이는 API 유형 서비스에 적합할 수 있습니다. 5월 애플리케이션에서 경로의 하위 집합마다 다른 구성 요소를 가질 수 있습니다. 원하는 것이 무엇이든, 적절한 지점에서 사용할 수 있는지 확인하고 호출 스택에 주입하기만 하면 됩니다.
And when I'm starting that, I will call the function that actually creates the route handler function that the server infrastructure is going to use. Now in this example, I have assumed there is one component called web-app, and it represents my entire Web application. It might end up depending on everything else, or it might not. But I could do it different ways.
This is very open. I could have a different component for each and every route in my application. That might make sense for an API type service. I could have different components for different subsets of routes in may application. Whatever I want to do, I just have to make sure they're available at the right point and inject them into the call stack.

따라서 이 프레임워크로 할 수 있는 모든 종류의 트릭이 있습니다. 제가 만든 이 프레임워크의 코드 양은 아주 적습니다. 그저 지도를 섞어 놓은 것뿐입니다. 그다지 많지 않죠. 하지만 자신만의 라이프사이클 함수를 정의하는 등의 작업을 할 수 있습니다.
So there are all sorts of tricks that you can do with this. The amount of code in this framework I've created is tiny. It's really just shuffling maps around. There's not a lot to it. But you can do things like define your own lifecycle functions.

컴포넌트의 종속성 이름을 바꿀 수 있습니다. 제 예제에서는 DB와 이메일이 시스템에서 고객 컴포넌트와 동일한 이름을 가졌지만, 꼭 그렇게 할 필요는 없습니다. 시스템과 컴포넌트에서 다른 이름을 사용하고 이름이 어떻게 바뀌는지 매핑을 보여줄 수 있습니다.
You can rename the dependencies of a component. In my example, DB and email had the same name in the system that they had in the customers component, but that doesn't have to work that way. I could use different names in the system and the component and show the mapping of how they get renamed.

이 프레임워크가 다루지 않는 한 가지는 런타임 상태 변경입니다. 전체 시스템을 불러올 수 있고 전체 시스템을 종료할 수 있지만 런타임에 일부만 변경할 수는 없습니다. 하지만 클로저에는 이미 이를 위한 완벽한 도구가 있습니다. 런타임에 변경 가능한 무언가가 필요하다면 변경 가능한 참조를 추가하세요. 컴포넌트 내부에 원자, 참조, 에이전트 또는 채널을 넣으면 런타임에 변경 사항을 표시할 수 있습니다.
One thing this framework does not deal with is runtime state changes. You can bring the whole system up, and you can shut the whole system down, but you can't change part of it at runtime. But Clojure has perfectly good tools for doing this already. If you need something to be mutable at runtime, add a mutable reference. Put an atom or a ref or an agent or a channel inside your component, and that can exhibit change at runtime.

또 한 가지 언급해야 할 것은 시스템 자체가 구성 요소라는 점입니다. 이들은 모두 동일한 속성을 따르기 때문에 이론적으로는 중첩된 시스템으로 시스템을 구성할 수 있습니다. 실제로 이런 사용 사례를 찾아본 적이 없고 좋은 생각인지도 모르겠지만, 실제로 이렇게 하고 싶은 상황이 있을 수도 있습니다. 저는 일반적으로 시스템이 모두 평평하고 모든 구성 요소가 동일한 레벨에 있으면 더 쉽다고 생각합니다.
Another thing I should mention is that systems are themselves components. They obey all the same properties, so in theory you could compose systems of systems that are nested. Now I've actually never found a use case for this, and I'm not even sure it's a good idea, but maybe there's some situation where you'd actually want to do this. I generally find it easier if the systems are all flat and all the components live at the same level.

자신만의 수명 주기를 만들고 싶으시다면 여기에 예제가 있습니다. 예를 들어 Java에서 초기화, 시작, 중지, 삭제와 같은 네 가지 수명 주기 메서드를 정의하는 일부 API를 본 적이 있습니다.
자신만의 라이프사이클을 정의하는 것은 매우 쉽습니다. 자신만의 SystemMap 버전을 제공하기만 하면 됩니다. 프로토콜이든 다중 메서드든 라이프사이클 함수를 정의하고 모든 컴포넌트에 구현한 다음, 올바른 방식으로 이를 호출하는 고유한 버전의 SystemMap을 제공하면 됩니다.
So here's an example if you wanted to make your own lifecycle. I've seen some APIs in Java, for example, that define four lifecycle methods like init, start, stop, and destroy.
Defining your own lifecycle is very easy. You just need to provide your own version of SystemMap. You need to define your lifecycle functions, whether they're protocols or multi-methods and implement them on all your components, and then provide your own version of SystemMap that calls them in the right way.

그리고 업데이트-시스템과 업데이트-시스템-리버스 두 가지 헬퍼를 사용할 수 있습니다. 제가 작성한 컴포넌트 라이브러리가 실제로 시스템에서 시작과 중지를 구현하는 방식입니다. update-system은 사용자가 전달한 임의의 함수를 받아 종속성 순서대로 각 컴포넌트에서 호출하면서 동시에 종속성 연결을 수행합니다. update-system-reverse도 같은 작업을 수행합니다. 단지 종속성 순서가 역순일 뿐입니다.
And there you can make use of these two helpers: update-system and update-system-reverse. This is how the component library I've written actually implements start and stop on systems. update-system just takes any arbitrary function you pass it and calls it on each component in dependency order while doing the associng in of dependencies at the same time. update-system-reverse does the same thing. It just goes in reverse dependency order.

그래서 이것은 매우 간단합니다. 지도만 있으면 되기 때문에 실제로 작업을 시작하고 나서 이 시스템으로 할 수 있는 일을 발견했습니다. 가장 재미있게 발견한 것 중 하나는 두 개의 시스템 맵을 가져와 병합할 수 있다는 점이었습니다. 서로 다른 시스템이 두 개, 세 개, 많게는 몇 개나 있는 애플리케이션을 서로 다른 머신에서 프로덕션에 배포한다고 가정하면 실제로는 서로 다른 프로세스에서 실행될 것입니다. 하지만 단일 프로세스에서 로컬로 테스트하고 싶다면 이들을 병합하면 됩니다.
So this is very simple. It's just maps, which means I actually discovered things I could do with these systems after I'd started working with them. One of the most fun for me to discover was that I could take two system maps and merge them. If I have an application that has two, three, however many different systems, and let's say I'm going to deploy them to production on different machines, they're actually going to be running in different processes. But if I want to test them locally in a single process, I could just merge them together.

시스템은 기록이라는 사실을 기억하세요. 기록은 맵입니다. 두 맵에서 병합을 호출하면 두 맵의 모든 콘텐츠가 포함된 더 큰 맵을 얻을 수 있습니다.
Remember, systems are records. Records are maps. I can call merge on two maps and get a bigger map that has all the contents of both.
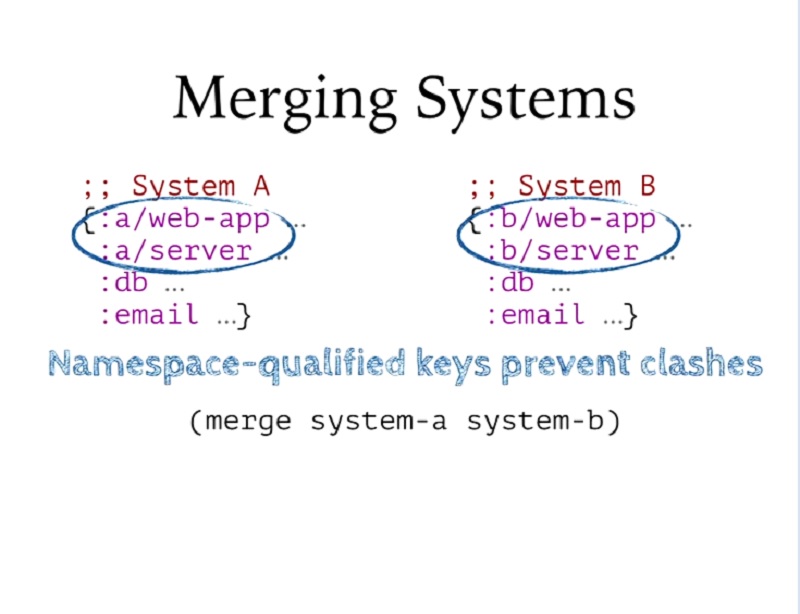
그리고 그렇게 할 것이라는 것을 알고 있다면 다른 시스템에서 서로 다른 구성 요소에 이름 공간 한정 키를 사용한 다음 재사용할 구성 요소에 동일한 이름을 사용할 수 있습니다.
And if I know I'm going to do that, I can use name space qualified keys for the components that are different in the different systems and then use the same names for components that are going to be reused.
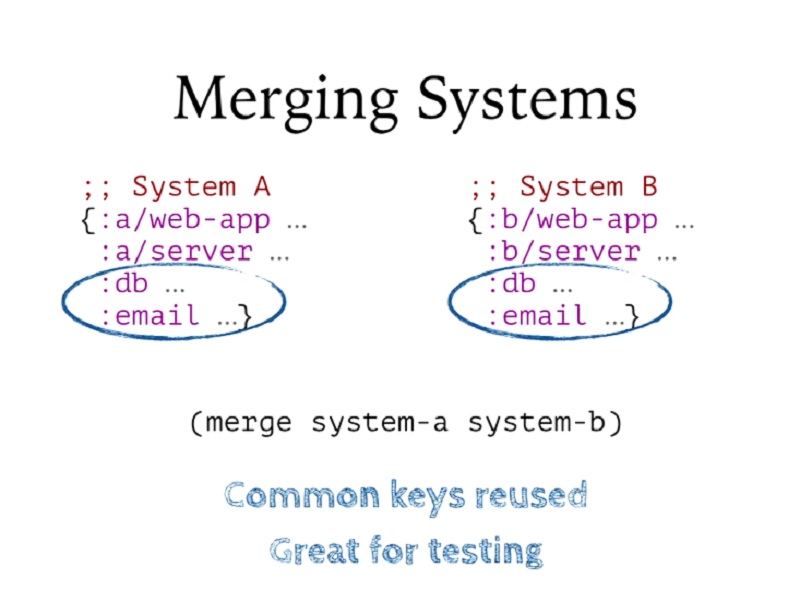
테스트할 때 정말 환상적입니다. 이제 코드나 런타임 상태를 복제하지 않고도 두 개의 서로 다른 애플리케이션을 실제로 실행하는 시뮬레이션을 할 수 있습니다.
This is fantastic for testing. Now I can actually simulate running two different applications without duplicating any of the code or any of the runtime state that I need to use them.

앞서 말했듯이 이것은 많은 코드가 아닙니다. 아마 여러분 모두 집에 돌아가서 제가 설명한 것만 보고 직접 작성할 수 있을 것입니다. 하지만 몇 가지 장점이 있는데, 가장 큰 장점은 코드의 여러 부분 사이의 경계에 대해 생각하게 만든다는 점입니다. 이 코드가 무엇을 해야 할까요? 서비스 및 상태 측면에서 무엇을 사용해야 할까요?
이렇게 하면 실제로 코드를 테스트하고 리팩터링하기가 더 쉬워지며, 심지어 프로그램의 일부를 다른 프로그램으로 분리할 수도 있습니다. 실제로 이 기법을 사용하여 큰 모놀리식 애플리케이션을 작은 조각으로 분할한 적이 있습니다.
So like I said, this is not a lot of code. You could probably all go home and write this yourselves just from the description that I've given here. But it does have some real advantages, the biggest one being it forces you to think about the boundaries between different parts of your code. What does this piece of code need to do? What does it need to use in terms of services and state?
Doing this actually makes it easier to test and refactor your code and possibly even separate pieces of a program into different programs. I've actually used this technique to take a big monolithic application and split it up into smaller pieces.

또 다른 장점은 종속성 순서를 자동으로 지정한다는 점입니다. 더 이상 어떤 컴포넌트가 다른 컴포넌트보다 먼저 시작될지 고민할 필요가 없습니다. 라이브러리에 이 기능이 내장되어 있기 때문입니다. 라이브러리는 사용자가 선언한 관계에 따라 자동으로 수행합니다.
Another advantage is it takes the ordering of dependencies and makes it automatic. You no longer need to think about which component gets started before which other thing. That's built into the library. It does it automatically based on the relationships that you declare.

앞서 살펴본 것처럼, 다른 구현으로 교체하는 것은 매우 쉽습니다. 맵에 연결하기만 하면 됩니다. 이보다 더 쉬울 수는 없습니다.
As we've seen, it's very easy to swap in alternate implementations. All you have to do is assoc onto a map. It's hard to get much easier than that.

그리고 컴포넌트 내에서 모든 것이 기껏해야 맵 조회 한 번이면 가능하다는 것을 알 수 있습니다. 우리가 호출해야 하는 함수는 모두 로컬에 있습니다. 하지만 컴포넌트에 새로운 종속성을 추가하는 것은 쉽습니다. 선언된 종속성 집합에 새 키를 추가하기만 하면 됩니다.
And then, within a component, we know that everything is, at most, one map lookup away. Everything is local in any given function that we need to call. But adding a new dependency into a component is easy. We just add a new key to its declared set of dependencies.

아직 완벽하지는 않습니다. 이것이 앱을 작성하는 유일한 방법이라고 주장하지는 않겠습니다. 그리고 한 가지 큰 단점이 있는데, 이 패턴을 사용하려면 이 모델을 중심으로 전체 앱을 구축해야만 제대로 작동한다는 것입니다. 즉, 애플리케이션의 작은 부분에만 이 패턴을 사용하면 대부분의 이점을 얻지 못합니다. 그리고 이 모델을 모든 곳에서 사용하기 위해 기존 애플리케이션을 리팩터링하는 것은 꽤 많은 작업이 필요하지만, 그렇게 하면 향후 애플리케이션을 테스트하고 리팩터링하기가 더 쉬워집니다.
Now it's not perfect. I'm not going to claim this is the only way to write apps. And it has one big disadvantage, which is that if you're going to do this, it really only works if you build your entire app around this model. It is, if you only use this pattern in one small part of your application, you won't get most of the benefits. And it's quite a lot of work to refactor an existing application to use this model everywhere, although I have done it, and it does then make the application easier to test and refactor in the future.

또 한 가지, 이건 좀 귀찮은 이야기지만 사방에 작은 지도가 많이 쌓이게 됩니다. 기록일 수도 있고 기록일 수도 있고 지도일 수도 있습니다. 같은 방식으로 작동하지만 결국에는 많은 파괴 작업을 수행하게 될 것입니다. 거의 모든 API 함수는 상단에 있는 컴포넌트 맵에서 일부 항목을 파괴하게 됩니다. 저는 개인적으로 신경 쓰이지 않습니다. 어떤 사람들은 이 때문에 짜증을 내기도 합니다. 매크로를 사용하면 어느 정도 완화할 수 있지만, 제 생각에는 매크로로 인한 복잡성 증가는 매크로를 통해 절약할 수 있는 적은 양의 타이핑에 비해 가치가 없다고 생각합니다.
Another thing is, and this is kind of just a nuisance, you end up with lots of these little maps everywhere. They could be records. They could be maps. It works the same way, but you're going to end up doing a lot of destructuring. Almost every API function will be destructuring some stuff out of its component map at the top. This doesn't bother me personally. Some people get irritated by it. You could mitigate it somewhat with macros, although I think, again, in my opinion, the added complexity of macros is not worth the small amount of typing you'd save by doing that.

제가 겪은 또 다른 문제는 시스템 맵을 시작하고 나면 맵이 상당히 커진다는 것입니다. 반복되는 부분이 많죠. 모든 컴포넌트가 맵의 여러 위치에서 반복될 수 있습니다. 메모리 관점에서 보면 모두 동일한 영구 데이터 구조이기 때문에 괜찮지만, 이 맵을 인쇄하거나 로깅해서 보고 정확한지 확인할 수 없다는 뜻입니다.
Another thing I've run into is that the system map, after you've started it, ends up being quite large. It has a lot of repetition. Every component may be repeated at multiple places in the map. Now that's fine from a memory point of view because they're all the same persistent data structure, but it means you can't just print this thing out or log it and expect to be able to look at it and see that it's correct.

앞서 언급했듯이 또 다른 한계는 전체 시스템에서만 한 번에 작동한다는 것입니다. 제가 작성한 라이브러리에는 시스템의 일부만 시작하거나 중지할 수 있는 기능이 없습니다. 따라서 전체 프로그램이 계속 실행되는 동안 이 라이브러리를 런타임 도구로 사용하여 시스템의 다른 부분을 실행하거나 중지하는 것은 상상할 수 없습니다. 그러려면 매우 다른 모델이 필요합니다. 아마도 더 많은 가변성이 내장되어 있어야 할 것입니다.
Another limitation, as I mentioned, is that this only works for the whole system at once. There is no facility in this library, as I've written it, to start or stop just a subset of the system. So you couldn't imagine -- you couldn't use this as a runtime tool to bring different parts of a system up and down while the whole program continues to run. That would require a very different model. It would probably have to have more mutability built into it.

마지막으로, 약간의 상용구가 있습니다. 생성자 함수를 작성해야 합니다. 메타데이터를 선언해야 합니다. 그다지 많지 않다고 생각합니다. 여기에는 작성해야 하는 XML 구성이 없으므로 매우 쉽습니다.
And, finally, there's a little bit of boilerplate. You have to write constructor functions. You have to declare metadata. I don't think it's very much. You know, there's no XML configuration here that you have to write, so it's pretty easy.

그리고 우리는 시간의 끝에 도달했습니다. 저기 도서관이 있습니다. 가져갈 수 있어요. 궁금한 게 있으면 물어보세요. 끝까지 함께 해주셔서 감사합니다.
[청중 박수]
And we've reached the end of our time. There's the library. You can get it. You can pester me with questions. And thank you all for sticking around.
[Audience applause]