# Transducers
- Speaker: Rich Hickey
- Conference: Strange Loop 2014 (opens new window) - Sept 2014
- Video: https://www.youtube.com/watch?v=6mTbuzafcII (opens new window)
# 참고: Clojure의 Transducer란?
Clojure의 Transducers는 입력 및 출력 소스와 독립적인 조합 가능한 알고리즘 변환기입니다. Transducers는 입력이나 출력 소스의 컨텍스트에서 독립적이며, 개별 원소 측면에서의 변환에 대한 본질만을 지정합니다. Transducers는 collections, streams, channels, observables, etc.와 같은 다양한 프로세스에 사용될 수 있습니다.
Transducers는 reduce 함수를 사용하여 정의할 수 있습니다. reduce 함수는 누적된 결과와 새로운 입력을 받아 새로운 누적된 결과를 반환하는 함수입니다. Transducer는 reduce 함수의 변환입니다. Transducer는 입력 및 출력 소스의 컨텍스트에서 독립적이며, 개별 원소 측면에서의 변환에 대한 본질만을 지정합니다.
Transducers는 collections, streams, channels, observables, etc.와 같은 다양한 프로세스에 사용될 수 있습니다. Transducers는 입력 및 출력 소스의 컨텍스트에서 독립적이기 때문에, 이러한 프로세스에 쉽게 적용할 수 있습니다.

# What are They?

물론 껍질이 겉에 있든, 위에 있든, 모든 것이 같은 재료의 조합일 뿐입니다. 여기서 새로움을 주장하는 것이 아니라 평소와 똑같은 재료를 재배치한 것에 불과합니다. 하지만 가끔은 치즈가 안에 있을 때보다 위에 있는 것이 더 맛있을 때가 있잖아요.
Of course, everything is just some combination of the same ingredients, the shell's on the outside, on the top, whatever. I'm not claiming any novelty here, it's just another rearrangement of the same old stuff as usual. But you know, sometimes, the cheese on top, you know, tastes better than when it's inside.
# What are They?
그렇다면 트랜스듀서란 무엇일까요? 기본적인 아이디어는 맵과 필터를 다시 살펴보고 그 안에 맵과 필터보다 더 재사용할 수 있는 아이디어가 있는지 확인하는 것입니다. 맵과 필터는 다양한 컨텍스트에서 반복해서 구현되는 것을 볼 수 있기 때문입니다. 컬렉션에 맵과 필터가 있습니다. 스트림에 맵과 필터가 있습니다. 통합 가시성에도 맵과 필터가 있습니다. 우리는 채널에 맵과 필터 등을 작성하기 시작했습니다. 여기에는 공유가 없었고 재사용 가능한 것을 만들 수 있는 기능도 없었습니다. 그래서 우리는 본질을 꺼내서 재사용할 수 있는지 알아보고 싶었습니다. 이를 위한 방법은 프로세스 변환으로 리캐스팅하는 것입니다. 이에 대해서는 더 자세히 설명하겠지만, 본질적으로 이것이 전체 아이디어입니다. 이러한 시퀀스 처리 함수의 핵심 로직을 프로세스 변환으로 리캐스트한 다음, 이러한 변환을 호스팅할 수 있는 컨텍스트를 제공하는 것입니다.
Alright, so, what are transducers? The basic idea is to go and look again at map and filter and see if there's some idea inside of them that could be made more reusable than map and filter, because we see map and filter being implemented over and over again in different contexts, right? We have map and filter on collections. We have map and filter on streams. We have map and filter on observables. We were starting to write map and filter, and so on, on channels. And there was just no sharing here, there's no ability to create reusable things. So we want to take the essence out and see if we can reuse them. And the way that we are going to do that is by recasting them as process transformations. And I'll talk a lot more about that, but that's essentially the entire idea. Recasting the core logic of these sequence processing functions as process transformations, and then providing context in which we could host those transformations.
# What Kind of Processes?

프로세스에 대해 이야기할 때 무엇을 말하는 걸까요? 모든 종류의 프로세스가 이런 식으로 모델링할 수 있는 것은 아니지만, 모델링할 수 있는 프로세스는 무수히 많습니다. 그렇죠? 여기서 중요한 것은 프로세스를 일련의 단계로 모델링할 수 있다는 것이죠? 그리고 한 단계에 대해 이야기하거나 한 단계를 입력, 일부 입력, 단일 입력을 받아들이거나 흡수하는 것으로 생각할 수 있다면 말입니다. 즉, 어떤 일이 진행 중이고 입력이 있으면 그 입력을 진행 중인 일에 흡수하고 계속 진행하는 것입니다. 이러한 프로세스에 트랜스듀서를 사용할 수 있습니다. 그렇게 생각하면 컬렉션을 구축하는 것은 이러한 형태의 프로세스의 한 인스턴스일 뿐입니다. 컬렉션을 구축한다는 것은 지금까지의 컬렉션이 있고, 새로운 입력이 있으며, 새로운 입력을 컬렉션에 통합하고 계속 진행하는 것입니다. 하지만 이는 아이디어의 전문화입니다. 일반적인 아이디어는 시드 왼쪽 감소라는 개념입니다. 새로운 것을 만들어서 계속 쌓아 올리는 것을 말합니다. 하지만 우리는 환원이 특정 무언가를 만들어내는 것이라는 생각에서 벗어나 하나의 프로세스라는 점에 더 집중하고자 합니다. 어떤 프로세스는 특정한 것을 만들지만, 어떤 프로세스는 무한히 실행되는 무한한 프로세스도 있습니다.
So when I talk about processes, what am I saying? It's not every kind of process, there are all kinds of processes that cannot be modeled this way, but there are ton of processes that can. Right? And the critical words here are that if you can model your process as a succession of steps, right? And if you can talk about a step or think about a step as ingesting an input, as taking in or absorbing some input, a single input. So something going on, there's an input, we're going to absorb that input into the something going on and proceed. That's the kind of process that we can use transducers on. And when you think about it that way, building a collection is just one instance of a process with that shape. Building a collections is, you have a collection so far, you have the new input, and you incorporate the new input into the collection and you keep going. But that's a specialization of the idea. The general idea is the idea of a seeded left reduce. Of taking something that you're building up in a new thing and continually building up. But we want to get away from the idea that the reduction is about creating a particular thing and focus more on it being a process. Some processes build particular things; other processes are infinite, they just run indefinitely.
# Why 'transducer'?

그래서 우리는 단어를 만들어 냈습니다. 사실 단어를 만든 게 아닙니다. 다시 말하지만, 이것은 실제로 단어입니다. 그런데 왜 이 단어일까요? 우리는 이 단어가 이미 프로그래밍 단어인 reduce와 관련이 있다고 생각합니다. 또한 이미 일반 단어이기도 합니다. 그리고 일반 단어는 무언가를 되돌리다라는 뜻입니다. 이 단어는 시간이 지남에 따라 무언가를 낮추거나 더 작게 만드는 것을 의미하게 되었습니다. 반드시 그런 의미는 아닙니다. 그것은 단지 어떤 모선으로 되돌아가는 것을 의미하며, 이 경우에는 우리가 달성하려는 프로세스라고 말할 것입니다. 수집이라는 단어는 무언가를 가져온다는 뜻이므로 같은 개념이지만 1바이트 정도에 불과하죠? 환원은 일련의 것들에 관한 것이고, 인제스트는 하나의 것으로 수집하는 것입니다. 그리고 트랜스듀스는 이어진다는 뜻입니다. 기본적으로 이 환원에 입력을 받는 과정에서 일련의 변환을 통해 입력을 유도한다는 개념입니다. 일련의 기능에 걸쳐 이를 전달할 것입니다. 환원 과정에서 입력을 조작하는 것에 대해 이야기하겠습니다.
So, we made up words. Actually we didn’t make up a word. Again, this is actually a word. But why this word? We think it's related to reduce and reduce is already a programming word. It's also already a regular word. And the regular word means to lead back, like, to bring something back. The word has come to mean over time to bring something down or to make something smaller. It doesn't necessarily mean that. It just means to lead it back to some mother-ship, and in this case, we're going to say, the process that we're trying to accomplish. The word ingest means to carry something into, so it's the same kind of idea, but that's about one byte, right? Reduction is about a series of things and ingestion ingests itself into one thing. And transduce means to lead across. And the idea basically is: as we're taking inputs into this reduction, we're going to lead them through a series of transformations. We're going to carry them across a set of functions. We're going to be talking about manipulating input during a reduction.
# Transducers in the Real World

따라서 이것은 프로그래밍이 아닙니다. 이것은 우리가 현실 세계에서 항상 하는 일이며, 트랜스듀서라고 부르지 않고 지침이라고 부릅니다. 따라서 이 강연을 통해 '수하물을 비행기에 싣기'라는 시나리오에 대해 이야기하겠습니다. 이것이 우리가 하고 있는 전반적인 작업이지만, 수하물에 대해 제가 하고 싶은 변형이 있습니다. 수하물을 비행기에 싣는 동안 팔레트를 분해해 주세요. 팔레트에는 짐이 쌓여 있는 커다란 나무로 된 물건이 수축 포장되어 있습니다. 이제 짐을 하나하나 분리해서 짐을 분리할 거예요. 각 가방의 냄새를 맡아서 음식 냄새가 나는지 확인합니다. 음식 냄새가 나면 비행기에 싣고 싶지 않으니까요. 그런 다음 가방을 들고 무겁지 않은지 확인합니다. 그리고 라벨을 붙이고 싶어요. 그게 우리가 해야 할 일이죠. 수하물 처리 담당자에게 "그렇게 하려고 합니다"라고 말합니다. 그러면 모두 "좋아요, 그렇게 할 수 있어요"라고 말합니다.
So this is not a programming thing. This is a thing we do all the time in the real world; we don't call them transducers, we call them instructions. And so, we'll talk about this scenario through the course of this talk, which is, 'put the baggage on the plane'. That's the overall thing we're doing, but I have this transformation that I want you do to the baggage. I want you to, while you're doing it, while you are putting the baggage on the plane, break apart the pallets. We're going to have pallets, you know, big wooden things with a pile of luggage on it that's sort of shrink-wrapped. We're going to break them apart so now we have individual pieces of luggage. We want to smell each bag and see if it smells like food. If it smells like food, we don't want to put it on the plane. And then we want to take the bags and see if they are heavy. And we want to label them. That's what we have to do. We're talking to the luggage handlers, we say, "That's what you are going to do". And they all say, "Great, I can do that".
# Conveyances, sources, sinks are irrelevant

방금 말씀드린 방식과 수하물 취급자, 자녀, 그 밖에 지시를 내려야 하는 모든 사람에게 말하는 방식에서 정말 중요한 것 중 하나는 운반 수단과 출처 및 싱크대가 그 과정의 출처와 싱크대와 무관하다는 것입니다. 수하물 취급자에게 가방을 컨베이어 벨트에 올려놓으라고 하나요, 트롤리에 올려놓으라고 하나요? 우리는 말하지 않았습니다. 신경 쓰지 않습니다. 사실, 정말 신경 쓰고 싶지 않습니다. 수화물 직원들에게 "오늘은 카트에 짐이 있을 테니 이렇게 하고 다른 카트에 실어"라고 말하고 싶지 않거든요. 그리고 내일 컨베이어 벨트로 전환할 때는 "어떻게 해야 할지 몰랐어요"라고 말하게 하세요. "컨베이어 벨트에 실려 왔는데....... 카트에 대한 규칙이 있어요". 규칙은 상관없습니다. 지침도 상관없습니다. 이것이 현실 세계입니다.
One of the really important things about the way that was just said, and the way you talk to luggage handlers and your kids and anybody else you need to give instructions to, is that the conveyance and the sources and the sinks of that process are irrelevant. To the luggage handlers, get the bags on the conveyor belt or on a trolley? We didn't say. We don't care. In fact, we really don't want to care. We don't want to say to the luggage guys, "Today, there's going to be luggage on the trolley, do this to it and put it on another trolley". And tomorrow when we switch to conveyor belts, have them say, "We didn't know what to do". "It came on a conveyor belt and like, you didn't.. I have rules for trolleys". So the rules don't care. The instructions don't care. This is the real world.
# Transformation in the Programming World

그리고 프로그래밍이 있습니다. 프로그래밍에서는 무엇을 할까요? 컬렉션 함수를 구성합니다. 정말 멋져요. 리스트가 있죠. 리스트와 리스트 사이의 함수가 있죠. 그래서 함수를 구성할 수 있습니다. 무거운 가방에 라벨을 붙이는 것은 매핑과 같다고 할 수 있습니다. 모든 가방이 들어올 때마다 라벨이 붙을 수도 있고 붙지 않을 수도 있지만, 들어오는 모든 가방에 대해 나오는 가방이 있습니다. 라벨이 붙어 있을 수도 있고 붙어 있지 않을 수도 있죠. 식품이 아닌 봉투를 꺼내거나 식품이 아닌 봉투를 보관하는 것이 필터입니다. 필터에 비유할 수 있습니다. 음식이면 원하지 않습니다. 음식이 아니라면 보관할 것입니다. 따라서 이 술어에 따라 입력이 있을 수도 있고 없을 수도 있습니다. 그리고 팔레트 풀기는 맵캣과 같습니다. 팔레트가 주어지면 개별 수하물 조각을 모두 제공하는 함수가 있습니다. 그래서 우리는 이미 이 작업을 수행하는 방법을 알고 있습니다. 다 끝났어요, 다 끝났어요. 프로그래밍은 현실 세계를 모델링할 수 있습니다. 다만 방금 설명한 것과 현실 세계에서 일어나는 일에는 큰 차이가 있습니다.
Then we have programming. What do we do in programming? We have collection function composition. We're so cool. We have lists. We have functions from lists to lists. So we can compose our functions. We're going to say, well, labeling the heavy bags is like mapping. Every bag comes through and it gets a label or doesn't but for every bag that comes through, there's a bag that comes out. Maybe it has a label or it doesn't. And taking out the non-food bags or keeping the non-food bags is a filter. It's analogous to filter. If it's food, we don't want it. If it's not food, we are going to keep it. So we may or may not have an input depending on this predicate. And unbundling the pallets is like mapcat. There's some function, that given a pallet, gives you a whole bunch of individual pieces of luggage. So we already know how to do this. We're done, we're finished. Programming can model the real world. Except there's a big difference between this and what I just described happens in the real world.
# Conveyances are everywhere

맵은 컬렉션에서 컬렉션으로, 또는 시퀀스에서 시퀀스로 변환되는 함수이기 때문입니다. 프로그래밍 언어에 따라 다르지만 기본적으로 집계와 집계의 함수입니다. 필터도 마찬가지고 맵캣도 마찬가지입니다. 그리고 우리가 가진 규칙은 그런 것들에서만 작동합니다. 그런 것들과는 독립적이지 않습니다. 채널이나 스트림, 관찰 가능 항목과 같은 새로운 항목이 생기면 우리가 가진 규칙 중 어떤 것도 거기에 적용되지 않습니다.
Because map is a function from whatever, collection to collection or sequence to sequence. Pick your programming language, but it’s basically a function of aggregate to aggregate. And so is filter and so is mapcat. And the rules that we have only work on those things. They are not independent of those things. When we have something new like channel or stream or observable, none of the rules we have apply to that.
# Trolleys
그리고 그 사이에 이 모든 것들이 있습니다. 마치 수하물 직원에게 "카트에서 모든 것을 내려서 팔레트를 풀어서 다른 카트에 올려놓으세요. 그리고 그 카트에서 꺼내세요. 그리고 음식 냄새가 나는지 확인합니다. 냄새가 나지 않으면 다른 카트에 올려놓습니다. 그리고 그 카트에서 내려서 무거우면 라벨을 붙이고 다른 카트에 올려놓습니다." 이것이 바로 우리가 프로그래밍에서 하는 일입니다. 이것이 우리가 항상 하는 일입니다. 그리고 우리는 충분히 똑똑한 감독자가 와서 "너희들 뭐하는 거야?"라고 말할 때까지 기다립니다. 그래서 우리는 더 이상 이런 일을 하고 싶지 않습니다.
And in addition, we have all this in-between stuff. It is as if we said to the luggage guys, "Take everything off the trolley, right, and unbundle the pallet and put it on another trolley. And take it off that trolley. And see if it smells like food. And if it doesn't, put it on another trolley. And then take it off that trolley, and if it's heavy, put a label on it and put it on another trolley". This is what we're doing in programming. This is what we do all the time. And we wait for a sufficiently smart supervisor to come and like, say, "What are you guys doing?". So we don't want to do this anymore.


재사용이 전혀 없습니다. 이 작업을 수행할 때마다 새로운 것을 작성하게 됩니다. 새로운 종류의 스트림을 작성하면 새로운 함수 집합이 생깁니다. 우리가 발명하면 100개의 함수가 생깁니다. 이 작업을 클로저에서 시작했어요. 채널이 생겼고 맵과 필터를 다시 작성하기 시작했습니다. 이제 타임아웃을 선언해야 할 때입니다. 할 수 있을까요? 두 가지 일이 있었기 때문입니다. 하나는 우리가 하고 있는 모든 일이 구체적이라는 점입니다. 다른 하나는 잠재적인 비효율성이 있다는 것입니다. 충분히 똑똑한 컴파일러가 있다면 상황에 따라 중간 과정을 생략할 수 있을지도 모릅니다. 그렇지 않을 수도 있습니다. 문제는 우리의 초기 문장이 우리가 일반적으로 하는 방식과 정말 맞지 않는다는 것입니다. 일반적이지 않고 구체적입니다. 우리는 이 문제를 해결하기 위해 다른 것에 의존할 것입니다.
We don't have any reuse. Every time we do this, we end up writing a new thing. We write a new kind of stream, we have a new set of these functions. We invent.. rx, boom, there's a 100 functions. We were starting to do this in Clojure. We had channels and we are starting to write map and filter again. So, it's time to say, time out. Can we do this? Because there are two things that happened. One is, all the things we are doing are specific. And the other is, there's a potential inefficiency here. Maybe there's sufficiently smart compilers, and maybe for some context, they can make the intermediate stuff go away. Maybe they can’t. The problem is our initial statement really doesn't like what we normally do. It's not general, it's specific. We'll rely on something else to fix it.
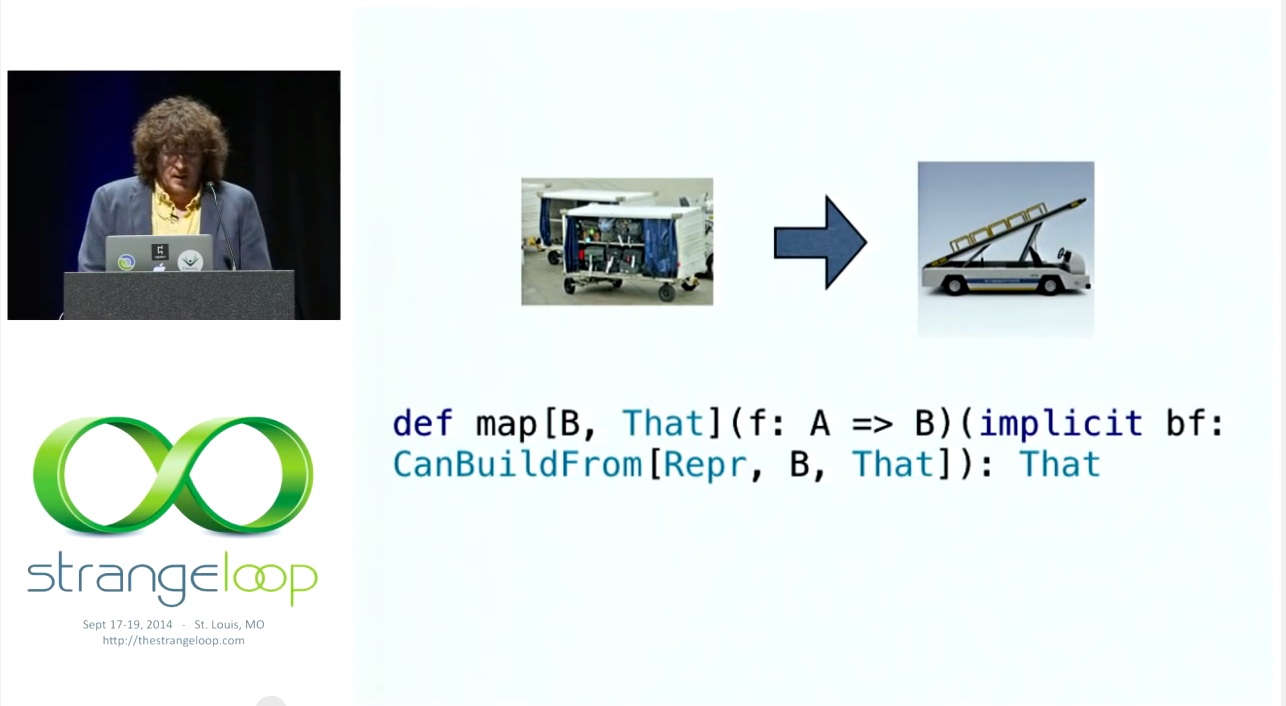
또한 한 종류의 운송 수단에서 다른 종류의 운송 수단으로 이동하려고 할 때 갑자기 지도가 X에서 X로 바뀌는 문제도 있습니다. 이 문제를 어떻게 해결할 수 있을까요? 물론 모두가 무슨 생각을 하는지 잘 알고 있습니다.
We also have this problem, when we are going to go from one kind of conveyance to another, and now all of a sudden, you know, map is from x to x. How do we fix this? And I know what everyone's thinking, of course.
[웃음, 박수]
[laughter, applause]
네. 따라서 이 중 일부는 해결될 수 있지만 일반적으로 문제가 해결되지는 않습니다. 문제는 대부분 우리가 전체 작업에 대해 이야기하고 있다는 사실에 있습니다. 그 지침은 단계에 관한 것이었습니다. 전체 작업에 관한 것이 아니었습니다. 전체 작업에 관한 것이었죠. 이 작업을 수행하는 동안 입력에 대해 수행할 작업은 다음과 같습니다. 이 작업을 하는 동안 더 큰 작업을 하는 동안 입력값을 어떻게 변환할지 설명합니다. 컨베이어 벨트에서 트롤리 등으로 바뀔 수 있습니다.
Yeah. So, that may fix some of this but in general it doesn't solve the problem. The problem is mostly about the fact that we are talking about the entire job. Those instructions, they were about the step. They weren't about the entire job. The entire job was around it. While are you doing this thing, here's what you going to do to the inputs. Here's how you are going to transform them while you're doing the bigger thing which could change. It could change from conveyor belts to trolleys and stuff like that.
# Stop talking about the entire job

그래서 저희는 다른 접근 방식을 취하고자 합니다. 단계에 대한 무언가가 있다면 전체 작업에 대한 무언가를 만들 수 있지만 그 반대의 경우는 불가능합니다.
So we want to just take a different approach. If we have something that's about the steps, we can build things that are about the whole jobs but not vice-versa.
# Creating Transducers

여기서는 몇 가지 사용법을 소개한 다음 자세한 내용은 조금 후에 설명하겠습니다. 반대로 설명하면 사람들은 "아, 머리가 너무 오래 아팠는데 40분 만에 그 모든 것을 가치 있게 만드는 것을 보여 주셨네요"라고 말합니다.
그래서 여기에 가치 제안이 있습니다. 우리는 이렇게 트랜스듀서를 만들면서 "트랜스듀서를 만들고 싶고, 일련의 지침을 만들고 싶습니다. 저는 이것을 프로세스 백이라고 부르겠습니다. 번들되지 않은 팔레트를 함수로 사용하여 맵캣팅 아이디어를 구성하겠습니다. 그래서 팔레트를 언번들링하고 싶습니다. 그런 다음 비식품을 걸러내거나 비식품을 보관하고 식품을 걸러내고 싶습니다. 그리고 무거운 가방에 라벨을 붙이는 지도를 만들고 싶습니다. 이 경우에는 클로저의 일반적인 함수 구성 기능인 comp를 사용하여 이러한 함수를 구성할 것입니다. 따라서 반환 트랜스듀서를 매핑, 필터링 및 매핑합니다. 그리고 이러한 것들의 구성인 프로세스 백은 그 자체로 트랜스듀서입니다. 따라서 맵카팅을 호출하고, 필터링을 호출하고, 매핑을 호출하고, 3개의 트랜스듀서를 가져와서 구성하고, 또 다른 트랜스듀서를 만들 것입니다. 각 트랜스듀서는 프로세스 단계, 환원 기능을 가져와서 변환하고 약간 변경합니다. 따라서 그 단계를 수행하기 전에 이 단계를 수행하세요. 왜 거꾸로 보이는지 잠시 후에 설명하겠습니다.
Ok, this is just going to be some usages here and then I'll explain the details in a little bit. Because when I do it the opposite way, people are like, "Oh, my brain hurt for so long and, like, 40 minutes in, you showed me the thing that made it all valuable".
So, here's the value proposition. We make transducers like this, we say, "I want to make a transducer, I want to make a set of instructions. I'm going to call it process-bags. I'm going to compose the idea of mapcatting using unbundled pallet as the function. So I want to unbundle the pallets. Then I want to filter out the non-food or keep the non-food, filter out the food. And I want a map labeling the heavy bags. And in this case, we are going to compose those functions with comp which is Clojure's ordinary function composition thing. So mapcatting, filtering and mapping return transducers. And process-bags, which is a composition of those things, is itself a transducer. So we are going to call mapcatting, call filtering, call mapping, get 3 transducers, compose them and make another transducer. Each transducer takes a process step, its reducing function, and transforms it, changes it a little bit. So, before you do that step, do this. I'll explain why that seems backwards in a little bit.
# Using Transducers

이러한 지침을 만들었으므로 완전히 다른 컨텍스트로 이동하여 재사용할 수 있습니다. 우리가 지원하는 여러 컨텍스트 중 첫 번째 버전의 Clojure에서는 트랜스듀서를 into에 지원합니다. 그리고 into은 컬렉션과 다른 컬렉션을 가져와서 다른 컬렉션에 넣는 Clojure의 함수입니다. 빌드프롬으로 다른 컬렉션을 흡수하는 방법을 알고 있는 객체 지향 컬렉션이 더 많은 대신에, 우리는 단지 into이라는 독립적인 것을 가지고 있지만 같은 아이디어입니다. 소스와 목적지가 다를 수 있습니다. 따라서 팔레트를 비행기에 붓고 싶지만 먼저 가방 변환 프로세스를 통해 팔레트를 가져갈 것입니다. 이것은 컬렉션 빌드입니다. into은 이미 클로저에 있는 함수이며, 트랜스듀서를 받는 arity를 추가했을 뿐입니다. 그런 다음 시퀀스가 있습니다. 시퀀스는 어떤 소스를 가져와서 그것으로 게으른 시퀀스를 만듭니다. 이제 시퀀스는 트랜스듀서를 추가로 가져와서 느리게 결과를 생성하면서 모든 소스에 대해 해당 변환을 수행합니다. 그래서 우리는 여기서 게으름을 얻을 수 있습니다. 트랜스듀서라는 함수가 있는데, 트랜스듀서가 필요하다는 점만 빼면 reduce와 비슷합니다. 트랜스듀서, 연산, 초기값, 소스가 필요하므로 트랜스듀서는 프로세스 백을 수정한 것으로, 잠시 후에 설명하겠습니다. 연산은 합이고 초기값은 0이며 소스는 팔레트입니다. 그렇다면 이 구성은 무엇을 할까요? 이 함수는 무엇을 할까요? 가방의 무게를 합산합니다. 모든 가방의 무게입니다. 멋지네요. 이미 가지고 있는 프로세스를 약간 수정하면 됩니다. 해당 지침 끝에 '가방 무게 측정'을 추가하면 됩니다. 그러면 숫자가 나오고 이 숫자에 더하기를 사용하여 합계를 만들 수 있습니다.
Having made those instructions, we can go into completely different contexts and reuse them. Amongst the several contexts that we are supporting, in Clojure in the first version, is supporting transducers in into. And into is Clojure's function that takes a collection and another collection and pours one into the other. Instead of having, you know, more object oriented collections that know how to absorb other collections with buildFrom, we just have a standalone thing called into but it's the same idea. Your source and destination could be different. So you want to pour the pallets into the airplane, but we're going to take them through this process bags transformation first. So, this is collection building. into is already a function in Clojure, we just added an additional arity that takes transducers. Then we have sequence. Sequence takes some source of stuff, and makes a lazy sequence out of it. Sequence now additionally takes a transducer, and will perform that transformation on all the stuff as it lazily produces results. So we can get laziness out of this. There's a function called transduce which is just like reduce except it also takes a transducer. So that takes a transducer, an operation, an initial value and a source so the transducer is a modification of process bags -- we'll talk about in a second. The operation is sum, the initial value is 0 and the source are the pallets. So what does this composition do? What is this going to do? It's going to sum the weight of the bags. It's the weight of all the bags. So, it's cool. We can take the process we already have and modify it a little bit. We can add 'weighing the bags' at the end of that set of instructions. And that gives us a number and we can use that number with plus to build a sum.
이것이 바로 트랜스듀스입니다. 우리가 할 수 있는 또 다른 일은 이제 완전히 다른 맥락으로 이동하는 것입니다. 그래서 우리는 몇 가지 채널을 가지고 있습니다. 우리는 채널을 통해 수하물 팔레트를 보낼 것입니다. 실제로는 맞지 않지만 아이디어는 있습니다. 이것은 매우 다른 맥락입니다. 채널은 무기한으로 운영됩니다. 항상 물건을 공급하고 다른 쪽 끝에서 물건을 지속적으로 가져올 수 있습니다. 하지만 여기서 중요한 것은 이러한 것들이 매개변수화되지 않는다는 것입니다. '트롤리인지 컨베이어 벨트인지 나중에 알려줄 수 있는 물건'이 아닙니다. 이것은 제가 여기서 정의한 것과 똑같은 프로세스 백으로, 완전히 다른 맥락에서 재사용되는 구체적인 물건입니다. 따라서 이것은 매개변수화가 아니라 구체적인 재사용입니다. 따라서 채널에 트랜스듀서를 사용할 수 있습니다. 이제 채널 생성자가 선택적으로 트랜스듀서를 가져와서 흐르는 모든 것을 트랜스듀싱합니다. 자체 내부 처리 단계가 있으며, 주어진 트랜스듀서에 따라 입력을 적절히 수정할 것입니다. 그리고 개방형 시스템이기 때문에 상상할 수는 있지만 구현할 시간이 없었기 때문에 이것을 RxJava에 간단하게 연결할 수 있습니다. 그리고 RxJava의 기능 중 절반은 버려도 됩니다. 왜냐하면 트랜스듀서를 빌드하고 관찰 가능 항목과 트랜스듀서를 받아 관찰 가능 항목을 반환하는 하나의 관찰 가능 함수에 연결하기만 하면 되기 때문입니다. 이것이 바로 아이디어입니다.
So that's transduce. The other thing we can do is go to a completely different context now. So we have some channels. We are going to be sending pallets of luggage across channels. They don't really fit but the idea's there. This is a very different context. Channels run indefinitely. You can feed them stuff all the time and get stuff out of the other end on a continuous basis. But the critical thing here is that these things are not parameterized. They are not 'I'm a thing that you can tell me later.. you're going to tell me if it's trolleys or conveyor belts'. This is the exact same process bags I defined here, this concrete thing being reused in a completely different context. So this is concrete reuse, not parametrization. So we can use transducers on channels. The channel constructor now optionally takes a transducer and it will transduce everything that flows through. It has its own internal processing step, and it's going to modify its inputs accordingly with the transducer it's given. And it's an open system, I can imagine, but I did not get time to implement, that you could plug this into RxJava trivially. And take half of the RxJava's functions and throw them away. Because you can just a build a transducer and plug it into 1 observable function that takes an observable and a transducer and returns an observable. And that's the idea.
# Transducible Processes

그래서 우리는 이 모든 것, 즉 인, 시퀀스, 트랜스듀스, 찬을 트랜스듀서블 프로세스라고 부릅니다. 앞서 설명한 프로세스의 정의를 충족하고 트랜스듀서를 수용합니다. 트랜스듀서는 크게 두 부분으로 나뉘는데, 트랜스듀서를 생성하는 함수를 만들고, 이 함수가 적합한 상황에서 트랜스듀서를 받아들이기 시작합니다. 그런 다음 직교하는 두 개의 레고를 조립할 수 있습니다. 각 프로세스 내부에는 해당 트랜스듀서와 내부 처리 기능이 사용됩니다. 그렇다면 내부 처리 기능은 무엇일까요? 컬렉션에 한 가지를 추가하는 것입니다. 클로저에서는 이를 conj라고 합니다. 마찬가지로 지연 시퀀스 내부에는 필요에 따라 결과를 생성한 다음 다음 결과를 생성하기 위해 기다리는 함수 메커니즘이 있습니다. 따라서 내부에 이런 식으로 변환할 수 있는 단계가 있습니다.
So, we call all of these things - into, sequence, transduce and chan - transducible processes. They satisfy the definition of process we gave before, and they accept a transducer. So transducers sort of have two parts, you make functions that create transducers, and in contexts where they make sense, you start accepting transducers. Then you have these two orthogonal LEGOs you can put together. Inside each process, they are going to take that transducer and their internal processing function. So what's the internal processing function of into? The thing that adds one thing to a collection. In Clojure, it's called conj for conjoin. Similarly, inside lazy sequences, there's some func mechanism that produces a result on demand and then waits to produce the next thing. So that has a step inside of it that can be transformed this way.
채널도 입력을 받습니다. 채널 내부 어딘가에는 버퍼에 입력을 추가하는 작은 단계 함수가 있습니다. 이 단계 함수의 모양은 conj 및 laziness와 정확히 동일합니다. 따라서 기본적인 내부 연산을 변환할 수 있지만 연산은 완전히 캡슐화된 상태로 유지됩니다. 트랜스듀서블 컨텍스트는 트랜스듀서를 가져와서 자체 스텝 함수를 수정하고 이를 진행합니다.
Channels also take inputs. Somewhere inside channels is a little step function that adds an input to a buffer. That step function has exactly the same shape as conj and as laziness. So it can transform its fundamental internal operation but the operation remains completely encapsulated. The transducible context takes the transducer, modifies its own step function, and proceeds with that.
# Deriving Transducers

앞서 말했듯이 새로운 것은 없습니다. 이러한 것들을 생각하는 데 도움이 되는 두 가지 논문은 건설적 함수형 프로그래밍 강의 (opens new window)로, 사람들이 폴드와 리스트와의 관계에 대해 생각하기 시작한 시점에 훨씬 더 가깝습니다. 그리고 두 번째 그레이엄 허튼 논문 (opens new window)은 이 논문이 작성될 당시의 현재 생각을 요약한 요약 논문입니다. 그래서 둘 다 정말 훌륭합니다. 이제 '어떻게 이 지점에 도달할 수 있었을까'에 대해 설명해드리겠습니다.
So, as I said before, there's nothing new. Two papers I find useful to think about these things are these Lectures on Constructive Functional Programming (opens new window) which is a lot closer to the source of when people started thinking about folds and their relationships to lists. And the 2nd Graham Hutton paper (opens new window) served as a summary paper that sort of summarizes the current thinking at the time it was written. So they're both really good. But now I take you through 'how do we get to this point?'.
- Lectures on constructive functional programming (opens new window) by R. S. Bird
- A tutorial on the universality of fold (opens new window) by Graham Hutton
# Many list fns can be defined in terms of foldr

이런 것들에 대해 어떻게 생각할까요? Bird 논문과 그 이전의 연구들이 이야기하는 근본적인 것은 이러한 리스트 처리 연산과 접기 사이의 관계입니다. 사실 이 두 가지가 같은 것임을 보여주는 흥미로운 수학이 많이 있습니다. 구체적인 목록과 목록을 구성한 연산 사이를 앞뒤로 이동할 수 있다는 것입니다. 이 둘은 일종의 동형입니다. 따라서 우리가 가지고 있는 많은 목록 함수를 폴드 측면에서 재정의할 수 있습니다. 이미 여러 강연에서 맵에 대한 정의가 나온 적이 있지만, 전통적인 맵의 정의는 비어 있으면 빈 시퀀스를 반환한다고 말합니다. 새로운 입력을 받으면 그 입력을 나머지 입력에 매핑한 결과에 대입합니다. 재귀적이고 스스로 호출합니다. 하지만 맵은 그렇게 하고, 필터는 그렇게 하고, 맵캣은 그렇게 합니다. 모두 이러한 구조를 가지고 있습니다. 하지만 필터는 조금 다릅니다. 내부에 술어가 있고 조건 분기가 있으며 다른 인수를 사용하여 분기의 두 부분에서 재귀를 수행합니다. 따라서 이 이전 작업은 이 모든 것을 폴드라고 생각할 수 있습니다. 그렇게 하면 폴드에 대해 증명할 수 있는 많은 규칙성을 얻을 수 있는데, 이제 이 규칙성은 모든 함수에 동일하게 적용되지만 그렇지 않으면 서로 조금씩 다르게 보입니다. 따라서 여기에는 많은 가치가 있습니다.
How do we think about these things? So we're in the fundamental things that the Bird paper and the work that preceded it talk about is the relationship between these lists processing operations and fold. In fact, there's a lot of interesting mathematics that shows that they're the same thing. That you can go backwards and forwards between the concrete list and the operations that constructed it. They are sort of isomorphic to each other. So many of the list functions that we have can be redefined in terms of fold. There's already been a definition of map in several talks here, I think, but the traditional definition of maps says if it's empty, return empty sequence. If you're getting a new input, cons that input onto the result of mapping to the rest of the input. It's recursive and calls itself. But map does that, filter does that, mapcat does that. They all sort of have these structures. But filter is a little bit different. It has a predicate inside, it has a conditional branch and then it recurses in two parts of the branch with different arguments. So what this earlier work did was say, you can think of all of these things as folds. If you do, you get a lot of regularity in things that you can prove about folds, which are now all uniform will apply to all these functions but otherwise look a little bit different from each other. So there's a lot of value to this.
폴드는 재귀를 캡슐화하여 추론하기가 더 쉽습니다. 따라서 맵을 재정의할 때 이런 식으로 정의하는 경우는 많지 않지만, 폴드의 관점에서 맵을 재정의할 때 첫 번째 함수를 나머지 함수로 접는다고 가정해 보겠습니다. 그리고 빈 목록으로 시작합니다. 이것이 바로 폴드 방식입니다. 컬렉션을 통해 수행합니다. 필터도 이와 비슷하게 정의할 수 있는데, 정말 흥미로운 점은 폴더, 빈 목록, 콜이 모두 상용구라는 점입니다. 맵과 필터는 정확히 같은 개념입니다. 다른 점은 내부 함수 정의 안에 무엇이 들어 있느냐는 것입니다. 그리고 거기에도 똑같은 것이 있습니다.
fold encapsulates the recursion and it's easier to reason about. So if we look at a redefinition of map, it's not often defined this way, but if we look at a redefinition of map in terms of fold, then we say we're going to fold this function that cons the first thing onto the rest. And we start with an empty list. So this is fold way. We do it over a collection. We can similarly define filter this way, and what's really interesting about these things is that the foldr, the empty list and the coll, that's all boilerplate. It's exactly the same. map and filter are precisely the same in those things. All that's different is what's inside the inner function definition. And even there, there's something the same.
# Similarly, via reduce (foldl)
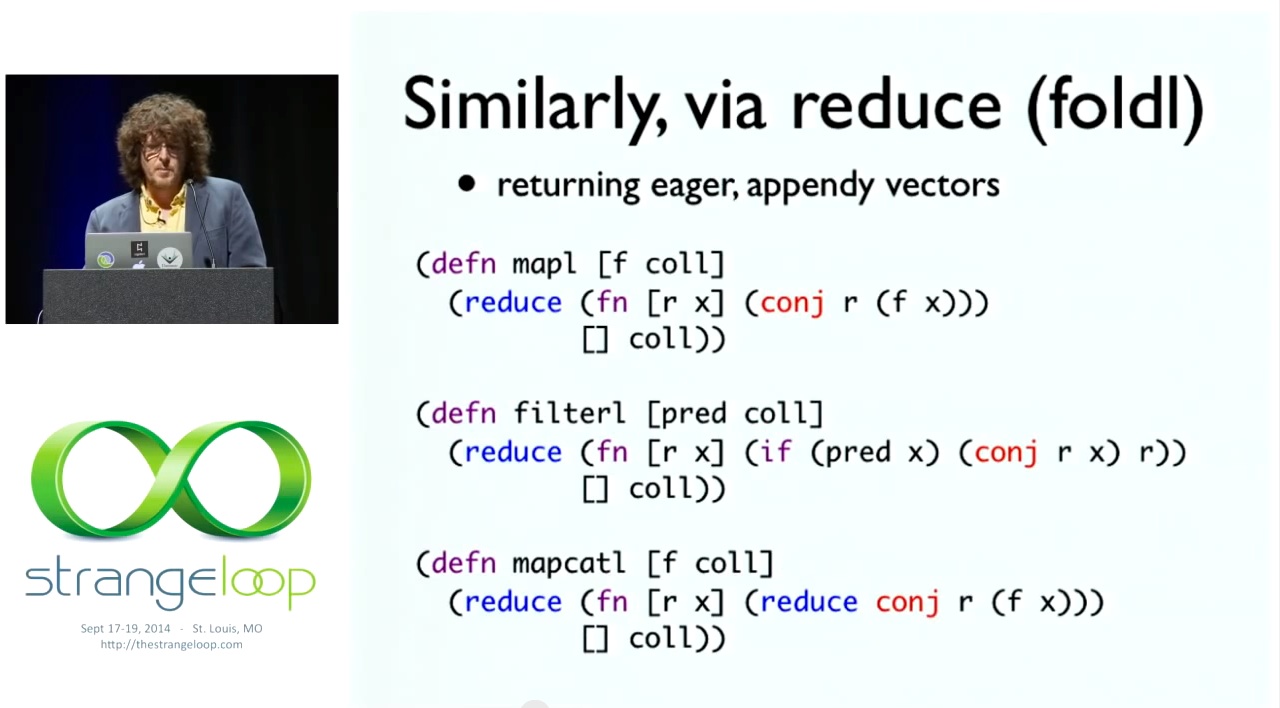
따라서 이러한 함수를 foldl로 유사하게 정의할 수 있습니다. foldl은 왼쪽 줄이기에 불과합니다. 다음은 맵과 필터에 대한 몇 가지 가정적 정의이며, 왼쪽 줄이기를 사용하는 왼쪽 접기인 맵캣을 추가했습니다. 왼쪽 줄이기와 오른쪽 줄이기의 장단점은 오른쪽 줄이기를 사용하면 게으름 경로로 이동하고 왼쪽 줄이기를 사용하면 루프 경로로 이동한다는 것입니다. 결국 루프 경로가 나중에 게으름을 얻을 수 있는 경우, 특히 방금 말씀드린 것처럼 우리가 적용하려는 종류의 작업에 더 빠르고 더 일반적이며 더 나은 결과를 가져옵니다. 그래서 마음에 듭니다.
So it ends up that you can similarly define these functions in terms of foldl. foldl is just left reduce. And here's some what-if definitions of map and filter, and we added mapcat, that are left folds that use left reduce. So, the trade-off between left reduce and right reduce is that right reduce sort of puts you on the laziness path and left reduce puts you on the loop path. It ends up that the loop path is better and faster and more general for the kinds of things we want to apply this to, especially if we can get laziness later, which I just said we kind of could. So we like that.
이런 것들을 루프로 바꿀 수 있다는 뜻입니다. 예를 들어 줄이면 루프가 되죠. 하지만 이와 마찬가지로 상용구도 있고, 이러한 정의에 따라 벡터를 사용하는 축소도 있는데, 클로저에서는 배열과 비슷하지만 기본적인 결합 연산이 마지막에 추가됩니다. 이것은 제가 강연의 나머지 부분에서 이야기하고자 하는 것과 같은 형태입니다. 우리가 구축 중인 무언가가 있습니다. 새로운 입력이 들어오고, 새로운 것을 생성하고, 오른쪽에서 무언가가 오른쪽에 추가되고 있습니다. 그래서 여기가 더 말이 되죠. 그래서 이것들은 열심이고 벡터를 반환합니다. 하지만 같은 아이디어입니다. 우리는 줄이고 있습니다. 지금까지의 벡터와 새로운 값을 취하는 함수가 있습니다. 새로운 값에 f를 적용하여 결합하고 있습니다. 이것이 매핑의 개념입니다. 매핑에는 수하물 처리 담당자가 이해할 수 있는 아이디어가 있습니다. 들어오는 모든 것에 라벨을 붙이는 것입니다. 매핑은 매우 일반적인 개념입니다. 그들도 이해하고 우리도 이해합니다. 우리는 모두 인간입니다. 우리도 똑같은 것을 이해합니다. 프로그래머로서 우리는 여기서 무슨 일이 일어나고 있는지 보세요. 맵은 모든 것이 들어올 때 기본적으로 하는 일이 있다고 말하고, 필터는 모든 것이 들어올 때 기본적으로 하는 작은 일이 있다고 말합니다. 그리고 mapcat은 모든 것이 들어올 때 모든 것에 대해 근본적인 작은 작업이 있다고 말합니다. 무엇이 문제일까요? conj! conj는 기본적으로 "트롤리 또는 컨베이어 벨트로"라고 말하는 것과 같습니다. 외부 작업에서 유출된 것이 아니라 아이디어의 한가운데에 있는 것입니다. 매핑이라는 아이디어의 중간에는 이 접속사가 있는데, 이것은 속하지 않습니다. 필터라는 아이디어의 한가운데에 이 접속사가 있는데 있어서는 안 되는 접속사입니다. 맵캣도 마찬가지입니다. 이것은 일반적인 아이디어 중간에 있는 구체적인 내용입니다. 일반적인 아이디어는 그냥 물건을 제거하는 것입니다. 우리는 conj에 대해 알고 싶지 않고 다른 것을 하고 싶을 수도 있습니다.
This means we can turn these things into loops. Like, reduce becomes a loop. But the same thing, we have a boilerplate, we have reduce, by these definitions, use vectors, which in Clojure are like arrays but their fundamental conjing operation adds at the end. This has the same shape I want to talk about for the rest of the talk. We have something that we are building up. A new input, we produce a new thing, and sort of the stuff is coming from the right and getting added to the right hand side. So it just makes more sense here. So these are eager and they return vectors. But it's the same idea. We are reducing. We have a function that takes the vector so far and a new value. We're conjoining the new value, having applied f to it. That's the idea of mapping. There's an idea behind mapping that luggage handlers understand. Put the label on everything that comes through. It's very general, that's mapping. They get that, we get that. We're all human beings. We understand the same thing. As programmers, we muck this up because look at what's happening here. map says there's this fundamental thing you do to everything as it comes through. filter says there's this fundamental tiny thing you do to everything as it comes through. And mapcat says there's this fundamental tiny thing you do to everything as it comes through. What's the problem? conj! conj is basically like saying, "To the trolley or to the conveyor belt". It's something about the outer job that's leaked, it's inside the middle of the idea. Inside the middle of the idea of mapping is this conj. It does not belong. Inside the middle of the idea of filter is this conj. It shouldn't be there. Same thing with mapcat. This is specific stuff in the middle of a general idea. The general idea is just take stuff out. We don't want to know about conj. Maybe we want to do something different.
그래서 우리는 많은 상용구를 사용합니다. 우리는 이러한 본질을 가지고 있으며 또 다른 중요한 것은 본질을 축소 기능으로 표현할 수 있다는 것입니다. 이 작은 내부 함수는 각각 conj와 정확히 같은 모양으로, r의 결과와 새로운 입력을 받아 다음 결과를 반환합니다.
So we have a lot of boilerplate. We have these essences and the other critical thing is the essences can be expressed as reducing functions. Each of these little inner functions is exactly the same shape as conj. It takes the results of r and new input; returns the next result.
# Transducers
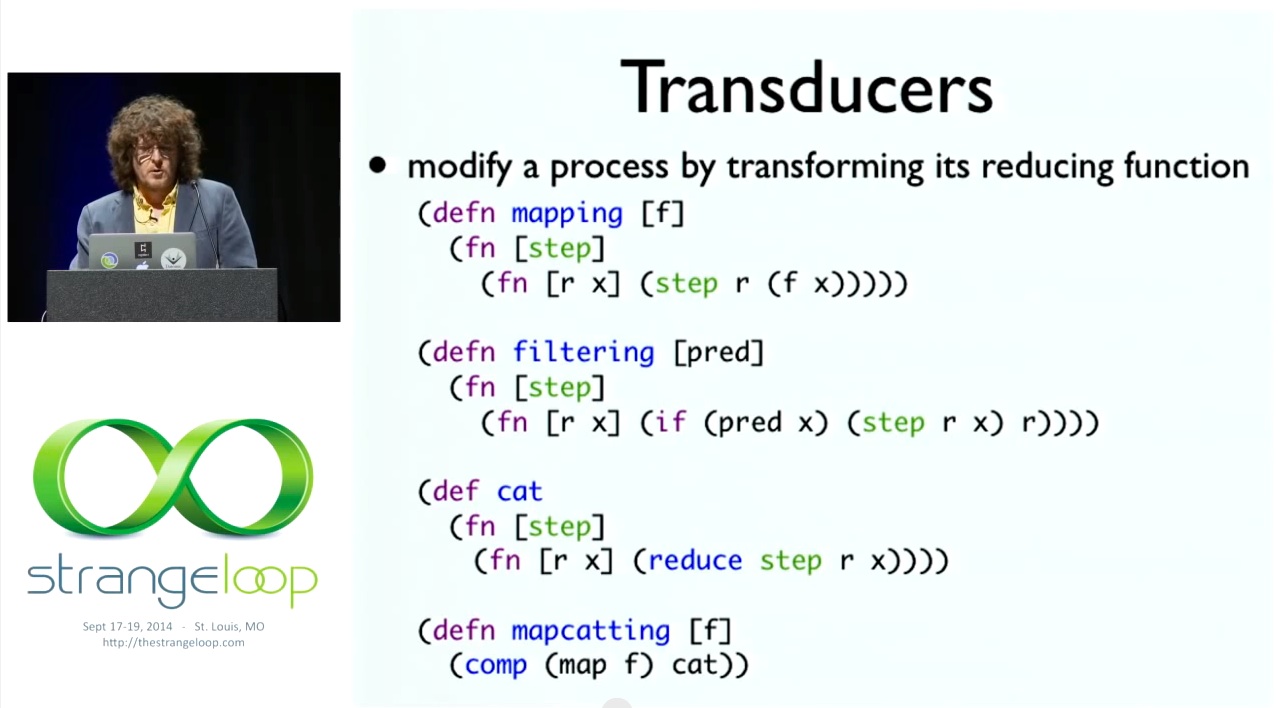
따라서 이러한 내부 함수를 트랜스듀서로 전환하기 위해 conj를 매개변수화하겠습니다. 구식 방식으로 매개변수화하겠습니다. 함수 인수를 사용해서요. 더 고차원적인 어쩌구 저쩌구 어쩌구 하는 것은 모두 단계인 인수를 사용할 것입니다. 이 매핑의 중간 본문은 지난 슬라이드와 동일합니다. 여기에는 conj라고 표시되어 있지만 이제는 step이라고 합니다. 단계를 취하는 함수 안에 넣었습니다. 매핑은 매핑할 대상을 가져와 수하물에 레이블을 지정하고 단계를 예상하는 함수인 무언가를 반환하는 함수입니다. 지금 무엇을 하고 있을까요? 컨베이어 벨트에 물건을 올려놓는 거죠. 지금 뭐 하는 거죠? 카트에 물건을 싣고 있습니다. 그리고 그 전에 짐에 F를 호출할 거예요. 짐에 라벨을 붙이려고요. 더 이상 짐에 대해 잘 모르겠어요. 그 다음 단계는 나중에 알려줄 거야 오늘은 뭘 하죠? 컨베이어 벨트, 트롤리? 컨베이어 벨트, 좋아요. 규칙도 알고 매핑과 필터링, 맵카팅을 하는 방법도 알아요. 필터링도 마찬가지입니다. 필터링의 핵심은 바로 이 점입니다. 술어를 적용한 다음 단계를 수행하거나 수행하지 않을 수도 있습니다. 여기에는 아무것도 없습니다. 활동에 대한 선택입니다. 행동에 대한 선택입니다. 연결도 마찬가지입니다. 무엇을 하나요? 기본적으로 이 단계를 두 번 이상 수행하라고 말합니다. 저는 여러분에게 일련의 입력을 제공하고 있습니다. 각각의 항목에 이 작업을 수행하세요. 그리고 맵카팅은 지도와 고양이를 합성하는 것입니다. 그렇게 해야 합니다. 좋아요.
So, to turn those inner functions into transducers, we are just going to parametrize that conj. We are going to parametrize the old fashioned way. With the function argument. That anything higher-order blah blah blah, you know, we are going to take an argument which is the step. So right in the middle body of this mapping - this is the same as it was in the last slide, this is where it said conj, now we say step. We put that inside a function that takes the step. So this is a function, mapping takes the thing that you're going to map, label the baggage, and it returns something that is a function that expects a step. What are we doing? Putting stuff on conveyor belts. What are we doing? We're putting stuff on trolleys. And it says, before I do that, I'm going to call f on the luggage. I'm going to put a label on the luggage. I don't know about luggage anymore. The step, you're going to tell me later. What are we doing today? Conveyor belts or trolleys? Conveyor belts, cool. I got the rules, I understand how to do mapping and filtering and mapcatting. So same thing, filter, and what's beautiful about this is what's the essence of filtering. Apply a predicate and then maybe you do the step or maybe you don't. There's no stuff here. It's a choice about activity. It's a choice about action. Same thing with concatenating, cat. What does it do? Basically says, do this step more than once. I'm giving you an input that's really a set of things. Do it to each thing. And mapcatting is just composing map and cat. Which it should be. OK.
# reduce-based map et al redux
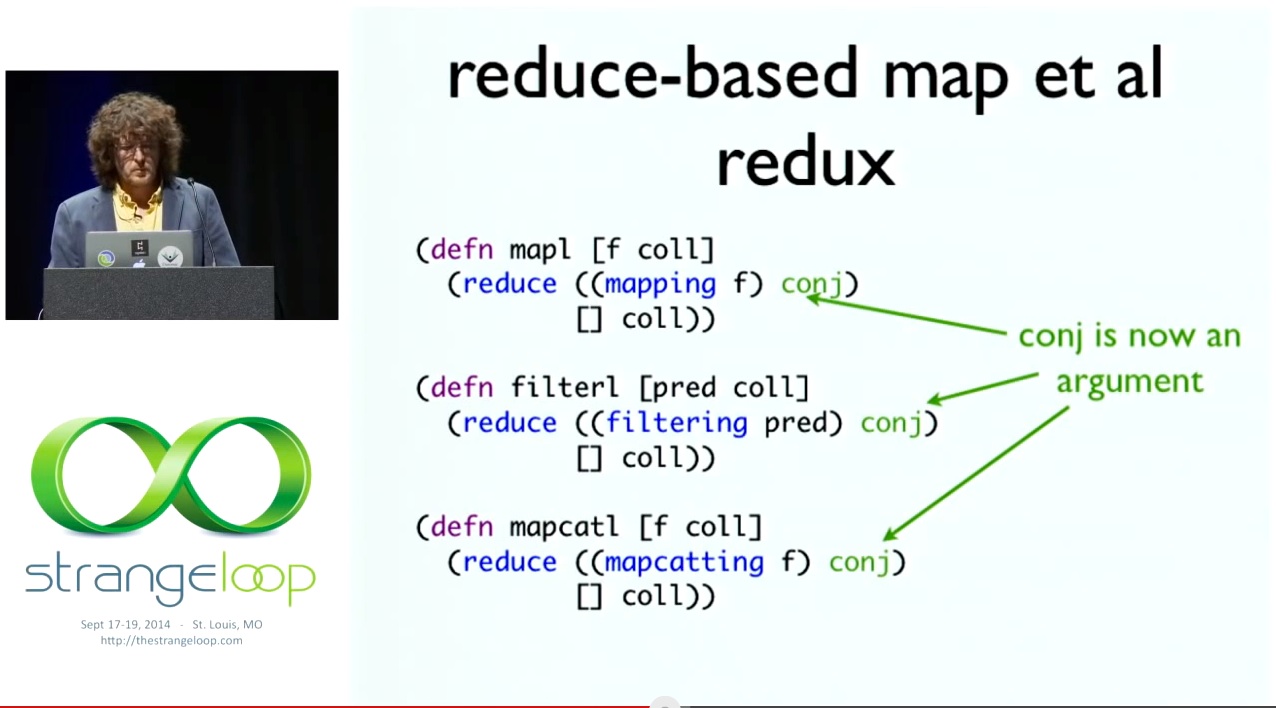
따라서 매핑은 트랜스듀서를 반환하고, 필터링은 트랜스듀서를 반환하고, 고양이는 트랜스듀서를 반환하고, 맵캣팅은 트랜스듀서를 반환하는 함수를 사용할 수 있습니다. 이제 매핑을 목록이나 벡터에 대해 더 이상 알지 못하는 추상적인 것으로 만들었으니 맵을 어떻게 정의할 수 있는지와 같이 이전에 본 코드에 연결할 수 있습니다. 그리고 우리가 하는 일은 매핑을 호출하여 "단계 함수를 주면 입력에 대해 먼저 f를 수행하도록 수정하겠습니다."라고 말하는 트랜스듀서를 제공하는 것입니다. "좋아요, 여기 단계 함수가 있습니다: conj"라고 말합니다. 이제 conj가 더 이상 매핑이나 필터링 또는 맵카팅 내부에 있지 않다는 점을 제외하고는 이전에 사용했던 함수를 다시 빌드합니다. 인자입니다. 우후!! 이제 우리는 이러한 것들의 본질을 단품으로 갖게 되었습니다. 그게 바로 요점입니다.
So we can take these transducer returning functions, so mapping returns a transducer, filtering returns a transducer, cat is a transducer, and mapcatting returns a transducer. And we can then plug them into the code we saw before, like how could we define map, now that we have made mapping into this abstract thing which doesn't really know about lists or vectors anymore. And what we do is we just call mapping, that gives us a transducer that says, "If you give me a step function, I'll modify it to do f first on the input". We say, "OK, here's the step function: conj". Now I rebuild the functions I had before, except conj is not inside mapping or filtering or mapcatting anymore. It's an argument. Woohoo!! We now have the essence of these things, a la carte. And that's the point.
# Transducers are Fully Decoupled

트랜스듀서가 완전히 분리되어 있습니다. 자신이 무엇을 하고 있는지 모릅니다. 어떤 프로세스를 수정하고 있는지 알 수 없습니다. 스텝 함수는 완전히 캡슐화되어 있습니다. 스텝 함수를 전혀 호출하지 않을 수 있는 자유가 있습니다. 입력당 정확히 한 번 또는 입력당 두 번 이상 호출할 수도 있습니다. 하지만 스텝 함수가 어떤 기능을 하는지 모르기 때문에 스텝 함수를 사용하거나 사용하지 않는 것으로 제한됩니다. 입력에 액세스할 수 있다는 점을 제외하면 그게 거의 전부입니다. 그래서 우리가 '맵캣 언번들 팔레트'라고 했을 때, 우리가 제공하는 기능은 팔레트에 대해 알고 있는 기능입니다. 컨베이어 벨트에 대해서는 알지 못합니다. 전체 작업은 모르지만 팔레트에 대해서는 알고 있습니다. 팔레트를 수하물 세트로 전환하는 방법을 알고 있습니다. 전달한 물건 함수를 어떻게 사용하는지에 대한 중요한 점이 있는데, 앞서 언급한 후계자 개념으로 돌아갑니다. 스텝 함수를 호출할 때 이전 결과를 다음 스텝 함수를 호출할 때 다음 첫 번째 인수로 전달해야 합니다. 이것이 단계 함수와 그 사용에 대한 규칙입니다. 그리고 다른 것은 없습니다. 입력 인자인 두 번째 인자를 변환할 수 있습니다.
Transducers are fully decoupled. They don't know what they're doing. They don't know what process they're modifying. The step function is completely encapsulated. They have some freedom; they can call the step function not at all. Once exactly per input or more than once per input. But they don't really know what it does so that's what they are limited to doing: using it or not using it. That's pretty much it, except they do have access to the input. So when we said mapcat unbundle-pallet, the function we're supplying there is something that knows about pallets. It doesn't know about conveyor belts. It doesn't know what the overall job is but it knows about pallets. It's going to know how to turn a pallet into a set of pieces of luggage. There's a critical thing about how they use that stuff function that they have been passing, it goes back to the successor notion I mentioned before. They must pass the previous result from calling the step function, as the next first argument to the next call to the step function. That is the rule for step functions and their use. And no others. They can transform the input argument, the second argument.
# Backwards comp?
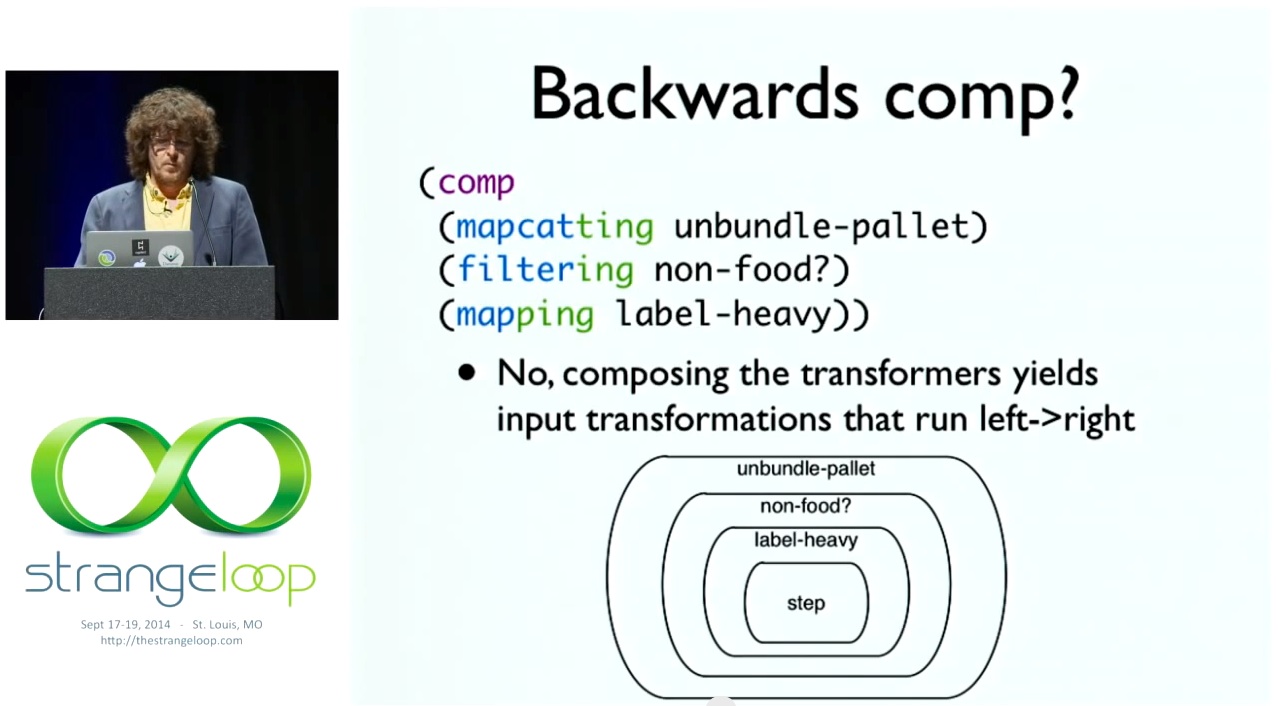
이제 거꾸로 된 부분에 대해 조금 이야기해 보겠습니다. 제가 자주 받는 질문입니다. 무엇을 하셨나요? 트랜스듀서가 컴포넌트를 바꾸나요? 그게 첫 번째입니다. 컴포넌트나 그런 것을 망칩니다. 그래서 우리가 해야 할 일은 트랜스듀서의 기능을 살펴보는 것입니다. 트랜스듀서 함수는 함수를 가져와서 래핑하고 새로운 단계 함수를 반환합니다. 이것은 여전히 오른쪽에서 왼쪽으로 일어나고 있습니다. 이것은 일반 컴포넌트이며 오른쪽에서 왼쪽으로 작동합니다. 따라서 매핑이 먼저 실행됩니다. '트롤리에 물건 올려놓기'나 '컨제이' 같은 연산이 있을 텐데, 매핑이 가장 먼저 실행됩니다. '비행기에 실어'라고 호출하기 전에 무거운 가방에 라벨을 붙이는 약간의 수정된 단계를 수행합니다. 그런 다음 필터링이 호출되면 오른쪽에서 왼쪽으로 이동합니다. "그 단계를 알려주면 음식인지 먼저 확인하는 새 단계를 만들겠습니다. 음식이면 버릴 것이고, 음식이 아니라면 사용할 것입니다."라고 말합니다. 그런 다음 맵카팅이 실행되거나 맵카팅의 결과가 실행됩니다. 즉, "단계를 주면 그 입력을 받아 팔레트라고 가정하고 번들을 풀고 중첩된 항목에 각 인수를 제공하겠습니다."라고 말합니다. 따라서 트랜스포머의 구성은 오른쪽에서 왼쪽으로 이어집니다. 하지만 컴포넌트에서 왼쪽에서 오른쪽으로 나타나는 순서대로 실행되는 변환 단계를 구축합니다. 즉, 컴포넌트는 정상적으로 작동합니다. 오른쪽에서 왼쪽으로 단계를 빌드하고 있습니다. 결과 단계는 왼쪽에서 오른쪽으로 변환을 실행합니다. 따라서 실제로 이 작업을 실행할 때는 먼저 팔레트를 풀고 다음 단계를 호출하여 식품을 제거합니다. 다음 단계는 무거운 가방에 라벨을 붙이는 것입니다. 그래서 거꾸로 보이는 것입니다.
So let's talk a little bit about the backwards part. This is a frequent question I get. What did you do? Does transducers change comp? That is the first thing, they ruin comp or something like that. So what we've to do is look at what transducers do. A transducer function takes a function, wraps it and returns a new step function. That is still happening right to left. This is ordinary comp and it works right to left. So mapping gets run first. We are going to have some operation, you know, 'put stuff on trolley' or conj. Mapping will be the first thing that happens. It's going to make a little modified step that labels the heavy bags before it calls 'put it on the airplane'. Then filtering gets called, it does go right to left. It says, "Give me that step, I'll make you a new step that first sees if it's food. If it's food, I'm going to throw it away, if it's not food, I'm going to use it". Then mapcatting runs, or the result of mapcatting runs. And that says, "Give me a step and I'll take its input, presume it's a pallet, unbundle it, and supply each of those arguments to the nested thing". So the composition of the transformers runs right to left. But it builds a transformation step that runs in the order that they appear: left to right in the comp. In other words, comp is working ordinarily. It's building steps right to left. The resulting step runs the transformations left to right. So when we actually run this, we'll unbundle the pallets first, call the next step, which is to get rid of the food. Call the next step, which is to label the heavy bags. So that's why it looks backwards.
# Transducers are Fast

트랜스듀서의 또 다른 장점은 중간 단계가 없다는 점입니다. 함수 호출의 스택일 뿐입니다. 짧습니다. 잠재적으로 인라인이 될 수 있습니다. 게으름으로 인한 오버헤드가 없습니다. 게으름이 필요하지 않습니다. 게으름이 활용되지 않습니다. 예를 들어, 중간 수집이 없습니다. "어떻게 모든 것을 목록으로 만들 수 있죠?"라고 말하지 않습니다. 따라서 "빈 목록은 아무것도 아니다"라고 말할 수 있습니다. 아니요, 빈 목록은 아무것도 아닙니다. 빈 목록은 빈 목록일 뿐입니다. 그리고 한 가지는 한 가지입니다. 한 가지의 목록은 한 가지의 목록입니다. 이것들은 동일하지 않습니다. 따라서 단계 기능을 사용하든 사용하지 않든 상관없습니다. 그리고 메커니즘에 대한 의사 소통을 위해 추가 상자나 박싱이 필요하지 않습니다.
Ok, so, the other nice thing about transducers is that there's no intermediate stuff. They're just a stack of function calls. They are short. Potentially they could be inlined. There's no laziness overhead. There's no laziness required. There's no laziness utilized. Like, there's no interim collections. We're not going to tell, "How do you make everything into a list?". So, you can say, "An empty list is nothing". No, nothing is nothing. Empty list is an empty list. And one thing is one thing. A list of one thing is a list of one thing. These are not the same. So you use the step function or you don't. And there's no extra boxes required, or boxing for communicating about the mechanism.
# Transducer Types, Thus Far
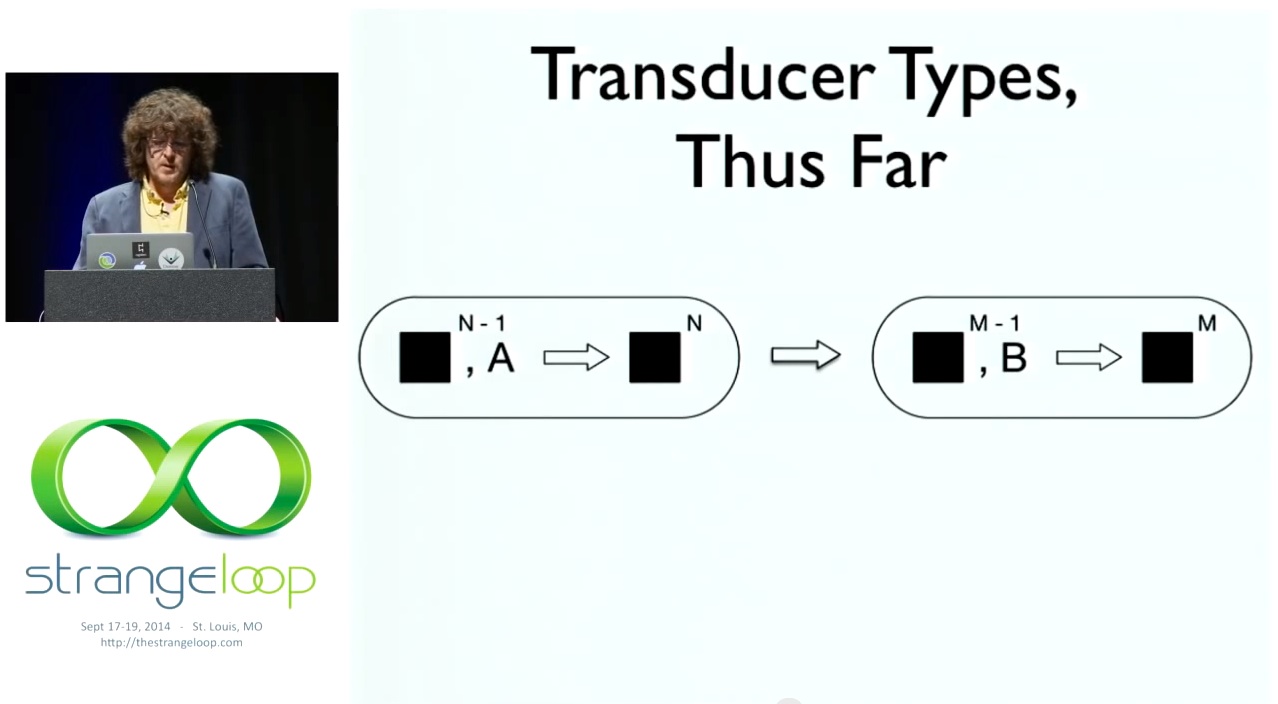
제가 트랜스듀서에 대해 이야기하기 시작했을 때 하스켈의 많은 사람들이 제가 블로그 게시물에 속기를 사용했기 때문에 실제 유형이 무엇인지 알아내려고 애썼습니다. 지금은 그 문제에 대해서는 언급하지 않겠지만, 매우 흥미로운 유형 문제라고 생각하며 사람들이 다양한 언어로 이 문제를 어떻게 처리하는지 보는 것이 매우 흥미롭다는 것 외에는 말하지 않겠습니다. 사용자의 유형 시스템이 이를 처리할 수 있는지 여부에 따라 "꽤 잘 작동한다"에서 "이런 유형은 나를 죽인다"에 이르는 결과를 보았습니다. 하지만 지금까지 우리가 알고 있는 것을 그래픽으로 캡처해 봅시다. 이 슬라이드를 검토해 준 누군가가 말하길, 이 슬라이드는 구독 기능이 있어야 한다고 했습니다. 컴퓨터를 사용하기가 너무 어려워서 제때에 전환할 수 없다는 것이죠. 그래서 위 첨자로 되어 있지만, 다음 프로세스 N을 생성하려면 N-1 단계의 결과를 입력으로 제공해야 한다는 아이디어입니다. 유형 시스템에서 이것을 R에서 R로 모델링하려고 하면 잘못된 것입니다. 단계 함수를 5번 호출한 다음 6번째에 1번의 반환값을 가져와서 첫 번째로 전달할 수 있기 때문입니다. 그건 잘못된 것입니다. 그래서 타입 시스템을 잘못 만들도록 만들어야 합니다. 그래서 그것을 알아 내십시오. 또한 블랙박스와 블랙박스를 동일하게 만들면 그것도 임의로 제한됩니다. X가 주어질 때마다 Y를 반환하고, Y가 주어질 때마다 Z를 반환하고, Z가 주어질 때마다 X를 반환하는 스테이트 머신을 만들 수 있습니다. 3개의 개별 입력 유형과 3개의 개별 출력 유형이 있습니다. 특정 시간에만 발생합니다. 이 상태 머신에는 아무런 문제가 없습니다. 완벽하게 괜찮은 환원 함수입니다. 유형 시스템에서 모델링하기는 어려울 수 있습니다. X, Y, Z라고 하지 마세요. X, Y, Z를 받아 X, Y, Z를 반환하지 않으니까요. X가 주어지면 Y만 반환하고 Z는 반환하지 않으니 나중에 술집에 좋은 프로젝트가 될 것 같습니다. 웃음] 하지만 여기서 우리가 포착하고 있는 것은 새로운 단계 함수가 다른 종류의 입력을 받을 수 있다는 점입니다. 첫 번째 단계에서는 A 대신 B를 받을 수 있습니다. 팔레트를 가져와서 수하물 세트를 반환하지만 각 단계마다 수하물 한 개를 반환합니다.
So the other thing, that was sort of interesting was.. I started talking about transducers and a lot of people in Haskell were trying to figure out what the actual types were because I had shorthand in my blogpost and I'm not going to get into that right now, except to say that I think it's a very interesting type problem and am very excited to see how people do with it in their various languages. I've seen results that were sort of, "It works pretty well" to "Man, these types are killing me", depending on whether the user's type system could deal with it. But let's just try to capture what we know so far graphically, and somebody who reviewed these slides for me, said this should have been subscript stuff. Like, computers are so hard to use, I couldn't switch them in time. So they're superscripts but the idea is that if you're trying to produce the next process N, you must supply the result from step N-1 as the input. If you try to model this in your type system saying R to R. That's wrong. Because I can call the step function 5 times and then on the 6th time, take the return value from the 1st time and pass it as the first thing. That's wrong. So you have got to make the type system make that wrong. So figure that out. Also, if you make the black box and the black box the same thing, that's also arbitrarily restrictive. You can have a state machine that every time it was given X, returned Y. Every time it was given Y, returned Z. Every time it was given Z, returned X. That's a perfectly valid step function. It has 3 separate input types and 3 separate output types. It only happens at particular times. There's nothing wrong with that state machine. It is a perfectly fine reducing function. It may, you know, be tough to model in a type system. And don't say X or Y or Z. Because it doesn't take X or Y or Z and return X or Y or Z. When it's given X, it only returns Y. It never returns Z. So, seems like a good project for the bar, later on.[laughter] But the thing we're capturing here is that the new step function might take a different kind of input. It might take a B instead of an A. Now, our first step does that. It takes a pallet and returns a set of pieces of luggage but each step returns a piece of luggage.
# Early Termination

프로세스에서 일어나는 다른 흥미로운 일들이 있습니다. 일반 축소에서는 모든 것을 처리하지만, 우리는 이 기능이 임의로 길게 실행되는 경우에 사용할 수 있기를 원합니다. 단순히 한 종류의 컬렉션을 다른 종류의 컬렉션으로 바꾸는 것에 대해 이야기하는 것이 아닙니다. 채널에서 실행 중인 트랜스듀서에는 임의의 양의 데이터가 들어옵니다. 이벤트 스트림의 트랜스듀서에는 임의의 양의 데이터가 들어옵니다. 하지만 때때로 감소 프로세스를 원하거나 누군가가 "우와! 충분히 봤어. 더 이상 입력을 보고 싶지 않아요. 우린 끝났어요. 더 많은 의견이 있더라도 이제 끝났어요."라고 말하고 싶을 때가 있습니다. 그래서 우리는 이를 조기 종료라고 부릅니다. 그리고 하단에 있는 것과 같이 프로세스 자체에서 원할 수도 있습니다. 또는 단계 중 하나의 함수일 수도 있고, 단계 중 하나가 "저기요, 제가 해야 할 일은 이것뿐이에요. 이제 더 이상 보고 싶지 않아요."라고 말할 수도 있습니다. 여기서는 지침을 수정하여 "가방이 똑딱거린다면 완료된 것입니다. 집에 가세요. 비행기에 짐을 싣는 것은 끝났습니다."라고 말합니다. [웃음] 그래서 우리는 '틱하지 않는 동안 복용'을 추가할 것입니다. 틱을 하지 않는 동안 촬영하려면 중간에 전체 작업을 중단해야 합니다. 카트에 물건이 더 많이 실려 있어도 상관없습니다. 틱이 끝나면 끝입니다.
OK, so there are other interesting things that happen in processes. Ordinary reduction processes everything, but we want this to be usuable in cases that run arbitrarily long. We're not just talking about turning one kind of collection into another kind of collection. A transducer that's running on a channel has got an arbitrary amount of stuff coming through. A transducer on an event stream has an arbitrary amount of stuff coming through. But sometimes you want.. either the reducing process or somebody says "Whoa! I've had enough. I don't want to see anymore input. We're done. I want to say, we're done now even though you may have more input". So, we're going to call that early termination. And it may be desired by the process itself, like the thing at the bottom. Or it may be a function of one of the steps, one of the steps may say, "You know what, that's all I was supposed to do. So, I don't want to see any more of them". And the example here will be, we're going to modify our instructions and say, "If the bag is ticking, you're finished. Go home. We're done loading the plane". [laughter] So, we're going to add that - taking while non-ticking. Taking while non-ticking needs to stop the whole job in the middle. It doesn't matter if there's more stuff on the trolley. When it's ticking, we're finished.
# Reduced

그렇다면 어떻게 해야 할까요? 결국 클로저에는 이미 이 아이디어를 지원하는 reduce가 있습니다. "더 이상 입력을 보고 싶지 않습니다."라고 말하는 reduced라는 특수 래퍼 객체의 생성자가 있습니다. 여기까지 내가 생각해낸 것이 있으니 더 이상 입력하지 마세요."라고 말합니다. 그리고 이 래퍼에 무언가가 있는지 물어볼 수 있는 reduced? 라는 술어가 있습니다. 그리고 포장을 풀고 그 안에 무엇이 있는지 살펴볼 수 있는 방법이 있습니다. 따라서 "축소된 것이 축소되었나요?"라고 말할 수 있습니다. 이는 항상 참으로 반환됩니다. 그리고 축소된 것을 해제하고 그 안에 있는 것을 얻을 수 있습니다. 이것은 어쩌면과 같은 것이 아닙니다. 어쩌면은 축소되지 않은 다른 것들을 감싸기도 합니다. 또는 둘 중 하나, 또는 다른 상자 같은 것들. 그래서 우리는 그렇게 하지 않습니다. 우리는 이 특별한 종료를 할 때만 래핑을 합니다.
So how do we do that? It ends up, in Clojure, we already have support for this idea in reduce. There's a constructor of a special wrapper object called reduced which says, "I don't want to see any more input. Here's what I have come up with so far, and don't give me any more input". And there's a predicate called reduced? that allows you to ask if there's something in this wrapper. And there's a way to unwrap the thing and look at what's in it. So you can say, is the reduced thing reduced? That will always return true. And you can deref a reduced thing and get the thing that's inside it. This is not the same thing as maybe. maybe also wraps the other things that are not reduced. Or either, or those other boxy kind of things. So we don't do that. We only wrap when we're doing this special termination.
# Transducers Support reduced

따라서 감소와 마찬가지로 트랜스듀서는 감소도 지원해야 합니다. 즉, 스텝 함수는 감소된 값을 반환할 수 있습니다. 그리고 트랜스듀싱 프로세스나 트랜스듀서가 감소된 값을 얻으면 다시는 입력으로 스텝 함수를 호출해서는 안 됩니다. 이것이 규칙입니다. 다시 말하지만, 유형 시스템에 이 규칙을 구현해 보세요. 이제 동안의 내부를 살펴볼 수 있습니다. 이 함수에는 술어가 있고, 수정할 단계가 있습니다. 입력에 대해 술어를 실행합니다. 괜찮으면 스텝을 실행합니다. 정상적이지 않은 경우 지금까지 구축된 내용을 가지고 "완료되었습니다. 결과 감소"라고 말합니다. 이것이 우리가 탈출하는 방법입니다. 하지만 일반적인 결과는 포장지에 담겨 있지 않습니다.
So, like reduce, transducers must also support reduced. That means that the step functions are allowed to return a reduced value. And that if a transducing process or a transducer gets a reduced value, it must never call a step function with input again. That's the rule. Again, implement the rule in your type system, have at it but that's the rule. So now we can look at the insides of taking-while. It takes a predicate, it takes a step that it's going to modify. It runs the predicate on the input. If it's OK, it runs the step. If it's not OK, it takes what has been built up so far and says, "We're finished. Reduced result". That's how we bail out. But notice the ordinary result is not in a wrapper.
# Processes Must Support Reduced

따라서 환원 프로세스도 이 게임을 해야 합니다. 트랜스듀서는 이전의 규칙을 따라야 하고 환원 프로세서도 마찬가지로 환원을 지원해야 합니다. 만약 환원된 것을 발견하면 다시는 입력을 제공하지 않아야 합니다. 역참조된 값이 최종 누적 값입니다. 하지만 최종 누적 값은 여전히 완료될 수 있는데, 이 부분에 대해서는 잠시 후에 설명하겠습니다. 따라서 트랜스듀서에도 규칙이 있습니다. 트랜스듀서는 이 규칙을 따라야 합니다.
And so the reducing processes must also play this game. The transducer has to follow the rule from before, and the reducing processor has to similarly support reduced. If it ever sees a reduced thing, it must never supply input again. The dereferenced value is the final accumulated value. But the final accumulated value is still subject to completion which I'm going to talk about in a second. So there's a rule for the transducers as well. They have to follow this rule.
# Transducer Types, Thus Far
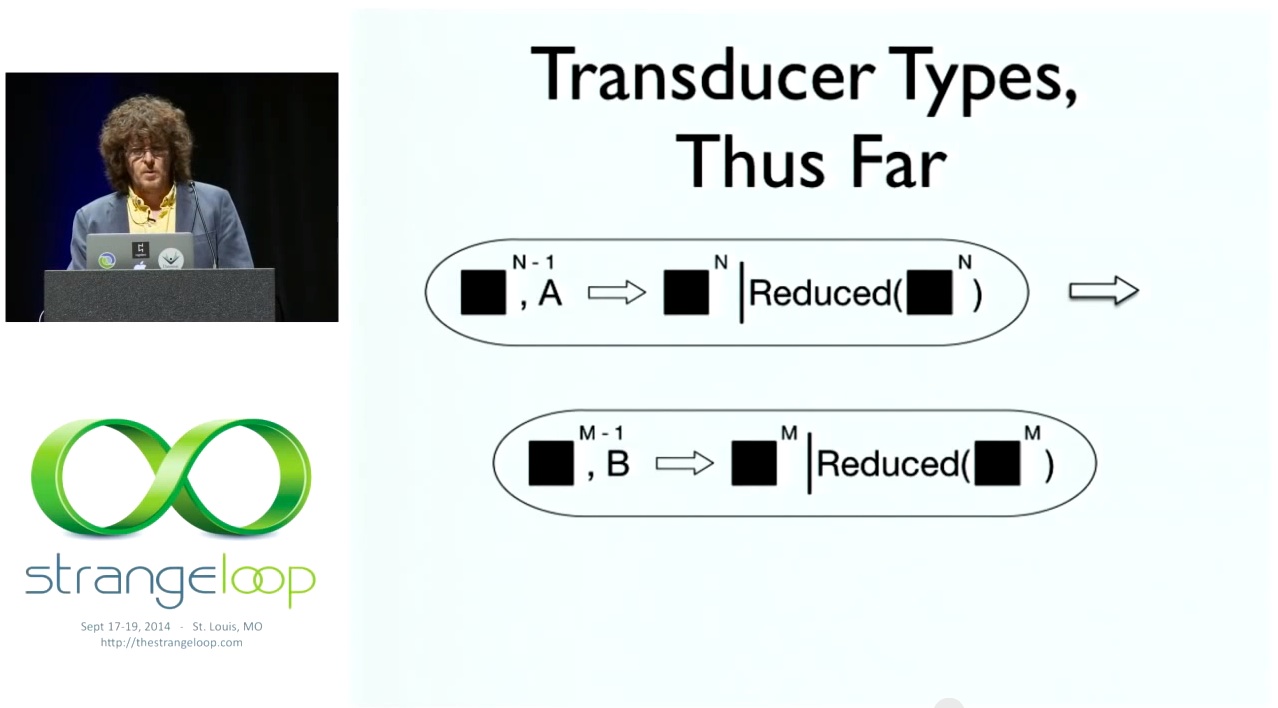
이제 그래픽 타입 언어인 Omnigraffle에서 새로운 그림 타입을 얻게 되었습니다. [이전 단계에서 블랙박스와 입력을 받아 다음 단계에서 블랙박스를 반환하는 프로세스를 만들 수도 있고, 축소된 버전을 반환하는 프로세스를 만들 수도 있습니다. 따라서 이 두 가지 중 하나가 발생할 수 있습니다. 세로 막대 '또는'(|). 그리고 마찬가지로 다른 종류의 입력, 즉 블랙박스를 받아 블랙박스 또는 축소된 블랙박스를 반환할 수 있는 다른 단계 함수를 반환합니다. 승계에 대한 동일한 규칙이 적용됩니다. 알겠습니다.
So now we get new pictorial types in the graphical type language that is Omnigraffle. [laughter] So we can have a process that takes some black box at the prior step and an input and returns a black box at the next step, or maybe it returns a reduced version of that. So one of those two things could happen. Vertical bars 'or' (|). And it returns another step function that's similarly can take a different kind of input, a black box, returns a black box or a reduced black box. Same rules about successorship apply. Alright.
# State

따라서 일부 흥미로운 시퀀스 함수에는 상태가 필요하며, 순전히 기능적인 구현에서는 스택이나 게으름을 사용하여 상태를 저장합니다. 실행 기계의 어딘가에 물건을 넣을 수 있는 공간이 생깁니다. 이제 우리는 "게으르다, 게으르지 않다, 재귀적이지 않다를 지정하는 일에 관여하고 싶지 않습니다. 실행 전략을 여러분으로부터 보호하려고 하기 때문에 실행 전략 내부에 공간을 주지 않겠습니다."라고 말합니다. 즉, 트랜스듀서가 있을 때 상태는 명시적이어야 합니다. 상태가 필요한 각 트랜스듀서는 상태를 생성해야 합니다. 따라서 상태가 필요한 시퀀스 함수의 예로는 take, partition-all, partition-by 등이 있습니다. 나중에 뱉어내기 위해 어떤 계정을 가지고 있거나 어떤 것을 축적하고 있습니다. 그게 어디로 갈까요? 그리고 그것은 트랜스듀서 객체 내부로 들어가야 합니다. 상태를 만들어야 합니다. 그리고 그것에 대한 몇 가지 규칙이 있습니다. 트랜스듀서 작성자로서 상태가 필요한 경우 매번 고유하게 생성해야 하며, 스텝 함수를 변환하라는 요청을 받을 때마다 다시 생성해야 합니다. 따라서 단계 함수를 변환할 때마다 상태를 새로 만들어야 합니다. 즉, 트랜스듀서 스택을 구성하고 그중 일부가 상태 저장 트랜스듀서인 경우 이를 빌드할 때가 아니라 적용하면 그때는 상태가 존재하지 않습니다. 이제 comp를 호출한 후에는 상태가 없습니다. 이를 적용하면 이제 새로운 프로세스 단계가 생깁니다. 하지만 맨 아래에 있는 단계를 포함한 모든 트랜스듀서 프로세스 단계에 대해 생각해야 하므로 상태가 있을 수 있습니다. 맨 아래 프로세스가 우주로 물건을 발사하지 않았는지 알 수 없습니다. 따라서 적용된 트랜스듀서 스택은 항상 상태 저장 프로세스를 반환하는 것처럼 취급해야 하며, 별칭을 지정해서는 안 됩니다. 실제로는 모든 트랜스듀서 프로세스가 적용을 수행합니다. 사용자가 할 수 있는 일이 아닙니다. 트랜스듀서와 입력을 작업에 전달하면 작업은 해당 프로세스에 트랜스듀서를 적용합니다. 그렇게 할 때 새로운 상태 세트를 가져오고 아무런 해가 없습니다. 하지만 이 작업은 관례에 따라 수행해야 합니다.
So, some interesting sequence functions require state, and in the purely functional implementations, they get to use the stack or laziness to put that state. You get somewhere in the execution machinery a place to put stuff. Now we're saying, "I don't want to be in the business of specifying we're lazy or not lazy or recursive. I'm not going to give you space inside the execution strategy because I'm trying to keep the execution strategy from you". And that means the state has to be explicit when you have transducers. Each transducer that needs state, must create it. So examples of sequence functions that need state are take, partition-all, partition-by and things like that. They have some accounting or they are accumulating some stuff to spit it out later. Where's that going to go? And it has to go inside the transducer object. They have to make state. And there's some rules about that. If you need state as a transducer author, you have to create it every time uniquely, and again, every time you are asked to transform a step function. So anew you're going to create state every time you transform a step function. That means that if you build up a transducer stack, some of which are stateful transducers, and you apply it, not when you build it, no state exists then. Now, after you have called comp, there's no state. When you've applied it, you now have a new process step. But as we should be thinking about all transducer process steps including the ones at the bottom, that may be stateful. We don't know the very bottom process hasn't launched stuff into space. So you should always treat an applied transducer stack as if it would return a stateful process, which means you shouldn't alias it. What ends up happening in practice is all of the transducible processes, they do the applying. It's not in the user's hands to do it. To pass around a transducer and input to the job, the job applies the transducer to its process. Gets a fresh set of state when it does that and there's no harm. But you do have to do this by convention.
# A Stateful Transducer

다음은 상태 저장 트랜스듀서의 예시입니다. 술어가 참일 때 삭제합니다. 참이라는 플래그부터 시작하겠습니다. 그것이 여전히 참인 한, 우리는 드롭할 것입니다. 참이 아닌 것으로 확인되면 플래그를 재설정하고 단계를 계속 적용합니다. 그리고 그 다음부터는 단계를 적용할 것입니다. 그래서 그것은 가장 예쁜 것이 아닙니다.
So, here's an example of a stateful transducer. Dropping while a predicate is true. So we start with our flag that says it's true. As long as it's still true, we're going to drop. When we see that it's not true, we're going to reset it and continue with applying the step. And from then on forward, we are going to apply the step. So that is not the prettiest thing.
# Completion

완료하기 전에 이야기했습니다. 그래서 우리는 조기 종료라는 아이디어를 가지고 있습니다. 트랜스듀서가 지원하는 또 다른 아이디어는 완료입니다. 즉, 입력이 끝날 때 완료되지 않을 수도 있다는 것입니다. 완료되지 않는 작업도 많을 것입니다. 끝이 없습니다. 수집과 같은 유한한 것을 소비하지 않습니다. 채널을 통해 들어오는 모든 것을 처리하고 있습니다. 또는 이벤트 소스를 통해 들어오는 모든 것을 처리합니다. 끝이 없습니다. 하지만 끝이 있는 것에는 완료라는 개념이 있습니다. 즉, 가장 안쪽의 프로세스 단계에서 모든 것이 완료되었을 때 최종적으로 무언가를 수행하고자 하는 경우입니다. 예를 들어 다른 트랜스듀서에서 플러싱이 필요한 경우 플러싱을 수행할 수 있습니다. 따라서 프로세스는 출력에 대한 최종 변환을 수행하려고 할 수 있습니다. 특히 상태 저장 트랜스듀서, 파티션과 같은 트랜스듀서는 집계를 반환하기 위해 집계하고 있습니다. 파티션 5라고 하면 5개의 항목을 수집하여 뱉어냅니다. '완료'라고 하면 세 가지가 있습니다. 세 가지를 뱉어내려고 합니다. "입력이 소진되었습니다."라고 말할 수 있어야 합니다. 이를 위해 클로저로 구현된 트랜스듀서에서 구현된 방식은 모든 단계 함수에 두 번째 연산이 있어야 한다는 것입니다. 즉, 새로운 입력과 지금까지 누적된 값을 가져와서 새로운 누적 값 등을 반환하는 연산이 필요합니다. 블랙박스의 의미가 무엇인지는 프로세스에 달려 있습니다. 하지만 입력 없이 누적된 값만 취하는 또 다른 연산이 있어야 합니다. 바로 아리티-1 연산입니다. 이것이 필요합니다.
I talked before completion. So we have the idea of early termination. The other idea that transducers support is completion. Which is that, at the end of input, which may not happen. There will be plenty of jobs that don't complete. They don't have ends. They are not consuming a finite thing like collection. They're processing everything that comes through a channel. Or everything that comes through an event source. There's no end. But for things that have an end, there's a notion of completion which is to say, if either the innermost process step wants to do something finally when everything is finished. They can, or if any other transducers have some flushing they need to do, they can do it. And so the process may want to do a final transformation on the output. Any stateful transducer in particular, a transducer like partition, it's aggregating to return aggregates. You say, partition 5 and it collects five things and spits it out. If you say, we're done, it's got three things. It wants to spit out the three things. You need to be able to tell it, "We've exhausted input". In order to do that, the way that's implemented in the Clojure implementation of transducers is that all the step functions must have a 2nd operation. So the operation that takes the new input and the accumulated value so far and returns a new accumulated value or whatever. It's upto the process what the meaning of the black box is. But there must be another operation which takes just the accumulated value and no input. So an arity-1 operation. That's required.
# Completion Operation

그 기능이나 사용 방법에 대해 살펴보겠습니다. 프로세스 자체에서 전체 작업이 완료되면 입력이 소진되었거나 완료되었다는 개념이 있는 경우 - 이것은 바이아웃이 아닙니다 - 더 이상 할 일이 없고 일반적으로 더 이상 입력이 없는 것과 같습니다. 누적된 값에 대해 정확히 한 번만 완료 연산을 호출해야 합니다. 더 이상 입력이 없으니 입력 없이 한 번만 호출하겠습니다. 원하는 대로 하세요. 각 트랜스듀서는 동일한 작업을 수행해야 합니다. 이러한 완료 연산 중 하나가 있어야 하며 중첩된 완료 연산을 호출해야 합니다. 그러나 그 전에 플러시할 수도 있습니다. 따라서 파티션과 같이 도중에 누적된 내용이 있는 경우 일반 단계 함수를 호출한 다음 결과에 대해 완료를 호출할 수 있습니다. 이것이 플러시를 수행하는 방법입니다. 여기서 한 가지 주의할 점이 있는데, 파티션과 같은 상태 저장소이고 감소된 것을 본 적이 있다는 것입니다. 앞의 규칙에 따르면 입력 함수를 절대로 호출할 수 없으므로 매달려 있는 모든 것을 버려야 합니다. 그래서 누군가가 이 프로세스를 포기한 것입니다. 평범한 완성이란 있을 수 없습니다.
We'll take about what that does, or how that gets used. If the process itself, if the overall job is finished, it has exhausted input or it has a notion of being finished - this is not bailing out - this is like there's nothing more to do, there's no more input ordinarily. It must call a completion operation exactly once on the accumulated value. So there's no more inputs, I'm going call you once with no input. Do whatever you want. Each transducer must do the same thing. It has to have one of these completion operations and it must call its nested completion operation. It may, however, before it does that, flush. So if you have something like partition that's accumulated some stuff along the way, it can call the ordinary step function and then call complete on the result. And that's how we accomplish flushing. There's just one caveat here, which is that it you're a stateful thing like partition and you've ever seen reduced come up. The earlier rule says you can never call the input function, so you just drop whatever you have hanging around. So somebody bailed out on this process. There's going to be no ordinary completion.
# Transducer Types, Thus Far
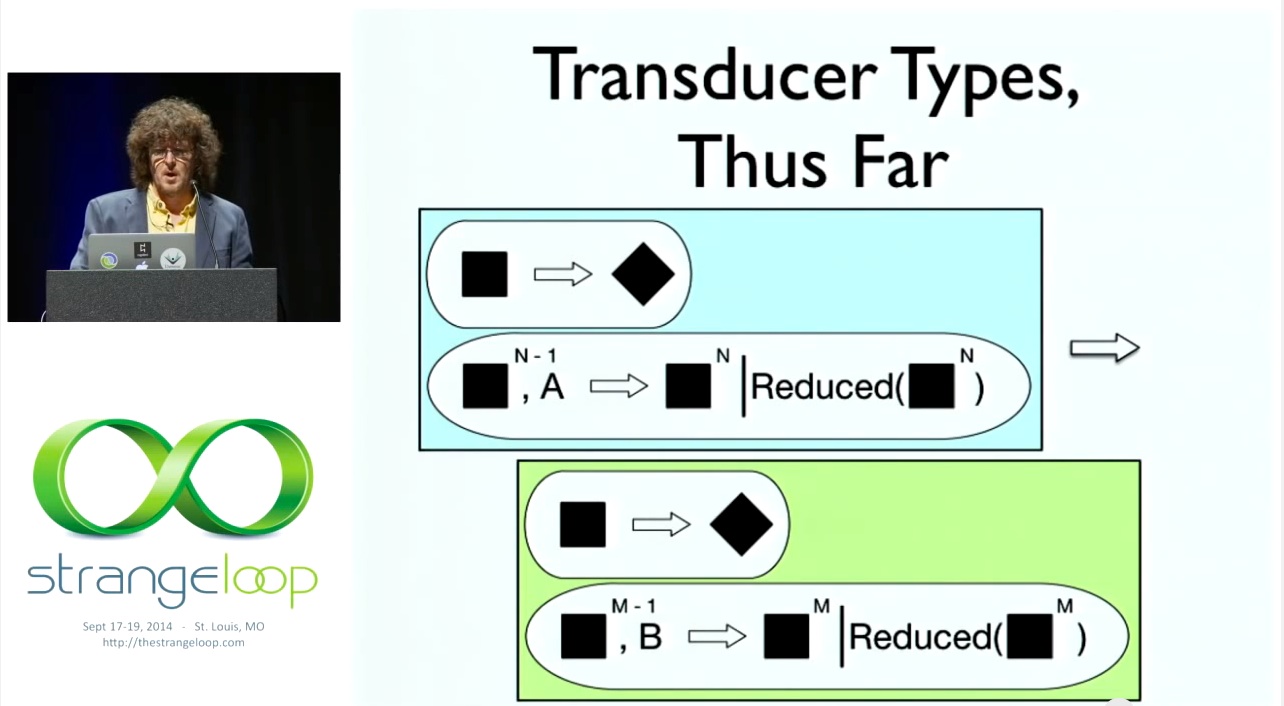
이제 OmniGraffle 2000에서 유형을 다시 살펴볼 수 있습니다. 프로그래밍 혁신이 눈에 띕니다. 그리고 환원 함수를 한 쌍의 연산으로 생각해 보세요. 프로그래밍 언어마다 다를 수 있지만 크게 중요하지 않습니다. 클로저에서는 결국 하나의 함수로 이 두 가지 특성을 모두 포착할 수 있습니다. 두 가지 연산을 수행하기 위해 필요한 것은 무엇이든 할 수 있습니다. 첫 번째는 입력이 필요 없는 완성 연산입니다. 그리고 두 번째는 지금까지 보셨던 단계 연산입니다. 이 연산은 한 쌍을 받아 한 쌍을 반환합니다. 그게 다입니다. 여기서도 결과 유형을 구체적으로 매개변수화하지 않으려 합니다. 구체적으로 매개변수화하면 일반적인 지침과 달리 비행기로 변환하는 것만 아는 무언가를 갖게 되므로 2단계 다형성이나 다른 것을 사용해야 합니다.
So we can look at our types again in OmniGraffle 2000. You notice the programming innovation. And think about a reducing function as a pair of operations. It will be different in each programming language; it's not really important. In Clojure, it ends up a single function can capture both of these arities. Whatever you need to do to take two operations. The first one up there which takes no input is the completion operation. And the second is the step operation you've been seeing so far. It takes a pair of those things and returns a pair of those things. That's it. And again, we don't want to concretely parametrize the result type there either. You have got to use rank-2 polymorphism or something because if you concretely parametrize that, you 'll have something that only knows about transducing into airplanes, as opposed to the general instructions.
# Init

일반적으로 처리와 관련된 세 번째 종류의 연산이 있는데, 이것이 바로 초기화입니다. 이전에 모노이드 등에 대해 이야기한 적이 있습니다. 기본적인 아이디어는 변환 연산이 초기화 기능을 가지고 있으면 좋을 때가 있다는 것입니다. 꼭 아이덴티티 값이나 그런 것일 필요는 없습니다. 그건 중요하지 않습니다. 중요한 것은 환원 함수가 에리티 0을 지원할 수 있다는 것입니다. 다시 말해, 아무것도 주어지지 않았을 때 초기 누적값은 다음과 같습니다. 무에서 유를 창조합니다. 물론 트랜스듀서는 블랙박스이기 때문에 그렇게 할 수 없습니다. 블랙박스가 할 수 없는 한 가지 확실한 것은 무에서 유를 창조하는 것입니다. 할 수 없습니다. 따라서 중첩된 함수를 호출하는 것밖에 할 수 없습니다. 따라서 트랜스듀서는 arity-0, 초기화를 지원해야 하며 중첩된 단계에 대한 호출로 정의할 수 있습니다. 실제로는 할 수 없지만 하위 트랜스듀서에 초기화가 있는 경우 결과 트랜스듀서에도 초기화가 있는 경우를 제외하고는 앞으로 전달할 수 있습니다. 에리티 과부하에 대해 말씀드렸으니 여기에 예제가 있습니다. 게다가 LISP에서 이것은 트랜스듀서보다 오래되었습니다. LISP 프로그래밍은 한동안 이 작업을 수행해 왔습니다. 죄송합니다, 커링 팬 여러분, 이것이 우리가 하는 일입니다. 아무것도 없는 더하기는 더하기의 고유값을 반환합니다: 0. 무의 곱셈은 1을 반환합니다. 누적된 결과에 신원이 있고 작업을 수행하는 이진 연산이 있는 경우 더하기를 구현합니다.
OK, there's a 3rd kind of operation that's associated with processing in general, which is Init. We had talks before which mention monoids and things like that. The basic idea is just, sometimes it's nice for a transformation operation to carry around an initialization capability. It need not be the identity value or anything like that. It does not matter. What does matter is that a reducing function is allowed to, may, support arity-0. In other words, given nothing at all, here's an initial accumulated value. From nothing. Obviously, a transducer can't do that because it's a black box. One thing it definitely does not know how to do is to make a black box out of nothing. Can't do it. So all it can ever do is call down to the nested function. So transducers must support arity-0, init, and they just define it in terms of the call to the nested step. They can't really do it but they can carry it forward except the resulting transducer also has an init, if the bottom transducer has an init. I've talked about the arity overloading, so here's an example. plus from LISP, this is older than transducers. LISP programming has been doing this for a while, sorry, Currying fans, this is what we do. plus with nothing returns the identity value for plus: 0. Multiplication of nothing returns 1. It implements plus if an accumulated result has identity and the binary operation that does the work.
# Transducer Types
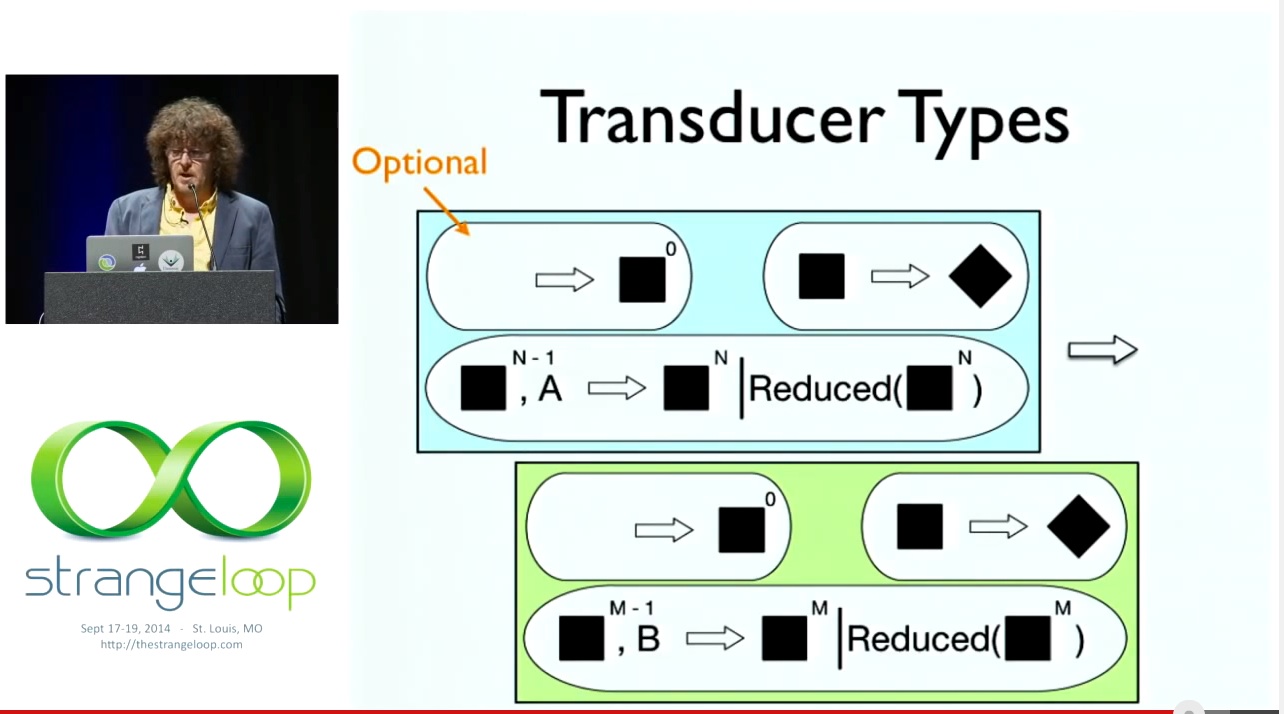
다시 유형을 정리해 보겠습니다. 이제 선택적 무에서 초기화 함수가 생겼습니다. 그리고 세 개의 연산 집합을 가져와서 세 개의 연산으로 구성된 새로운 집합을 반환합니다.
So, here's the types again. We now have an optional init from nothing. And we're taking a set of three operations and returning a new set of three operations.
# Clojure Implementation

클로저에서는 이 작업을 위해 에리티를 사용했습니다. 트랜스듀서 인클로저는 환원 함수를 받아 환원 함수가 이 세 가지 아리티를 갖는 함수를 반환하는 것일 뿐입니다. 우리는 실제로 환원 함수를 매핑과 필터링, 그리고 이것과 저것을 -하는 함수라고 부르지 않았습니다. 이는 잘 통용되지 않는 영어식 표현이라고 생각하며, 커링이 없기 때문에 에리티 오버로딩을 사용할 수 있습니다. 따라서 컬렉션 인자가 없는 f의 맵은 트랜스듀서를 반환합니다. 이를 위해 지금까지 모든 시퀀스 함수를 수정했습니다.
In Clojure, we just used arity to do this. A transducer enclosure then is just something that takes a reducing function and returns one where a reducing function has these 3 arities. We haven't actually called the reducing functions mapping and filtering and -ing this and -ing that. We think that's an Englishism that's not going to carry over very well, and we have available to us arity overloading because we don't have currying. So map of f with no collection argument returns a transducer. And we modified so far all of these sequence functions to do that.
# Filter, returning a Transducer
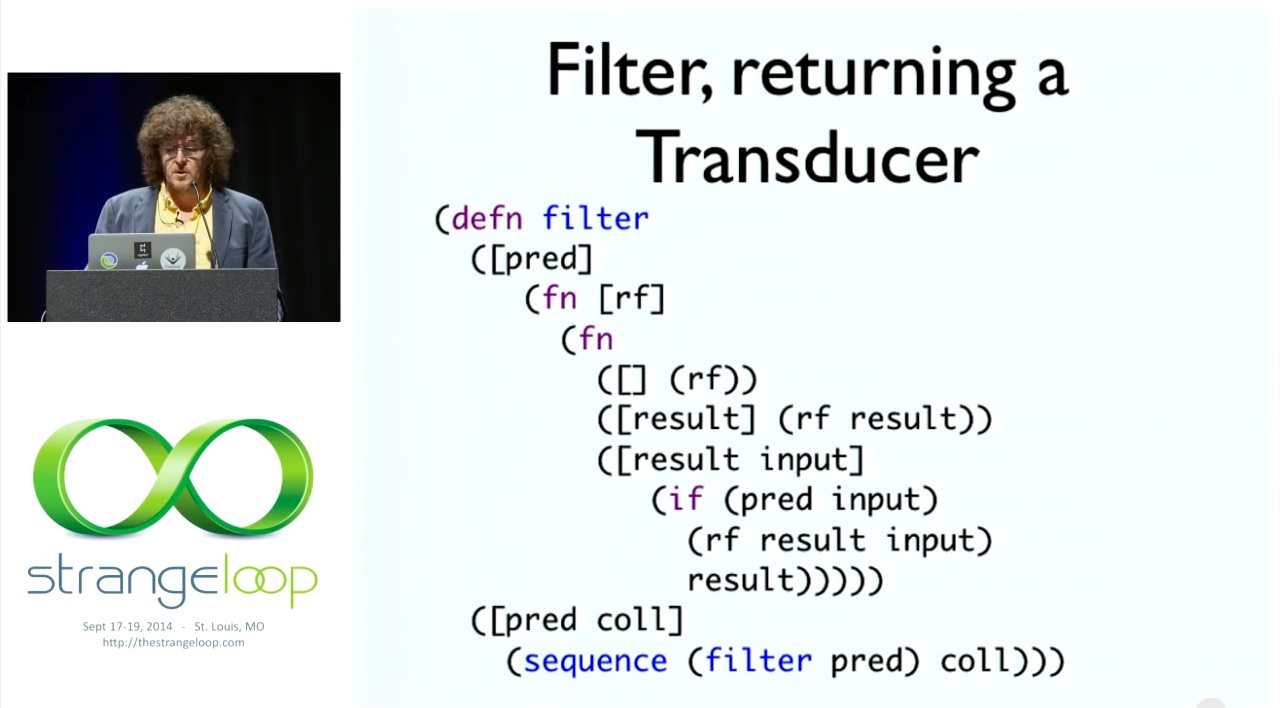
이것이 트랜스듀서를 반환하는 필터의 마지막 예제입니다. 이 예제에서는 술어를 취하고 단계 수정 함수를 반환하는데, 이 단계 수정 함수는 아마도 이 세 가지 요소를 가진 환원 함수를 취하고 세 가지 요소를 가진 함수를 정의합니다. init: 필터는 무엇을 할 수 있을지 모르기 때문에 그냥 통과시킵니다. complete: 필터는 특별한 할 일이 없기 때문에 그냥 통과시킨 다음 결과와 입력된 것을 반환합니다. 이제 이 트랜스듀서로 시퀀스를 호출하는 것만으로 컬렉션을 구현하는 것을 정의할 수 있습니다. 이 모든 함수가 마찬가지입니다. 컬렉션 버전도 이와 똑같습니다. 트랜스듀서가 다른 것보다 더 원시적이라는 것을 알 수 있습니다.
So this is the final example of filter returning a transducer. It takes a predicate and returns us a step modifying function, which takes a reducing function, which presumably has these three arities, and defines a function with 3 arities. init, which just flows it through because it doesn't know what it could possibly do. complete: filter doesn't have anything special to do, so it just flows that through and then the result and input one which is the one we've seen before. Now we can see, we can define collection implementing one by just calling sequence with this transducer. And that's true of all of these functions. You're going to find the collection version exactly like this. Which shows that transducer is more primitive than the other.
# The Goal
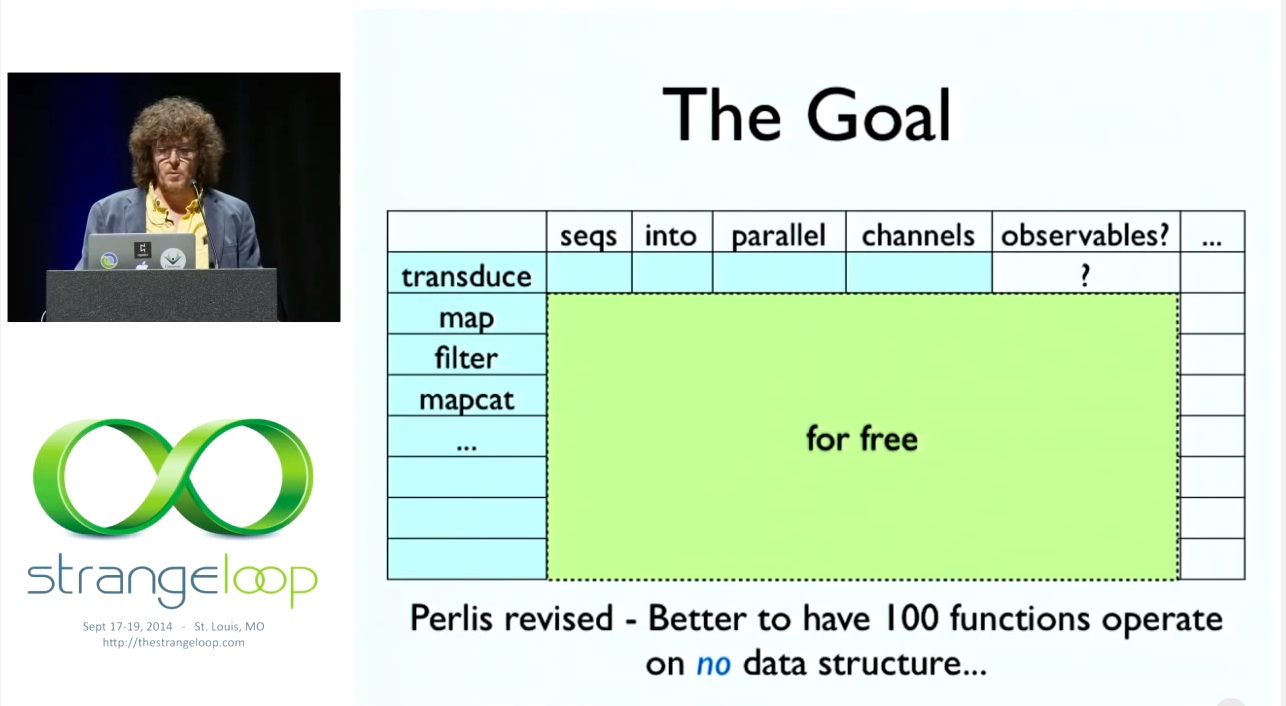
이것이 바로 우리가 달성하고자 하는 목표입니다. 트랜스듀서 세트를 한 번만 정의하면 됩니다. 새로운 멋진 기능을 모두 정의할 수 있습니다. 오늘은 채널, 내일은 옵저버블, 그 다음날은 무엇이든 상관없습니다. 트랜스듀서를 받아들이도록 설정하기만 하면 이러한 기능의 모든 구체적인 구현이 무료로 제공됩니다. 그리고 누군가가 만든 모든 레시피는 이러한 트랜스듀싱 작업의 구성이며, 여러분의 작업과 함께 즉시 작동합니다. 이것이 바로 우리가 원하는 것이죠? Perlis를 가져와서 더 좋다고 말할 수 있습니다. 데이터 구조가 없는 수백 개의 함수를 원합니다.
So this is what we're trying to accomplish. You define a set of transducers once. You define all your new cool stuff. So channels today, observables tomorrow, whatever the next day. You just make it accept transducers, and every specific implementation of these things, you get for free. And every recipe somebody creates, that's a composition of those transducing operations, works with your thing right away. That's what we want, right? We're going to take Perlis and just say it's even better. We want a hundred functions with no data structure.
"하나의 데이터 구조에서 100개의 함수가 작동하는 것이 10개의 데이터 구조에서 10개의 함수가 작동하는 것보다 낫다."와 관련하여. - 앨런 펄리스 (opens new window)
in reference to "It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures." - Alan Perlis (opens new window)
# Transducers
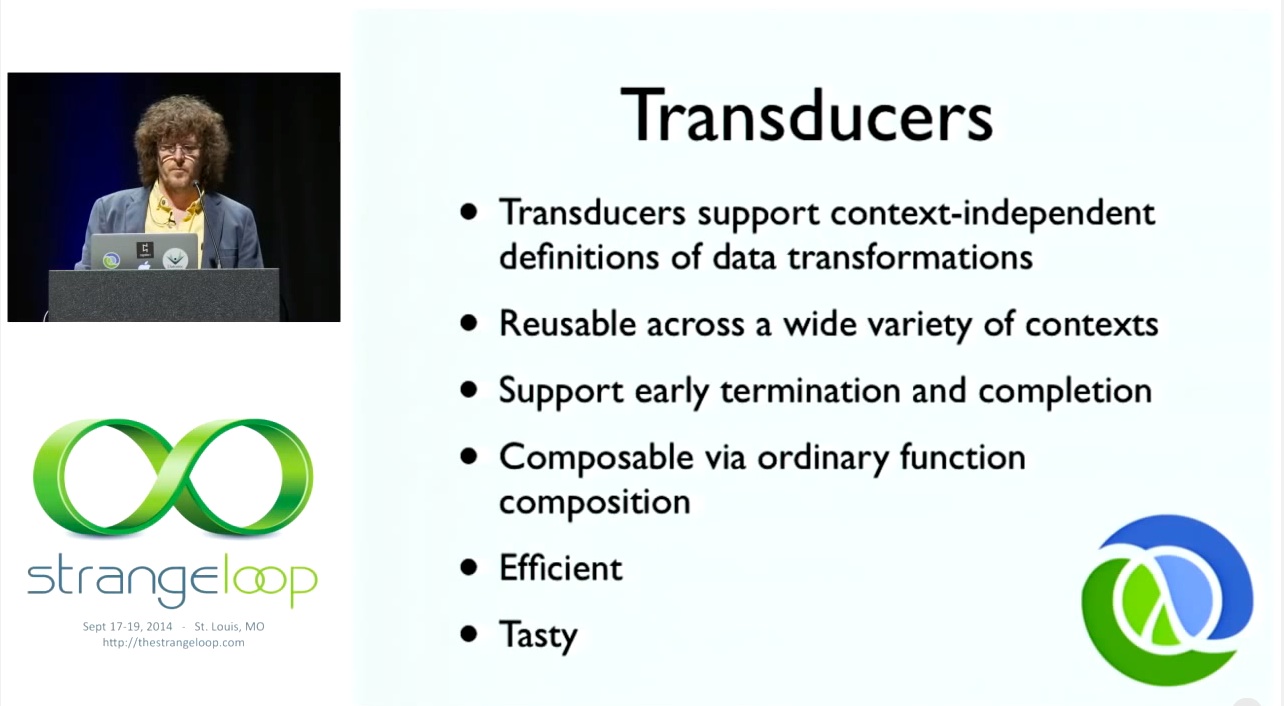
따라서 트랜스듀서는 상황에 구애받지 않습니다. 여기에는 엄청난 가치가 있습니다. 구체적으로 재사용이 가능합니다. 따라서 다른 사람이 이걸 만들 수 있고 내가 어떻게 사용하든 상관없습니다. 이는 엄청난 가치가 있습니다. 매개변수화보다 훨씬 더 강력합니다. 유동적일 수 있기 때문입니다. 조기 종료와 완성을 지원합니다. 다른 것을 구성하는 것처럼 쉽게 구성할 수 있습니다. 효율적이고 맛있습니다.
고마워요.
So, transducers are context independent. There's tremendous value in that. They're concrete re-reusable. So someone can make this and not how you're going to use it. That has tremendous value. It's much stronger than parametrization. Because you can flow it. They support early termination, completion. You can compose them just as easily as you can compose the other ones. They're efficient and tasty.
Thanks.
[박수]
[applause]