# 영구 데이터 구조 및 관리되는 참조 (Persistent Data Structures and Managed References)
- Speaker: Rich Hickey
- Conference: QCon - Oct 2009
- Video: http://www.infoq.com/presentations/Value-Identity-State-Rich-Hickey (opens new window)
[Google Bard 요약] Rich Hickey는 2009년 10월 1일 "Persistent Data Structures"라는 제목의 강연을 했습니다. 이 강연에서 Hickey는 영구 데이터 구조의 개념과 장점에 대해 설명했습니다. 영구 데이터 구조는 변경할 수 없는 데이터 구조로, 변경할 때마다 새 데이터 구조를 생성합니다. 이로 인해 영구 데이터 구조는 변경할 수 있는 데이터 구조보다 효율적이고 안전합니다. Hickey는 또한 영구 데이터 구조를 구현하는 데 사용할 수 있는 몇 가지 도구와 라이브러리에 대해 설명했습니다.
다음은 Hickey의 강연에서 다룬 주요 내용입니다.
- 영구 데이터 구조는 변경할 수 없는 데이터 구조입니다.
- 영구 데이터 구조는 변경할 수 있는 데이터 구조보다 효율적이고 안전합니다.
- 영구 데이터 구조를 구현하는 데 사용할 수 있는 몇 가지 도구와 라이브러리가 있습니다.
[Time 0:00:00]

함수형 프로그래밍 언어로 프로그래밍하는 사람이 몇 명이나 될까요? 좋아요, 회심자에게 반쯤 설교를 한 셈이군요. 함수형 프로그래밍 언어가 아니라면요? 함수형 프로그래밍 언어가 아니라면요? 여전히 많이 있습니다.
저는 이것이 두 청중 모두에게 유용할 것이라고 생각합니다. 특히 함수형 프로그래밍 언어가 아닌 경우, 사실 상태 표현 방식에 대한 완전한 스토리를 가지고 있는 Erlang이 아닌 경우, 다른 모든 함수형 프로그래밍 언어에는 두 가지 측면이 있습니다. 이 기능적인 부분이 있고... 그리고... 그리고.
하스켈은 타입 시스템이 이 부분을 순수하게 유지하는 아름다운 측면이 있습니다. 그리고 또 다른 측면은 '이렇게 해라, 저렇게 해라'와 같이 명령적인 부분이 있습니다. 그리고 그 쪽에 상태가 필요할 때를 대비해 기능을 제공하는 구조체가 많이 있습니다.
마찬가지로 스칼라나 F#과 같은 "하이브리드" 함수형 언어도 많이 있는데, 여기서 질문해야 할 부분이 있다고 생각합니다: 여기까지가 순수한 부분인데, 다른 부분은 어떤 이야기일까요?
How many people program in a functional programming language? OK, so halfway preaching to the converted. And not in a functional programming language? A non-functional programming language? So still a lot of that.
I think this will be useful to both audiences. In particular if you are not in a functional programming language, in fact if you are not in Erlang, which I think has a complete story for how they do state, all the other functional programming languages have two aspects. They have this functional part, and then ... and then.
Haskell has this beautiful side where the type system keeps this part pure. And then there is the other part which is kind of imperative: do this, do that. And then they have a bunch of constructs to provide facilities for when you need state on that side.
Similarly there are a lot of "hybrid" functional languages, like Scala and F#, where I think there are questions to be asked about: OK here is the pure part, what is the story about the other part?
[Time 0:01:13]
# Agenda

그래서 오늘 제가 하고 싶은 이야기는 기능과 프로세스에 대해 이야기하고 이 둘을 구분하는 것입니다. 사실 이 강연의 핵심 개념은 아이덴티티, 상태, 값이 의미하는 바를 분석하고 이러한 개념을 분리하는 것입니다. 그리고 값으로 프로그래밍하는 것이 프로그램의 기능적인 부분에서는 매우 중요한 부분이지만, 실제로 상태를 관리하고 상황이 변화하는 것처럼 동작해야 하는 비기능적인 부분에서는 어떻게 중요한 부분이 되는지 살펴봅니다.
여기에는 두 가지 요소가 있습니다. 하나는 복합 객체를 값으로 어떻게 표현할 것인가입니다. 함수형 프로그래밍을 처음 접하는 많은 사람들이 효율성과 표현 문제에 대해 궁금해하는데, 이에 대해 이야기하겠습니다. 그리고 마지막으로 프로그램에서 상태와 변화를 다루는 한 가지 접근 방식에 대해 이야기할 것인데, 이는 제가 시작하려는 약간의 철학과 호환되는 클로저에서 사용하는 접근 방식입니다.
So what I want to do today is to talk about functions and processes, and to distinguish the two. In fact, the core concept in this talk is to try to parse out what we mean by identity, state, and values; try to separate those concepts. And see how programming with values, while a really important part of the functional part of your program, ends up being a critical part of the non-functional part of your program, the part that actually has to manage state and behave as if things are changing.
And there are two components to that. One is: how do you represent composite objects as values? A lot of people who are new to functional programming wonder about the efficiency and representation issues there, and I will talk about that. And finally I will talk about one approach to dealing with state and change in a program, the one that Clojure uses, which is compatible with a little bit of philosophy that I am going to start with.
[Time 0:02:11]
# Clojure Fundamentals
 저는 클로저에 대해 별로 이야기하지 않으려고 합니다. 어제 제 강연에 몇 명이 참석했나요? 좋아요, 클로저에 대해 모르는 사람이 몇 명이나 있었나요? 좋아요. 이번 강연은 클로저에 관한 강연이 아닙니다. 나중에 코드가 좀 나올 겁니다. 너무 위협적이지 않아야 합니다. 이 한 장의 슬라이드로 클로저가 무엇인지 간단히 요약해 보겠습니다.
저는 클로저에 대해 별로 이야기하지 않으려고 합니다. 어제 제 강연에 몇 명이 참석했나요? 좋아요, 클로저에 대해 모르는 사람이 몇 명이나 있었나요? 좋아요. 이번 강연은 클로저에 관한 강연이 아닙니다. 나중에 코드가 좀 나올 겁니다. 너무 위협적이지 않아야 합니다. 이 한 장의 슬라이드로 클로저가 무엇인지 간단히 요약해 보겠습니다.
클로저는 동적 프로그래밍 언어입니다. 동적으로 입력됩니다. 기능적입니다. 특히 고차 함수를 지원하는 것뿐만 아니라 불변성을 강조하는 데 기능적입니다. 클로저의 모든 데이터 타입은 불변입니다.
동시성을 지원합니다. 이것은 두 부분으로 나뉩니다. 하나는 불변성과 순수 함수를 잘 지원해야 한다는 것입니다. 다른 하나는 한 번에 여러 가지 일이 일어나고 인식할 수 있는 변화가 있을 때를 대비한 스토리가 있어야 하는데, 클로저는 이를 지원합니다. 사실 기능적이라고 주장하는 언어에서 비기능적 부분에 대한 스토리를 갖는 것은 중요한 부분이라고 생각합니다.
클로저는 특별히 객체 지향적이지 않습니다. 이 강연을 듣고 나면 왜 그렇지 않은지 알 수 있는데, 현재 구현된 많은 객체 기술이 동시성과 함수형 프로그래밍에 직면했을 때 큰 문제를 가지고 있다고 생각하기 때문입니다. 그리고 앞서 말했듯이 개념적인 관점에서 볼 때 클로저에만 국한된 것은 아무것도 없습니다.
I am not really going to talk about Clojure very much. How many people were at my talk yesterday? OK, how many people who were not know something about Clojure? OK. This is not really a Clojure specific talk. There will be some code later. It should not be too threatening. I am just going to summarize quickly with this one slide what Clojure is about.
It is a dynamic programming language. It is dynamically typed. It is functional. In particular, it is functional in emphasizing immutability, not just in supporting higher order functions. All the data types in Clojure are immutable.
It supports concurrency. It is a two part story. One is: you have to have good support for immutability and pure functions. The other part is: you have to have a story for when multiple things are happening at a time and you are going to have some perceptible change, and Clojure does. In fact, I think it is an important part of a language that purports to be functional to have a story about the non-functional parts.
Clojure is not particularly object oriented. It may be clear after listening to this talk why not, because I think as currently implemented, a lot of object technologies have big problems when they face concurrency and functional programming. And as I said, from a conceptual standpoint, nothing about this is really Clojure specific.
[Time 0:03:32]
# Functions

그렇다면 함수는 무엇을 의미할까요? "함수는 호출하는 것"이라고 아주 쉽게 말할 수 있지만, 여기서 말하는 함수는 그런 것이 아닙니다. 여기서 말하는 함수는 값을 인자로 받아 반환값으로 값을 생성하는 함수를 호출하는 매우 정확한 개념입니다. 동일한 인수가 주어지면 항상 동일한 값을 생성합니다.
외부 세계에 의존하지 않습니다. 나머지 세계에 영향을 주지 않습니다. 클래스의 많은 메서드가 이 정의에 따라 함수가 아니지만, 특히 순수 함수인 함수는 시간 개념이 없다는 사실을 강조하고 싶습니다. 이 강연을 통해 시간은 중요한 개념이 될 것입니다.
So what do we mean by functions? I think that there is a really easy way to say, "Oh, a function is something that you call", and that is not what we are talking about here. We are talking about a very precise notion of a function, which is something that you call that takes values as arguments and produces a value as a return. When it is given the same arguments, it always produces the same value.
It does not depend on the outside world. It does not affect the rest of the world. So many methods in your classes are not functions by this definition, but in particular too, I want to highlight the fact that function, pure functions, have no notion of time. Time is going to be a critical notion through this talk.
[Time 0:04:12]
# Functional Programming

그렇다면 함수형 프로그래밍이란 무엇일까요? 이 질문에는 많은 답이 있으며, 타입 시스템에 관심이 있는 사람들은 함수형 프로그래밍을 구성하는 요소에 대해 더 강력한 주장을 주장할 것이라고 생각합니다. 하지만 여기서는 함수를 사용한 프로그래밍을 강조하는 프로그래밍으로 정의를 제한하겠습니다. 따라서 가능한 한 많은 프로그램을 순수 함수로 작성하려고 노력해야 합니다. 그렇게 하면 많은 이점을 얻을 수 있습니다. 다른 강연에서도 다뤘던 내용입니다. 동시성이 없어도 프로그램이 더 이해하기 쉽고, 더 추론하기 쉽고, 더 테스트하기 쉽고, 더 모듈화된다는 것 외에는 이 강연의 초점이 아닙니다. 이 모든 것은 함수를 사용한 프로그래밍에서 가능한 한 많이 벗어날 수 있습니다.
반면에 한 발 물러서서 전체 프로그램을 살펴보면 전체적으로 함수로 된 프로그램은 거의 없습니다. 하나의 입력을 받아 생각하고 하나의 출력을 생성하는 프로그램은 거의 없습니다. 일부 컴파일러나 정리 증명기는 그런 식으로 작동할지 모르지만, 제가 작업해본 대부분의 실제 프로그램, 그리고 현실 세계의 대부분의 실제 프로그램은 그런 식으로 작동하지 않는다고 생각합니다.
특히, 프로그램이 완전히 작동한다고 주장하더라도 출력을 생성하는 경우 그렇지 않습니다. 그렇지 않으면 기계를 예열 할 뿐이기 때문입니다. 그러나 대부분 기능적이라 할지라도 순전히 기능적인 프로그램이 실행되면 관찰 가능한 효과가 있습니다. 컴퓨터에서 실행 중입니다. 컴퓨터에서 실행되는 즉시 더 이상 수학이 아닙니다. 컴퓨터에서 실행되는 프로그램입니다. 메모리를 소비하고 있습니다. 시계 주기를 소비하고 있습니다. 그것은 시간이 지남에 따라 관찰 가능하게 무언가를하고 있습니다. 따라서 모든 프로그램은 시간이 지남에 따라 작업을 수행합니다.
그러나 제가 말했듯이 대부분의 실제 프로그램은 실제로 컴퓨터에서 실행되고 있다는 사실뿐만 아니라 작업을 수행하는 관찰 가능한 동작을 가지고 있습니다. 그들은 외부 세계와 상호 작용하고 있습니다. 그들은 소켓을 통해 이야기하고 있습니다. 화면에 무언가를 넣고 있습니다. 데이터베이스에 무언가를 넣거나 뺍니다.
특히 상태를 정의하는 방법에 대해 한 가지 중요한 척도를 사용하겠습니다. 즉, 같은 질문을 두 번 했는데 다른 대답이 나오면 상태가 있는 것입니다. 어디에 넣어도 상관없습니다. 프로세스에 넣을 수도 있고 에이전트, 원자, 변수에 넣을 수도 있습니다. 데이터베이스에서는 중요하지 않습니다. 같은 질문을 두 번 하고 다른 시간에 다른 답을 얻는다면 상태가 있는 것입니다. 그래서 다시 "시간"이라는 단어가 다시 등장했습니다.
So what is functional programming? There are lots of answers to this question, and I think people who are into type systems will claim a stronger argument for what constitutes functional programming. But I am going to limit the definition here to programming that emphasizes programming with functions. So you want to try to write as much of your program as you can with pure functions. When you do that you get a ton of benefits. They have been talked about in other talks. It is not really the focus of this talk other than to say, even without concurrency, your program will be easier to understand, easier to reason about, easier to test, more modular, and so forth. That all falls out of programming with functions to as great an extent as possible.
On the other hand, when you step back and look at your entire program, very few programs, on the whole, are functions. You know, that take a single input, think about it, and produce a single output. Maybe some compilers or theorem provers work that way, but most real world programs that I have worked on, and I think most real world programs in the real world do not work that way.
In particular, even if you claimed your program was completely functional, if it is going to produce any output, it is not, because otherwise it will just warm up the machine. But even if it is mostly functional, there are still observable effects of a purely functional program running. It is running on a computer. As soon as it is running on a computer it is not math any more. It is a program running on a computer. It is consuming memory. It is consuming clock cycles. It is observably doing something over time. So all programs do things over time.
But most real programs, as I say, actually have observable behavior that is not just the fact that they are running on a computer, but that they are doing things. They are interacting with the outside world. They are talking over sockets. They are putting stuff on the screen. They are putting things in or out of the database.
In particular though, we will use one critical measure about how to define state, which is: if you ask the same question twice, and you get different answers, then there is state. I do not care where you put it. You can put it in a process, you put it in an agent, an atom, in a variable. It does not matter, in a database. If you ask the same question twice and get different answers at different times, you have state. So again, the word "time" just came up again there.
[Time 0:06:37]
# Processes

따라서 대부분의 프로그램은 프로세스라고 생각하기 때문에 순수하게 기능적일 수 없는 부분, 즉 시간에 따라 다른 답을 만들어내야 하는 부분에 대해 이야기해야 합니다. 어떻게 하면 반짝이는 순수한 부분으로 만든 것을 완전히 엉망으로 만들지 않고 그렇게 할 수 있을까요?
특히 저는 이 강연이 지역적 맥락에서 국가와 시간의 개념에 관한 것이라는 점을 강조하고 싶습니다. 저는 동일한 프로세스에 대해 이야기하고 있습니다. 분산 프로그램에는 완전히 다른 요구 사항과 특성이 있으며, 동일한 프로세스에서 할 수있는 것과 동일한 작업을 수행 할 수 없습니다. 그래서 저는 동일한 프로세스 동시성 및 상태에 대해서만 이야기하고 있습니다.
So I think most programs are processes, which means we need to talk about the part of your program that cannot be purely functional, the part that is going to have to produce a different answer at different times. How do you do that, and not make a complete mess out of what you created with the shiny pure part?
In particular, though, I want to highlight the fact that this talk is strictly about the notion of state and time in a local context. I am talking about in the same process. There are a completely different set of requirements and characteristics of distributed programs, where you cannot do the same things that you can do in the same process. So I am talking only about same-process concurrency and state.
[Time 0:07:35]
# State

그래서 저는 정체성, 국가, 가치, 이런 것들을 말할 때 제가 의미하는 바에 대해 좀 더 정확하게 말하고 싶습니다. 특히 상태에 대해 두 번 이야기하고 싶습니다. 하나는 일종의 일반적인 설명입니다. 상태는 한 번에 정체성의 가치입니다.
어쩌면 말이 안 될 수도 있습니다. 어쩌면 전통적인 프로그래밍 언어의 변수처럼 들릴 수도 있습니다. 전통적인 프로그래밍 언어를 사용하는 사람에게 "상태가 있나요?"라고 물어본다면 아마 이렇게 대답할 것입니다. 그들은 "네, 변수가 몇 개 있고 변수를 변경합니다"라고 대답할 것입니다. 이는 상태를 구성하는 요소에 대한 올바른 정의가 아닙니다.
그렇다면 변수는 상태일까요? 변수가 이런 일을 하나요? 시간이 지남에 따라 아이덴티티의 가치를 관리할 수 있을까요? 변수 i를 0으로 설정할 수도 있고, 42로 설정할 수도 있고, 한 변수를 다른 변수에 할당할 수도 있습니다. j는 42일까요? 상황에 따라 다릅니다. 순차적 프로그램에서는 아마도 그렇겠죠.
스레드가 있는 프로그램에서 무엇이 잘못될 수 있을까요? 이런 일이 어떤 순서로 일어났는지, 어떤 스레드에서 일어났는지는 말하지 않았습니다. 예를 들어 별도의 스레드에서 j가 i와 같다고 설정했다면 어떤 나쁜 일이 일어날 수 있을까요? 반드시 42라고 나올까요? 아니요, 절대 아닙니다. 해당 메모리가 다른 스레드의 캐시로 플러시되지 않았을 수도 있기 때문입니다. 반드시 "i"라는 휘발성이 있는 것은 아닙니다.
또 어떤 일이 일어날 수 있을까요? i가 길거나, 프로그래밍 언어에서 길이를 설정하는 것이 원자적이지 않을 수도 있습니다. 나쁩니다.
So I want to be a little bit more precise about what I mean when I say identity, state, and value, and these kinds of things. And in particular I want to talk about state and I will talk about it twice. One is just sort of a generic statement: state is the value of an identity at a time.
Maybe none of that makes sense. Maybe it sounds like a variable from a traditional programming language. Because I think if you ask somebody who is using a traditional programming language, "Do you have state?" They will be like, "Yeah I have some variables, and I change them". And that is not a good sound definition of what constitutes state.
So are variables state? Do they do this job? Do they manage the value of an identity over time? We can have a variable i, we can set it to zero, we can set it to 42, we can assign one variable to another. Is j 42? That depends. In a sequential program, probably, kinda, sorta.
In a program that had threads, what could go wrong? Well I did not say what order these things happened in, or what threads they happened in. For instances if you set j equals i in a separate thread, what bad thing could have happened to you? Would it say 42 necessarily? No, definitely not. Because that memory may not have been flushed through to the other thread's cache. It is not volatile, necessarily, "i".
What else could happen that is bad? Maybe i is a long, maybe setting a long is not atomic in your programming language. Bad.
[Time 0:09:05]
# Variables

따라서 변수는 상태 관리 작업을 수행하기에 충분하지 않습니다. 변수는 단일 제어 스레드를 전제로 합니다. 그렇지 않으면 실제로는 전혀 작동하지 않습니다. 동시성에 의해 끔찍하게 망가집니다. "이 메모리 조각이 있다"는 개념 자체가 작동하지 않습니다. 스택에 있는 변수든, 객체의 필드든, 우리 프로그램은 대부분 이 메모리를 기반으로 만들어졌기 때문에 동일한 문제가 발생합니다. 메모리 조각은 불충분한 추상화입니다.
그래서 우리는 긴 쓰기의 비원자성 문제가 있습니다. 이는 많은 언어에서 발생하는 문제로, 원자적이지 않다는 것입니다. 따라서 다른 스레드에서 보면 숫자의 절반을 얻을 수 있습니다. 쓰기 가시성과 메모리 펜스는 진정한 동시 상자에서 여러 개의 스레드가 제어하는 경우 고려해야 합니다.
만약 어떤 객체가 있고, 그 객체의 상태를 구성하는 이런 것들이 한데 모여 있다면, 이제 복합 연산을 구성해야 하는 문제가 생깁니다. 다른 유효한 상태로 만들려면 이러한 여러 가지 가변적인 것들을 건드려야 하기 때문에 이제 "내 언어가 작성할 때 그렇게 생각했으므로 제어 스레드가 하나만 있는 것처럼 보이게 하려면 내게서 떨어져 있어라"라는 잠금이나 일종의 동기화를 적용하거나 복사한 언어가 작성할 때 그렇게 생각한 것처럼 보이게 할 수 있습니다.
이 모든 것이 같은 문제의 예입니다. 우리는 시간 부족으로 인한 모델 부재를 해결해야 합니다. 시간이 없다면 변수가 있어도 소용이 없으니까요. 잠시만 생각해 보세요. 시간 개념이 없다면 변수가 왜 필요할까요? 나중에 다시 돌아가서 다른 것을 볼 수 없다면 그게 무슨 변수가 될까요?
So variables are not going to be good enough to do the job of managing state. They are predicated on a single thread of control. They actually do not work at all, otherwise. They are horribly broken by concurrency. The whole notion of, "there is this piece of memory", does not work. And our programs are built substantially on this, whether it is a variable sitting on the stack, or fields in your object, same problems. Pieces of memory are insufficient abstractions.
So we have the problem of non-atomicity of long writes. That is a problem in a lot of languages, that it is just not atomic. So you could get half of a number if you look at it from another thread. Write visibility and memory fences have to be accounted for once you have multiple threads of control on a true concurrent box.
If you have an object, and it has a bunch of these things collected together that constitute its state, now you have the problem of composing a composite operation. Because making it into another valid state requires touching several of these variable things, which now makes you impose locks or some sort of synchronization that say, "Stay away from me, so I can pretend there is only one thread of control, because that is what my language thought when they wrote it", or the language they copied thought when they wrote it.
All of these things are examples of the same problem. We are having to work around the lack of a model for time. Because there is no point to having variables if you do not have time. And just think about that for a second. If there is no time notion, why would you need a variable? If you cannot go back to it later and see something different, how is it a variable?
[Time 0:10:47]
# Time

따라서 시간에 대해 더 명확히 알고 싶다면 물리학이 아닌 강의에서는 다루지 않을 것입니다. "시간이라고 하면 어떤 것을 떠올리시나요?"라고 물어보겠습니다. 여러분은 어떤 일이 다른 일의 이전 또는 이후라고 생각합니다. 나중에 일어나는 일을 생각합니다. 동시에 일어나는 일, 두 가지 일이 동시에 일어나는 것을 생각합니다. 지금 일어나고 있는 일을 생각하는데, 이는 일종의 자기 상대적인 시간 관점입니다.
하지만 이 모든 개념은 본질적으로 상대적이라는 점에서 중요합니다. 시간에 대해 생각할 때, 시간이나 이름이 붙은 특정 순간에 대한 시간은 많지 않습니다. 우리가 생각하는 시간의 개념은 대부분 상대적인 시간, 즉 두 개의 개별적인 것 사이의 순서와 관련이 있습니다.
So if we want to be clearer about time, which we are not going to be in a non-physics lecture. We are just going to say, "What are some things you think of when you think of time?" You think of things being before or after other things. You think of something happening later. You think of something happening at the same time, two things happening at the same time. You think of something happening right now, which is sort of a self-relative perspective of time.
But all of these concepts are important in that they are inherently relative. When you think about time, there is not a lot about time that are hours, or this particular moment with a name on it. Most of our notions of time have to do with relative time, the ordering between two discrete things.
[Time 0:11:36]
# Value

따라서 시간에 대해 더 명확히 알고 싶다면 물리학이 아닌 강의에서는 다루지 않을 것입니다. "시간이라고 하면 어떤 것을 떠올리시나요?"라고 물어보겠습니다. 여러분은 어떤 일이 다른 일의 이전 또는 이후라고 생각합니다. 나중에 일어나는 일을 생각합니다. 동시에 일어나는 일, 두 가지 일이 동시에 일어나는 것을 생각합니다. 지금 일어나고 있는 일을 생각하는데, 이는 일종의 자기 상대적인 시간 관점입니다.
하지만 이 모든 개념은 본질적으로 상대적이라는 점에서 중요합니다. 시간에 대해 생각할 때, 시간이나 이름이 붙은 특정 순간에 대한 시간은 많지 않습니다. 우리가 생각하는 시간의 개념은 대부분 상대적인 시간, 즉 두 개의 개별적인 것 사이의 순서와 관련이 있습니다.
[Time 0:13:24]
# Identity

강연의 철학 부분에서 또 하나의 개념은 정체성의 개념입니다. 이것은 아마도 가장 모호한 개념이지만 중요한 개념입니다.
현실 세계에서는 어떤 일이 일어날까요? 우리가 오늘, 엄마, 조 암스트롱에 대해 이야기할 때 현실 세계에서는 어떤 일이 일어날까요? 변하지 않는 단일한 것일까요? 아니면 시간이 지남에 따라 다른 가치와 연관되는 논리적 실체가 있다고 생각할 수도 있습니다. 다시 말해, 특정 순간에는 모든 것이 정지되어 있습니다. 그리고 다음 순간 우리는 다른 것을 보게 됩니다. 이것도 같은 것일까요? 글쎄요, 만약 어떤 힘이 이 사물에 작용하여 다음 사물을 만들어냈다면, 저는 그것들을 같은 것이라고 생각합니다. 그렇지 않으면 서로 관련이 없는 것입니다. 두 가지가 같은 공간을 통과할 수 있습니다. 같은 공간에 있기 때문에 같은 것이 아닙니다.
따라서 시간 경과에 따른 값의 집합, 그 값들이 인과적으로 관련되어 있는 값에 이름을 붙여야 합니다. 이들은 서로 다른 값입니다. 서로 다른 공간에 있을 수 있습니다. 저는 이쪽으로 걸어갈 수 있습니다. 나는 여전히 부자다. 그래서 무슨 일이 일어나고 있는 걸까요?
세 가지 개념이 있으면 무슨 일이 일어나고 있는지 쉽게 이해할 수 있습니다. 상태가 있습니다: 나는 바로 여기 서 있다. [한 걸음 옆으로 이동] 상태가 있습니다: 나는 여기 서 있다. 두 가지 모두 값입니다. 시간을 잠시 멈출 수 있다면 나에 대한 어떤 것도 변하지 않을 것입니다. 왜냐하면 나는 다리를 사용하여 이쪽으로 몸을 움직이고 있고, 여전히 말을 하고 있으며, 내가 여기 있는 것과 저기 있는 것 사이의 일련의 인과적 연결을 볼 수 있기 때문입니다. 그래서 당신은 말합니다 : 그게 전부 리치입니다. 그것은 두 사람이 하는 것이 아닙니다.
정체성은 이름과 같은 것이 아닙니다. 이 점을 분명히 하고 싶어요. 저는 어머니가 있습니다. 당신은 이제 그 개념, 이 정체성을 머릿속에 가지고 있습니다. 하지만 저는 엄마라고 부르고 여러분은 히키 부인이라고 부르시겠죠.
이러한 정체성은 복합적일 수 있습니다. 뉴욕 양키스나 미국인에 대해 이야기할 수 있습니다. 그것들은 세트이지만 정체성이기도 합니다. 시간이 지남에 따라 변화하지만 특정 시점에서는 가치가 있습니다. 지금 뉴욕 양키스에 있는 사람들이 바로 그런 사람들입니다. 프로세스인 모든 프로그램에는 정체성을 위한 메커니즘이 필요합니다. 이 모든 것이 함께 진행됩니다.
So one more concept in the philosophy portion of the talk, which is the concept of identity. This is probably the most nebulous of these things, but it is an important thing.
What happens in the real world? What happens in the real world when we talk about today, or mom, or Joe Amstrong? Is that a single unchanging thing? Or one way to think about it is: we have a logical entity, that we associate with different values over time. In other words, at any particular moment, everything is frozen. And the next moment we look, we see something different. Is that the same thing? Well, if some force has acted on this thing to produce that next thing, I consider it to be the same thing. Otherwise, they are unrelated things. Two things can pass through the same space. They are not the same thing because they are in the same space.
So a set of values over time, where the values are causally related, is something we need to name. These are different values. They may be in different spaces. I can walk over here. I am still Rich. So what is happening?
What is happening is easy to understand if you have three notions. There is a state: I am standing right here. [moves a step sideways] There is a state: I am standing over here. They are both values. If you could stop time for a second, nothing about me would be changing. And it is me, because I am using my legs to move myself over here, and I am still talking, and you see a set of causal connections between me being here and being there. So you say: that is all Rich. That is not two people doing this.
Identities are not the same things as names. I just want to make that clear. I have a mother. You now have that concept in your head, this identity. But I call her mom, and you would call here Mrs. Hickey, I hope.
These identities can be composite. We can talk about the New York Yankees, or Americans, no problem. Those are sets, but they are also identities. They change over time, but at any particular point in time they have a value. These are the guys who are on the Yankees right now. Any program that is a process needs to have some mechanism for identity. This all goes together.
[Time 0:15:52]
# State

이제 돌아가서 상태에 대해 이야기하겠습니다. 의미 있는 용어가 몇 가지 있습니다. 이제 상태는 한 번에 정체성의 가치라고 말할 수 있습니다. 이해가 되시길 바랍니다. 정체성은 논리적 인 것이지 반드시 장소가 아니며 기억의 조각이 아닙니다. 값은 절대 변하지 않는 것입니다. 그리고 시간은 상대적인 것입니다.
이제 상태에 변수를 사용할 수 없는 이유를 쉽게 알 수 있을 것입니다. 특히 변수는 불변하는 것을 참조하지 않을 수 있으므로 이미 [부저음을 내는 것]이 문제입니다. 변수를 변수를 참조하는 것으로 만들면 모래 위에 건물을 짓는 것과 같습니다. 핵심 개념은 변수 또는 우리가 시간을 관리하기 위해 무엇을 하든 값을 참조해야 한다는 것입니다.
우리가 전통적으로 사용하는 변수 집합은 원자 단위로 구성되지 않기 때문에 값을 구성할 수 없습니다. 값은 불변하는 것을 의미하기 때문입니다. 부품을 독립적으로 변경할 수 있다면 한 부품은 중간에 있고 다른 부품은 없는 순간이 있을 것이기 때문에 불변이 아닙니다. 지금은 유효한 값이 아닙니다. 중간에 무언가가 일어나고 있습니다.
변수에 대해 좀 더 글로벌하게 말하자면, 변수의 문제는 상태 전환 관리가 없다는 것입니다. 이것이 바로 시간 관리, 즉 시간에 대한 조정 모델입니다. 내가 이 상태였다가 지금은 저 상태이고, 두 상태 모두 불변의 값인 상태에서 어떻게 전환할 수 있을까요?
So I will go back and talk about state. We have some terms that hopefully mean something. Now we can say: a state is a value of an identity at a time. Hopefully that makes sense. The identity is a logical thing, it is not necessarily a place, it is not a piece of memory. A value is something that never changes. And time is something that is relative.
Now it is easy to see, I think, why we cannot use variables for state. In particular, that variable may not refer to something that is immutable, so already [makes buzzer sound] that is a problem. If you make a variable refer to a variable, you are building on sand. The key concept is: variable -- or whatever we are going to do to manage time -- has got to refer to values.
Sets of variables, as we traditionally have them, can never constitute a value, because they are not atomically composite. Because we are saying a value is something that is immutable. If you can change the parts independently, then it is not immutable, because there is going to be a moment when one part is halfway there and another part is not there. That is not a valid value now. Something is happening in the middle.
And more globally you can say about variables, their problem is they have no state transition management. That is the management of time, a coordination model for time. How do you go from: I am in this state, now I am in that state, both states being immutable values.
[Time 0:17:20]
# Philosophy

이것이 철학 부분의 요약입니다. 제가 생각하는 핵심 개념은 '모든 것은 제자리에서 변하지 않는다'입니다. 우리는 그렇게 생각하지만 실제로는 그렇지 않습니다. 이것이 사실임을 알 수 있는 방법은 시간을 차원으로 통합하는 것입니다. 시간이 차원이 되고, x, y, z, 시간이 생기면 그 다음이 뭔지 아세요? 바로 여기입니다. 여기서 어떤 일이 일어나고 있다면 이것도 다르지 않습니다. 상황은 제자리에서 변하지 않습니다. 시간은 계속 진행됩니다. 과거의 함수가 미래를 만듭니다. 하지만 두 가지 모두 가치입니다.
제가 지금부터 보여드릴 디자인에는 로컬 컨텍스트에서 시간을 모델링하려고 할 때 중요하다고 생각하는 몇 가지 측면이 있습니다. 이런 것들은 제가 포기하고 싶지 않은 것들입니다. 예를 들어 Java에서는 무차별 대입을 통해 달성할 수 있는 것들인데, Clojure에서 달성할 수 없다면 제 언어를 판매할 수 없습니다. 즉, 공동 배치된 엔티티는 협력 없이도 서로를 볼 수 있습니다. 협력이 필요한 메시징 모델이 많이 있습니다. 상대방이 어떤 사람인지 확인하려면 질문을 해야 합니다. 여러분은 그 질문을 받을 준비가 되어 있어야 합니다. 내 질문에 기꺼이 대답할 준비가 되어 있어야 합니다.
하지만 함께 있을 때는 그렇지 않습니다. 옆 건물에서 무슨 일이 일어나고 있는지 모르지만 여러분 모두를 볼 수 있고, 허락을 받지 않고도 여러분의 뒷모습을 확실히 볼 수 있습니다.
로컬 환경에서 정말 중요하다고 생각하는 또 다른 한 가지는 - 분산된 환경에서는 불가능하다고 생각해야 하지만 - 같은 프로세스에서 함께 위치한 조직과 조율된 방식으로 일을 할 수 있다는 점입니다. 우리 모두 함께 일하자, 지금 당장 이 모든 것을 해보자고 말할 수 있습니다. 분산되어 있으면 그렇게 할 수 없습니다. 그래서 제가 보여드리려는 모델은 공동 위치 엔티티의 가시성과 조정을 지원합니다.
So this is the summary of the philosophy portion. A key concept I think is: things do not change in place. We think that they do, but they do not. The way you can see that this is the case is to incorporate time as a dimension. Once time is a dimension, once you have x, y, z, time, guess what? That is over here. If something is happening here, this is no different. Things do not change in place. Time proceeds. Functions of the past create the future. But both things are values.
There are a couple of aspects, I think, to the design of the things I am going to show you that I think are important when you try to model time in the local context. These are things I do not want to give up. These are things I know I can achieve by brute force in Java, and I cannot sell my language if I cannot achieve them in Clojure, for instance. Which is: co-located entities can see each other without cooperation. There are a lot of messaging models that require cooperation. If I want to see what you are about, I have to ask you a question. You have to be ready to be asked that question. You have to be willing to answer my question.
But that is not really the way things are when you are co-located. I do not know what is happening in the next building, but I can see all of you, and I can certainly look at the back of your head without asking you permission.
The other thing that I think is really important in a local context -- it really should be written off as impossible in a distributed context -- is: you can do things in a coordinated manner with co-located entities in the same process. You can say: let us all work together, and do this all right now. As soon as you are distributed, you cannot do that. So the models I am going to show you support visibility of co-located entities and coordination.
[Time 0:19:15]
# Race-walker foul detector

작은 예를 들어보겠습니다. 작은 경주용 반칙 감지기가 있습니다. 경보 선수는 뛰어서는 안 되고 걸어야 합니다. 한 걸음 한 걸음, 발뒤꿈치부터 내딛어야 하며 두 발이 동시에 땅에서 떨어지면 안 됩니다. 이는 반칙이며 레이스에서 퇴장당합니다.
그럼 어떻게 해야 할까요? 왼발 자세를 취하고 왼발이 땅에서 떨어져 있는 것을 확인하면 됩니다. 오른발 자세를 취하고 나서 '아, 땅에서 벗어났다'라고 말합니다. 그래서 달리고 있는 거죠?
우습게 들리지만 모든 사람이 항상 정확히 이렇게 하는 프로그램을 작성합니다. 그런데 왜 작동하지 않을까요? 우리는 그런 식으로 일할 수 없습니다. 상황이 변화하는 동안 시간과 가치를 모두 한데 묶어서 볼 수는 없습니다. 그것은 효과가 없습니다. 우리는 결정을 내릴 수 없습니다. 우리는 인간으로서 이런 식으로 결정을 내리지 않습니다.
So let us take a little example. A little race-walker foul detector. Race walkers, they have to walk, they cannot run. They have to walk step step step, heel toe, and they cannot have both feet off the ground at the same time. That is a foul, and then you get kicked out of the race.
So how do we do this? Well we go and we get the left foot position, and we see it is off the ground. We go and we get the right foot position and we say: oh, it is off the ground. So they are running, right?
It sounds funny, but everybody writes programs that do exactly this all the time, exactly this. And you wonder: why didn't it work? We cannot work that way. We cannot have time and values all munged together where things are changing while we are trying to look at them. That does not work. We cannot make decisions. We do not make decisions as human beings this way.
[Time 0:20:09]
# Approach

스냅샷과 특정 시점에 무언가를 가치로 간주하는 능력은 지각과 의사 결정에 매우 중요합니다. 그리고 이러한 기능은 인간과 마찬가지로 프로그램에서도 매우 중요합니다. 우리의 감각 시스템을 살펴보면, 감각 시스템은 우리가 완전히 대체할 수 없는 것으로 인식하는 세계를 순간적으로 엿보는 데 전적으로 초점을 맞추고 있습니다.
그렇다면 프로그래밍 방식으로 이를 어떻게 달성할 수 있을까요? 멀티코어에서 작동하고 멀티코어의 이점을 누릴 수 있는 프로그램을 작성하기 위해 우리가 지지해야 한다고 생각하는 것 중 하나는 바로 '레이스를 멈출 수 없다'는 것입니다. 달리는 사람을 멈출 수 없습니다. "우와! 네가 달리고 있는지 확인하고 싶으니 잠시만 기다려줄래?"라고 말할 수도 없습니다.
또한 주자의 협조를 기대할 수도 없습니다. 그냥 달리고 있는지 말해주실 수 있나요? 하지만 여기 오른쪽에 있는 이 사람처럼 주자를 하나의 가치로 간주할 수 있다면, 주자를 하나의 가치로 바라볼 수 있다는 점이 좋습니다. 이 사진에 포착된 시점이 있죠? 그것은 하나의 가치입니다. 시간이 진행되는 동안 왼쪽과 오른쪽을 독립적으로 볼 필요가 없습니다. 저는 하나의 가치를 손에 쥐고 있습니다. 한 시점에 포착된 사진입니다. 경기는 계속 진행되지만 오른쪽에 파울이 있는 선수가 보입니다. 두 발이 모두 땅에서 떨어져 있습니다. 쉬운 일이죠.
애플리케이션의 로직에서 이러한 종류의 용이성을 확보해야 합니다. 여러분은 값으로 작업하고 싶을 것입니다. 여러분은 가치를 검토하려고 할 때 여러분에게서 멀어지는 것들을 가지고 작업하고 싶지 않을 것입니다.
따라서 러너의 값을 얻을 수 있다면 이 작업을 수행하는 것은 문제가 되지 않습니다. 마찬가지로 보너스를 주거나 판매 보고서를 작성하기 위해 사람들이 영업을 하는 것을 막고 싶지 않습니다. 우리는 시간이 흐르고 우리의 논리를 수행할 수 있는 세상으로 나아가야 하며, 우리의 논리를 수행하기 위해 모든 사람을 멈출 필요는 없습니다. 이 두 가지는 독립적이어야 합니다.
Snapshots, and the ability to consider something as a value at a point in time, are critical to perception and decision making. And they are as critical in programs as they are to us as human beings. If you look at our sensory systems, they are completely oriented on creating momentary glimpses of a world that we would otherwise just perceive to be completely fungible.
Now how do we achieve this, programmatically? Well one of the things I think we have to advocate if we want to write programs that can work on multiple cores, and benefit from being on multiple cores, is: we cannot stop the race. We cannot stop the runner. We cannot say, "Whoa! Could you just hang on a second, because I just want to see if you are running."
Also we cannot expect the runner to cooperate. Could you just tell me if you are running? But if we could consider the runner to be a value, like this guy on the right here, it is kind of nice that we can look at him as if he was a value. There is a point in time that was captured by this photograph, right? It is a single value. I do not have to independently look at the left and right while time proceeds. I have got a value in hand. It was captured at a point in time. The race kept going, but I can see that guy has got a foul on the right. He has got both his feet off the ground. That is easy.
That is the kind of easiness you want to have in the logic of your applications. You want to be working with values. You do not want to be working with things that are running away from you as you are trying to examine them.
So it is not a problem to do this work if we can get the runner's value. In a similar way, we do not want to stop people from conducting sales so we can give them bonuses or do sales reports. We need to move to a world in which time can proceed and we can do our logic, and we do not need to stop everybody so we can do our logic. The two things have to be independent.
[Time 0:22:00]
# Approach

그렇다면 어떻게 작동할까요? 우선 값으로 프로그래밍해야 합니다. 숫자나 날짜 같은 작은 것뿐만 아니라 컬렉션, 집합 등 거의 모든 것을 표현하기 위해 값을 사용해야 합니다. 클래스로 모델링할 수 있는 것은 모두 값이어야 합니다.
이런 방식으로 작동하는 객체 지향 시스템이 존재할 수 없다는 말은 아닙니다. 제가 아는 한 그런 시스템은 없습니다. 하지만 전체 객체를 마치 값인 것처럼 바라봐야 합니다. 독립적으로 조작할 수 있는 조각으로 이루어져서는 안 됩니다. 그 객체의 새로운 상태를 원한다면 완전히 새로운 값을 만들어야 합니다.
그렇다면 시간의 문제는 무엇일까요? 그것은 훨씬 작은 문제가 됩니다. 우리가 해야 할 일은 가치의 연속을 관리할 수 있는 언어 구조나 방법을 확보하는 것뿐입니다. 아이덴티티는 시간이 지남에 따라 일련의 가치를 이어받게 됩니다. 이를 모델링할 방법만 있으면 됩니다. 우리는 순수한 함수를 가지고 있기 때문에 이전 값에서 새로운 값을 생성하는 방법을 알고 있습니다. 시간 조정 문제만 모델링하면 됩니다.
좋은 점은 두 가지를 분리할 때 메모리 조각으로 값을 통합하지 않으면 시간 의미론에 대한 여러 옵션이 생긴다는 것입니다. 이를 바라보는 다양한 방법이 있습니다. 메시지 전달도 있고 트랜잭션도 있습니다. 하지만 이제는 별도의 문제이기 때문에 다양한 옵션을 취할 수 있습니다. 심지어 같은 프로그램에서 여러 옵션을 사용할 수도 있습니다.
그래서 저는 두 가지 접근 방식이 있다고 말씀드리고 싶습니다. 한 부분은 값으로 프로그래밍하는 것이고, 다른 부분은 - 오늘 제가 이야기할 이 예제에서, 클로저의 예제에서 - "관리 참조"라는 개념으로, 변수의 모든 문제를 해결한다는 점을 제외하면 일종의 변수와 비슷하다고 생각할 수 있습니다. 즉, 조정 의미를 가진 변수이므로 이해하기 쉽습니다. 그냥 깨지지 않는 변수일 뿐입니다.
So, how does it work? Well, the first thing is: we have to program with values. We have to use values to represent not just numbers, and even small things like dates, but pretty much everything: collections, sets. Things that you would have modeled as classes should be values.
I am not saying there could not be an object-oriented system that worked this way. I do not know of one that does. But you should start looking at your entire object as if it was a value. It should never be in pieces that you could twiddle independently. You want a new state of that object, you make an entire new value.
So then, what is the problem with time? It becomes a much smaller problem. All we need to do is get some language constructs, or some way, to manage the succession of values. An identity is going to take on a succession of values over time. We just need a way to model that. Because we have pure functions, we know how to create new values from old values. We only need to model the time coordination problem.
What is nice about this is: when you separate the two things, when you have not unified values with pieces of memory, you end up with multiple options for the time semantics. You have a bunch of different ways to look at it. There is message passing, and there is transactional. But because it is now a separate problem, you can take different options. You can even have multiple options in the same program.
So I am going to say that there is a two-pronged approach. One part is programming with values, the other part is -- in this example that I am going to be talking about today, in Clojure's example -- is the concept called "managed references", which you can think of as, they are kind of like variables, except it fixes all of the problems with variables. In other words, they are variables that have coordination semantics, so they are pretty easy to understand. They are just variables that are not broken.
[Time 0:23:49]
# Persistent Data Structures

그래서 두 부분으로 나뉩니다. 이제 값에 대해 이야기하겠습니다. 함수형 프로그래밍 언어를 사용해 본 적이 없는 사람들이 처음에 움찔하는 것 중 하나는 "비싸게 들린다"는 것입니다. 주자가 발을 움직일 때마다 전체 주자를 복사해야한다면이 작업을 수행 할 방법이 없습니다.
특히 컬렉션과 같은 것에 대해 이야기하기 시작하면 사람들은 극도로 편집증에 걸립니다. 왜냐하면 그들이 알고 있는 컬렉션 클래스 라이브러리는 이 경우에는 기능이 없거나 매우 원시적인 것들이기 때문입니다. 가끔은 쓰기만 하면 전체가 복사되는 복사-온-쓰기 컬렉션도 있습니다.
그러나 복잡하지 않고 멋진 이름을 가진 기술이 있습니다. 이를 영구 데이터 구조라고 합니다. 이는 데이터베이스나 디스크와는 아무런 관련이 없습니다. 하지만 복합적인 객체를 값으로, 불변하는 것으로 효율적으로 표현하고 저렴한 방법으로 변경할 수 있는 방법입니다.
따라서 이러한 영구 데이터 구조 중 하나에 대한 변경은 실제로 따옴표로 묶여 있습니다. 변경되지 않습니다. 컬렉션이나 컴포지션의 기존 인스턴스를 가져와서 변경이 적용된 다른 인스턴스를 반환하는 함수입니다.
그러나 영구 데이터 구조에는 매우 특별한 의미가 있는데, 이러한 변경을 수행하려면 데이터 구조와 변경 작업이 컬렉션에서 기대하는 성능 보장을 충족해야 한다는 것입니다. 따라서 큰 O 로그 N 컬렉션이거나 상수 시간 액세스 또는 거의 상수 시간 액세스가 있는 컬렉션인 경우, 이러한 동작 특성이 이 변경 작업을 통해 충족되어야 합니다. 즉, 로그 N 동작이 예상되는 것에 대해 변경 작업을 수행하고 전체를 복사할 수 없다는 뜻입니다. 전체를 복사하는 것은 선형 동작이기 때문이죠? 그래서 이것이 중요한 것입니다.
영구 데이터 구조의 또 다른 중요한 측면은 때때로 라이브러리가 속임수를 쓰는 것을 볼 수 있다는 것입니다. 가장 최신 버전을 좋은 불변의 값으로 만들지만, 그 과정에서 이전 버전을 망가뜨리는 것입니다. 이 또한 지속적이지 않습니다. 이것이 바로 지속성이라는 단어의 또 다른 핵심 측면입니다. 영구 데이터 구조에서는 새 버전을 만들 때 이전 버전은 완벽하게 정상입니다. 변경되지 않습니다. 그대로 유지됩니다. 동일한 성능이 보장됩니다. 새로운 값을 생성해도 성능이 저하되지 않습니다.
모든 함수형 프로그래밍 언어는 이 부분을 속이려고 시도하고 결국에는 "이전 버전이 쇠퇴하거나 멀티 스레딩 관점이나 성능 관점에서 기괴한 동작이 발생하는 논리적 비용이 너무 높기 때문에 모두 불변으로 가고 성능 비용이 무엇이든 지불 할 것입니다"라고 말합니다. 그래서 제가 보여드리려는 것은 이전 값과 동일한 성능 특성을 갖는 합법적인 영구 컬렉션입니다.
그리고 제가 보여드릴 구체적인 예제는 클로저에 있는 예제입니다. 이것은 필 백웰이 이상적인 해시 시도라고 부르는 이상적인 해시 시도에 대해 수행한 일부 작업에서 파생된 것입니다. 그리고 정말 좋은 성능을 가진 비트 매핑 해시 시도가 있습니다. 그의 버전은 지속적이지 않았기 때문에 제가 클로저에서 한 일은 지속성을 만드는 것이었습니다.
So there are two parts. We are going to talk now about the values. One of the things that people cringe at initially, if they have not used functional programming languages before, is "that sounds expensive". If I have to copy the whole runner every time he moves his foot, there is just no way I am going to do this.
And in particular, when you start talking about collections and things like that, people get extremely paranoid. Because what they know are sort of the very bad collection class libraries they have, which either have no capabilities in this case, or some very primitive things. Sometimes there are copy-on-write collections, where every time you write to it, the entire thing gets copied.
But there is a technology, which is not complicated, and it has a fancy name. It is called a persistent data structure. That has nothing to do with databases or disks. But it is a way to efficiently represent a composite object as a value, as an immutable thing, and to make changes to that in an inexpensive way.
So change for one of these persistent data structures is really just in quotes. They do not change. It is a function that takes an existing instance of the collection or composite, and returns another one that has the change enacted.
But there is a very particular meaning to Persistent Data Structures, which is that, in order to make these changes, the data structure and the change operation have to meet the performance guarantees you expect from the collection. So if it is a big O log N collection, or a collection that has constant time access, or near constant time access, those behavioral characteristics have to be met by this changing operation. It means you cannot conduct the change on something that you expect to have log N behavior and copy the entire thing, because copying the entire thing is linear behavior, right? So that is the critical thing.
The other critical aspect of persistent data structure is: sometimes you will see libraries try to cheat. They will make the very most recent version this good immutable value, but on the way they ruin the old version. That also is not persistent. That is another key aspect of the word persistent. In a persistent data structure, when you make the new version, the old version is perfectly fine. It is immutable. It is intact. It has the same performance guarantees. It is not decaying as you produce new values.
Every functional programming language tries to cheat this side, and eventually says "forget this, we are going all immutable and we are going to pay whatever the performance costs are, because the logical cost of having old versions decay, or have some bizarre behavior either from a multi-threading perspective or performance perspective, is too high". So what I am going to show you are legitimate persistent collections where the old values have the same performance characteristics.
And the particular example I am going to show you is the one that is in Clojure. It is derived from some work that Phil Bagwell did on these ideal, he called him ideal hash tries. And there are bit mapped hash tries that have really good performance. His versions were not persistent, and so what I did for Clojure was I made them persistent.
[Time 0:26:57]
# Bit-partitioned hash tries
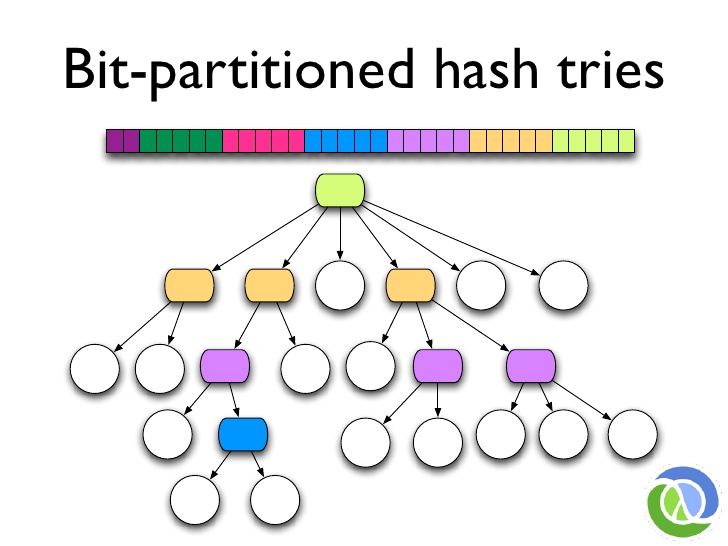
모든 영구 데이터 구조의 비밀은 바로 시도라는 점입니다. 이제 알겠습니다. 이제 아시겠죠. 다양한 방법이 있으며 사람들은 B-트리와 레드-블랙 트리에 매우 익숙하다고 생각합니다. 또는 Erlang은 일반화된 균형 트리를 사용하는데, 이는 흥미롭다고 생각합니다. 그리고 밸런싱과 다른 것들을 위해 무작위화 기법을 사용하는 트리도 있습니다. 이것들은 다릅니다. 특히, 이 트리는 i가 붙은 트리이기 때문에 다른데, 어떤 사람들은 이 트리를 튀김과 운율이 맞는 트리라고 부르기도 합니다. 시도 [플리와 운율].
그 뒤에 숨은 아이디어는 잎으로 내려가는 경로가 고정되어 있지 않다는 것입니다. 고유한 잎 위치를 생성하는 데 필요한 만큼의 경로만 사용하게 됩니다. 일반적으로 문자열 검색에서 이러한 것을 보거나 인터넷 라우팅 테이블과 같은 것에서도 사용되는 것 같습니다.
여기서 모델은 매우 간단합니다. 적어도 저는 클로저에서 해시 테이블에 해당하는 것을 원했습니다. 해시 테이블에 상응하는 기능이 없다면 자바 프로그래머에게 클로저를 판매할 수 없다는 것을 알고 있습니다. 그들은 레드-블랙 트리에 대해 듣고 싶어하지 않습니다. 그들은 그것이 괜찮다는 것을 알고 있지만 그들이 익숙한 해시 테이블만큼 좋지는 않습니다. 그들은 그것보다 더 빠른 것이 필요합니다. 그리고 이것들이 있습니다.
작동 방식은 컬렉션에 넣으려는 값을 해시하는 것입니다. 결국 32비트 해시를 얻게 됩니다. 이 해시의 처음 5비트를 사용해 첫 번째 계층에서 고유한 위치가 있는지 확인합니다. 따라서 실제로는 이 시도에서 32방향 분기가 진행되고 있는 것입니다. 또한 각 노드에서 약간의 멋진 비트 트위들링이 진행되어 노드가 희박해집니다. 노드가 완전히 채워지지 않으므로 완전히 채워지지 않은 노드의 공간을 낭비하지 않습니다.
결국 인구, 비트 팝, 그리고 "해커의 기쁨"에서 복사한 몇 가지 알고리즘을 조합하여 사용하게 됩니다. 그것을 구입하세요. 아니면 그냥 Clojure를 사용할 수도 있습니다. 사실, 같은 종류의 기술인 Clojure의 벡터는 이미 팩터와 스칼라에 포팅되어 있어서 저는 괜찮습니다.
따라서 처음 5비트에서 고유하다면 끝입니다. 우리는 그것을 트라이의 첫 번째 레벨에 넣습니다. 그렇지 않다면 다음 5비트를 살펴보고 고유한 위치를 찾을 때까지 한 단계 더 내려가서 트라이를 진행하면 끝입니다. 우리는 거기에 가치를 넣을 것입니다.
여기서 중요한 것은 이 트라이가 얼마나 깊어질 수 있는가 하는 것입니다. 이 트리가 루트이므로 40억 개가 있다면 하나 둘 셋 넷 다섯 여섯으로 내려가면 됩니다. 따라서 매우 빠르게 분기되고 깊이 3에서 백만 개의 항목을 얻을 수 있습니다. 매우 얕습니다. 따라서 매우 얕고 중간 레벨의 인구 밀도가 낮은 노드를 통과하기 위해 약간의 트위들링을 사용하면 정말 빠릅니다. 이제 어떻게 하면 효율적으로 변경된 버전을 만들 수 있을지에 대한 이야기만 남았습니다.
The secret to all persistent data structures is that they are tries.
There you go. Now you know. There are lots of different recipes and
I think people are very familiar with B-trees and red-black trees, or
maybe you know, Erlang uses some generalized balanced trees, I think,
which are interesting. And there are trees that use randomization
techniques for balancing and other things. These are different. In
particular, they are different because they are tries with the i,
some people call them tries [rhymes with fries]. Tries [rhymes with
flees].
The idea behind that is that are not going to have a fixed path down to a leaf. You are going to use only as much of a path as you need to produce a unique leaf position. You usually see these things in string search things, or maybe I think they are also used in Internet routing tables and stuff like that.
Here the model is very simple. We want -- at least I wanted for Clojure -- something equivalent to a hash table. I know I cannot sell Clojure to Java programmers if it does not have something equivalent to a hash table. They do not want to hear about a red-black tree. They known that it is OK, but it is not as good as the hash tables they are used to. They need something faster than that. And these are.
The way they work is that you hash the value you want to put into the collection. You end up with a 32 bit hash. You are going to use the first 5 bits of that hash to see if there is a unique position in the first layer of your trie. So effectively what is happening is you have a 32-way branching going on in this trie. In addition, there is some fancy bit twiddling going on in each node so that those nodes are sparse. They are not fully populated, so you are not wasting the space of not fully populated nodes.
You end up using a combination of population, bit pop, and some algorithms you copy out of "Hacker's Delight". Buy that. Or you can just use Clojure's. In fact, Clojure's vectors, which is the same kind of technology, has been ported to Factor and Scala already, which is fine by me.
So if it is unique in the first 5 bits we are done. We put it in the first level of the trie. If it is not, we are going to look at the next 5 bits and walk down one more level to the trie, until we find some unique position, and then we are done. We are going to put the value there.
The key thing about this is: how deep can this trie get? So this one is the root so, down one two three four five six if you had, whatever, 4 billion things. So it branches extremely fast, and you can get a million items in depth three. It is very very shallow. So the combination of it being very shallow, and using this bit twiddling to walk through the sparsely populated nodes in the intermediate levels, makes it really fast. So that is the representation, now we only need to talk about: how do we make a changed version efficiently?
[Time 0:30:06]
# Structural Sharing

그리고 이 모든 것의 핵심은 구조적 공유입니다. 모든 함수형 데이터 구조는 기본적으로 재귀적으로 정의되며 구조적으로 재귀적으로 정의됩니다. 즉, 방금 만든 버전과 상당한 구조를 공유하는 새 버전을 만들 수 있습니다. 이것이 바로 효율적인 복사본 생성의 핵심입니다. 모든 것을 복사하는 것이 아닙니다. 아주 조금만 복사하는 것입니다. 얼마나 적은 양을 사용하는지 잠시 후에 그림으로 보여드리겠습니다.
모든 것이 불변하기 때문에 구조를 공유하는 것은 문제가 되지 않습니다. 공유하는 구조에 대해 아무것도 변경되지 않으므로 다중 스레드 사용에 안전합니다. 반복 작업에도 안전합니다. 말도 안 되는 반복을 하는 동안에는 변이가 일어나지 않습니다.
And the key there, as is true for all of these things, is structural sharing. All functional data structures are essentially recursively defined, structurally recursively defined. Which means that you can make a new version that shares substantial structure with the version you just had. And that is the key to making efficient copies. You are not copying everything. You are copying a very little bit. I will show you in a picture in a second how little a bit you use.
Since everything is immutable, sharing structure is no problem. Nothing is going to change about the structure that you are sharing, which means it is safe for multi-threaded use. It is safe for iteration. You get none of this mutated while iterating nonsense.
[Time 0:30:48]
# Path Copying
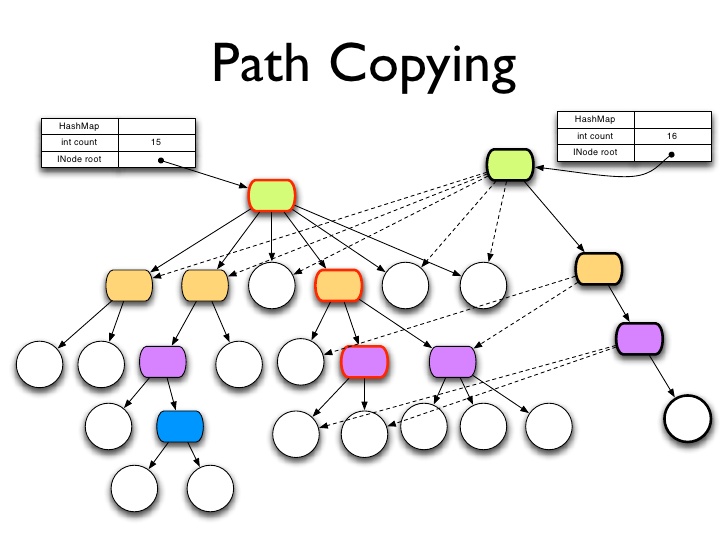
그렇다면 구조를 어떻게 공유할까요? 경로 복사라는 기술을 사용합니다. 다시 말하지만, 이것은 모든 트라이 데이터 구조에 적용됩니다. 모두 똑같은 방식으로 작동하는데, 여기서 오른쪽 경로를 무시하면 이전에 보여드린 트라이가 됩니다. 잎이 15개 있습니다. 하단의 빨간색 윤곽선이 있는 보라색 친구 아래에 하나를 추가하고 싶습니다. 새 노드를 추가하고 싶습니다. 16번째 노드를 추가합니다.
새 자식을 추가할 것이므로 당연히 해당 노드의 복사본을 만들어야 합니다. 부모 노드의 복사본입니다. 그리고 마지막으로 루트입니다. 이 복사본에는 자식이 하나 더 추가되고 이전 버전의 나머지 구조는 공유됩니다.
그래서 3개 레벨에 백만 개의 항목을 저장할 수 있다고 했죠? 32 곱하기 32 곱하기 32, 제가 맞았나요? 아니요, 32,000개입니다. 엄청 많죠.
[청중 웃음]
음, 3 레벨 아래로. 루트까지 포함하면 4단계입니다. 이 마지막 레벨이 아무리 채워져 있어도 여기에 새 노드를 만들면 4개의 항목만 복사할 수 있습니다.
그 오래된 나무는 어때요? 여전히 괜찮아 보입니다. 건드리지 않았어요. 그리고 이것이 새 트리를 만들기 위해 복사해야 하는 경로이며, 이 추가 항목이 있는 새 트리처럼 보입니다. 이 루트를 더 이상 참조하지 않으면 더 이상 참조하지 않는 항목과 마찬가지로 가비지 컬렉션에 포함됩니다.
아주 기본적인 방법이지만, 많은 사람들이 이런 일이 가능하다는 사실을 잘 모르기 때문에 보여드리고 싶었습니다. 이런 종류의 데이터 구조는 특별한 이유가 없는 한 항상 사용해야 한다고 생각합니다. 이것이 바로 클로저가 이런 방식으로 작동하는 이유입니다. 모든 데이터 구조는 기본적으로 이렇게 작동합니다. 다른 것을 선택하려면 엄청난 노력을 기울여야 합니다.
So how do we share structure? We use a technology called path copying. Again, this is true for all trie data structures. They all work exactly the same way, which is: if we ignore the right hand path here, that is the trie I showed you before. It has 15 leaves. We want to add one under that red outlined purple guy at the bottom. We want to add a new node. Add a 16th guy.
So what needs to happen is: we need to make a copy of that node, obviously, because we are going to be giving him a new child. A copy of his parent. And finally, the root. This copy gets one additional child, and the rest of the structure of the old version was shared.
So I said 3 levels could hold a million items, right? 32 times 32 times 32, did I get that right? No, that is 32,000. A lot.
[Audience laughter]
Well, 3 levels down. If you count the root, it is 4 levels. However populated this last level was, making a new node here is only ever going to copy 4 items.
How is that old tree? Looking good, still fine. We did not touch it. And this is the path we need to copy to make the new one, which looks like a new tree with this extra item. If we are no longer referring to that root, it will get garbage collected, as will the things it was referring to that are no longer referenced.
So it is kind of basic, but I want to show it because a lot of people just are not aware that this is a possible thing. This is the kind of data structure I think you should be using all the time unless you have some emergency reason. And that is why Clojure works this way. All of the data structure work like this, by default. You have to go through extraordinary efforts to pick something else.
[Time 0:32:40]
# Coordination Methods

이것이 바로 복합 객체를 값으로 효율적으로 표현하는 방법입니다. 문제의 한 부분을 해결했습니다. 이제 조정 방법에 대해 이야기해야 합니다.
기존의 방식은 사실 방법이 아닙니다. 기존의 방식은 바로 여러분의 문제입니다. 스칼라 강연에서 변수가 있었는데, 휘발성 시맨틱을 가지고 있지는 않았지만 Java의 액터 라이브러리가 해당 변수의 내용이 다른 스레드에서 유효한지 확인하기 위해 메모리 펜스 효과를 발생시키는 동기화 작업을 수행하는 경우가 발생했습니다. 여러분의 프로그램에서는 이것이 걱정거리가 될 것입니다. 액터 라이브러리가 액터에서 변수를 처리하는 것은 좋은 일입니다. 하지만 그렇지 않은 프로그램의 변수는 여러분의 문제입니다.
일반적으로 복합 객체를 만들려면 잠금을 사용해야 합니다. 그리고 락의 문제점은 누구나 알고 있을 겁니다. 잠금의 문제점을 다들 아시나요? 자물쇠의 고통은 다들 아시나요? 자물쇠는 ... 전문가들은 자물쇠와 함께 작동하는 프로그램을 만들 수 있지만 대부분의 사람들은 그렇게 할 시간이나 에너지가 없으며 유지 관리가 정말 정말 어렵습니다. 매우 어렵습니다.
그래서 클로저에서 우리가 하려는 것은 그냥 약간의 간접성을 추가하는 것입니다. 메모리, 즉 변수를 직접 참조하는 대신 간접 지시를 사용할 것입니다. 그런 다음 이러한 참조에 동시성 의미를 추가할 것입니다. 어제 강연을 들으셨다면 이미 말씀드렸지만, 오늘은 좀 더 자세한 내용을 보여드리겠습니다.
So that is the way to efficiently represent composite objects as values. We got one part of the problem solved. Now we need to talk about coordination methods.
The conventional way is not really a method. The conventional way is: it is your problem. We saw in the Scala talk, there was a var. It did not have volatile semantics, but it happened to be the case that the actors library in Java conducts some synchronization thing which causes a happens-before, happens-after memory fence effect, in order to make sure the contents of that var was valid in another thread. In your own program, that is going to be your worry. It is nice that the actors library takes care of vars in actors. But vars in your program otherwise are your problem.
And typically if we are trying to do composite objects we have to use locks. And everybody knows the problems with locks, I think. Everybody know the problem with locks? Everybody know the pain of locks? Locks are ... Experts can build programs that work with locks, but most people do not have the time or energy to do that well, and maintaining it is really really difficult. It is extremely difficult.
So in Clojure what we are going to just do is just add a level of indirection. Instead of directly referring memory, those variables, we are going to use indirection. And then we are going to add concurrency semantics to these references. If you watched me talk yesterday I said that, but I will show you some more details today.
[Time 0:34:05]
# Typical OO - Direct references to Mutable Objects
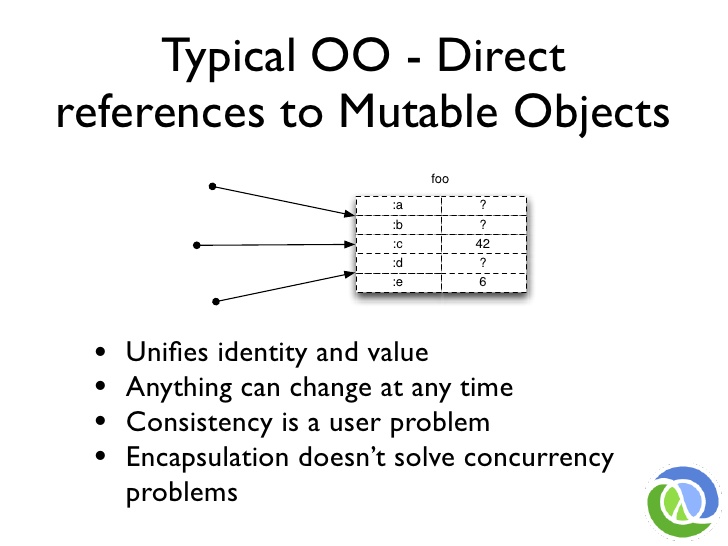
이것이 바로 많은 객체 지향 언어의 현재 세계 상태입니다. 동일한 메모리 덩어리에 대한 참조가 많이 있습니다. 기본적으로 모두에게 무료입니다. 그들은 일관된 객체를 볼 수 있고, 모든 부분이 서로 연관되어 있으며, 어떻게든 세상을 멈추지 않는 한 아무도 아무것도 만지작거리지 않는다는 것을 모릅니다.
하지만 이제 용어가 생겼으니 핵심 문제는 정체성과 가치를 통합하는 것이죠? 이 정체성에 대한 가치를 저장할 수 있는 유일한 장소는 동일한 메모리 조각뿐입니다. 이것이 문제입니다. 방금 새로운 가치를 만드는 방법을 살펴봤습니다. 훌륭하죠. 그럼 이제 어떻게 해야 할까요? 새로운 값을 표현할 새로운 메모리를 만들어야 합니다. 모든 값이 같은 메모리 공간에 저장되어야 한다고 하면 결코 좋은 결과를 얻을 수 없습니다. 여기에는 많은 문제가 있습니다.
So this, quickly, is the picture of the current state of the world in a lot of object-oriented languages. You have a lot of references to the same chunk of memory. Basically it is a free for all. They do not know they are going to see a consistent object, that all the parts are related to each other, that no one is twiddling with anything, unless they can somehow stop the world.
But the core problem here now that we have lingo for it is: this unifies identity and value, right? The only place to put this value for this identity is in the same piece of memory. That is a problem. We just looked at how to do new values. It is great. So what do we need to do? We need to create some new memory to represent that new value. If we say all values of foo have to end up in the same chunk of memory space, we can never do a good job. So that has a lot of problems.
[Time 0:34:53]
# Clojure - Indirect references to Immutable Objects
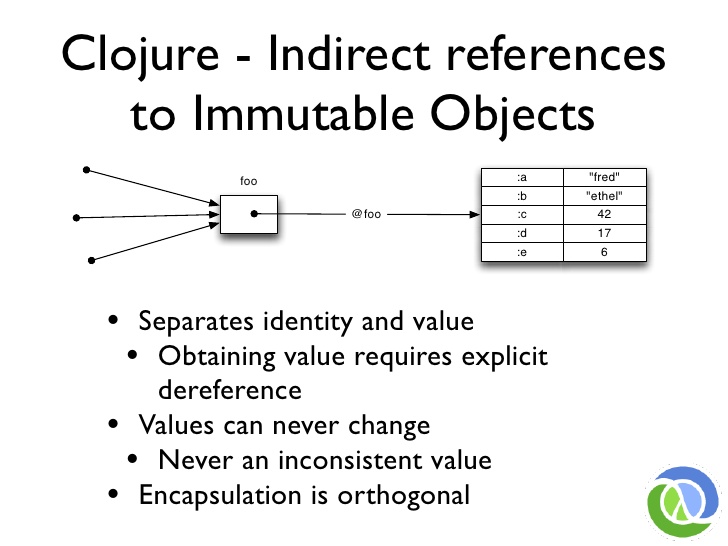
이 문제를 어떻게 해결할 수 있을까요? 그냥 방향성을 사용하면 됩니다. 모든 컴퓨터 과학 문제에 대한 해결책이죠? 한 단계의 방향 전환으로 이제 옵션이 생겼습니다. 이 사람은 이제 불변이 될 수 있기 때문입니다. 이제 불변인 값과 이 작은 상자로 모델링할 아이덴티티를 분리했습니다.
값은 절대 변하지 않습니다. 아이덴티티의 현재 상태를 보려면 참조를 해제해야 합니다. "현재 상태를 알려주세요"라고 말해야 합니다. 그렇게 해서 얻을 수 있는 것은 변하지 않는 값입니다. 주자가 파울을 했는지 확인하기 위해 하루 종일 사진을 들여다보는 것과 마찬가지로 하루 종일 사진을 들여다볼 수 있습니다.
객체 지향 프로그래밍 언어의 캡슐화 기술이 이 문제에 대한 해결책이라고 생각한다면 그렇지 않다는 점을 강조하고 싶습니다. 객체 내부에 변수나 필드가 있고 해당 필드를 변경할 수 있는 메서드를 세 개 작성하고 사람들이 서로 다른 스레드에서 해당 메서드를 호출할 수 있다면 동시성 관점에서 아무것도 캡슐화하지 않은 것입니다. 문제를 분산시키고 무언가 뒤에 숨긴 것입니다.
How do you solve this? You just use indirection. It is the solution to all computer science problems, right? One level of indirection, and now we have options. Because this guy now can be immutable. We have separated the value, which is now immutable, and the identity, which we are going to model with these little boxes.
Values never change. If you want to see the current state of an identity, you have to dereference it. You have to say "give me your state". What you get out of that is a value that cannot change. You can spend all day looking at it, just like you can spend all day looking at the photo to try to see if the runner was fouled.
I want to emphasize, if you think your object oriented programming language's encapsulation techniques are a solution to this problem, that is not true. If you have a variable or a field inside your object and you write three methods that can change that field, and people can call those methods from different threads, you have not encapsulated anything from a concurrency standpoint. You have just spread the problem and hid it behind something.
[Time 0:35:57]
# Clojure references

그래서 저는 이 상자들을 참조라고 부르겠습니다. 과부하가 걸린 용어가 너무 많습니다. 새로운 단어가 떠오르지 않습니다. 다른 것을 참조하기 때문에 참조입니다. 따라서 아이덴티티는 그 값을 참조하는 참조입니다.
하지만 중요한 것은 클로저에서는 자바로 넘어가서 자바를 사용하지 않는 한 이것들만 변형할 수 있다는 것입니다. 물론 클래스와 배열 등은 여전히 존재합니다. 하지만 클로저 모델을 따르고 싶다면 이러한 참조가 필요합니다. 이것들만 변경할 수 있습니다. 그리고 그들이 하는 일은 단지 시간을 관리하는 것입니다. 즉, 불변인 한 값에서 불변인 다른 값으로 원자적으로 이동할 수 있으며, 각 참조 유형은 시간에 대해 서로 다른 의미를 제공합니다.
그렇다면 이러한 의미론의 특징은 무엇일까요? 그 중 하나는 "내가 변경한 내용을 다른 사람들이 볼 수 있는가? 공유되는가?"입니다. 한 우주의 타임라인에는 나쁜 커크가 있고 다른 우주의 타임라인에는 좋은 커크가 있는데, 이 둘은 절대 만나지 않는 스타트렉 대체 우주 모델이 시간을 관리하는 한 가지 방법이 있기 때문입니다. 물론 이 모델의 문제점은 때때로 만나게 된다는 것입니다. 하지만 한 가지 방법은 고립입니다. 그래서 우리는 마지막 모델이 격리임을 알게 될 것입니다. 그러나 일반적으로 이러한 모델의 대부분은 프로그램의 다른 부분이 볼 수 있는 변경 사항을 만드는 것과 관련된 것이므로 공유를 사용합니다.
두 번째 부분은 동시성이며, 여기서는 지금이라는 의미의 동시성을 의미합니다. 지금이 호출자에게 무엇을 의미하는지. 다시 말해, 자기 관계적 관점에서 내가 요청하는 변화가 지금 일어날 것인가, 아니면 다른 시점에 나와 관련되어 일어날 것인가? 독립적인가? 그리고 우리는 이러한 차이를 동기적이라고 부를 것입니다. 만약 그것이 나와 관련하여 지금 일어난다면 그것은 동기적입니다. 나에 대해 지금 일어나지 않는다면 비동기적입니다. 미래의 어느 시점에 발생합니다. 정확히 언제라고 말할 수는 없습니다.
So I am going to call those boxes references. We have too many overloaded terms. I cannot think of any new words. It is a reference because it refers to something else. So identities are references that refer to their values.
But the critical thing is: in Clojure these are the only things that you can mutate, unless you drop to Java and use Java stuff. Of course there are still classes and arrays and all that. But if you want to follow the Clojure model, you are going to have these references. They are the only things that can change. And what they do is just manage time. In other words, you can atomically move from one value which is immutable, to another value which is immutable, and each of the reference type provides different semantics for time.
So what are the characteristics of these semantics? One of them is: "Can other people see these changes I am making? Is it shared?" Because there is one way to manage time, which is the Star Trek alternate universe model, where there is a bad Kirk in one universe timeline, and a good Kirk in another, and they will never meet. Of course the problem with that is that occasionally they do meet. But one way is isolation. So we will see the last model is isolation. But in general most of these models are around making changes that other parts of your program can see, so sharing.
The second part is synchronicity, and here we mean synchronicity in the sense of now. What now means to the caller. In other words, from a self-relative standpoint, is the change I am asking for going to happen now, or at some other time, relative to me? Is it independent? And we are going to call those differences synchronous. If it happens now relative to me it is synchronous. If it does not happen now relative to me it is asynchronous. It just happens at some point in the future. We cannot say exactly when.
[Time 0:37:50]
그리고 다시 한 번 다양한 선택과 옵션이 제공되는 이러한 참조의 마지막 특징은 변경이 조정되었는지 여부입니다. 저는 독립적인 주자가 되어 혼자서 달릴 수 있고 완전히 괜찮습니다. 하지만 한 컬렉션에서 다른 컬렉션으로 무언가를 옮겨야 하는 경우가 많습니다. 두 컬렉션 모두에 있는 것은 절대 원하지 않으실 겁니다. 두 컬렉션 모두에 있는 것도 원치 않겠죠. 그러려면 조율이 필요합니다. 독립적인 자율 기관으로는 불가능합니다. 조율이 필요합니다.
그리고 결국 로컬의 경우 조정을 할 수 있습니다. 이런 식으로 조정을 분배하는 것은 아마도 바보 같은 심부름이지만 사람들은 계속 시도합니다. 저는 일관성 있는 분산 조정이 이루어질 것이라고 생각하지 않지만, 사람들은 이미 일관성을 기꺼이 늦추면 조정을 할 수 있다는 사실을 인식하고 있습니다. 하지만 로컬 모델에서는 조율된 변화를 얻는 것이 완벽하게 가능합니다.
그렇지 않으면 변화는 자율적입니다. 나 혼자서 변화합니다. 나는 당신이 무엇을 하든 상관하지 않으며, 우리 둘이 함께 무언가를 할 수 없습니다.
이제 우리는이 세 가지 특성을 가지고 있습니다. 클로저에는 이 3가지 영역에서 서로 다른 선택을 하는 4가지 유형의 레퍼런스가 있습니다. 참조는 공유되고, 사람들은 변경 사항을 볼 수 있으며, 동기화되고, 지금 바로 변경됩니다. 트랜잭션에서 변경되므로 동일한 트랜잭션에서 둘 이상의 참조를 변경할 수 있으며 이러한 변경 사항이 조정됩니다. 가장 어려운 문제는 바로 이 조정된 변경 문제입니다.
에이전트는 자율적입니다. 에이전트는 마치 배우 모델에서 배우처럼 느껴질 것입니다. 공유되고 사람들이 볼 수 있습니다. 비동기식이기 때문에 변경을 요청하면 미래의 어느 시점에 변경이 이루어질 것이지만 즉시 다시 돌아올 수 있습니다. 그리고 자율적입니다. 에이전트의 활동을 조정하지 않습니다.
And the final characteristic of these references, where again you get different choices and options, is whether or not the change is coordinated. I can be an independent runner and run all by myself, and I am completely fine. But a lot of times you need to move something from one collection to another collection. You do not ever want it to be in both. You do not ever want it to be in neither. That requires coordination. That is impossible to do with independent autonomous entities. You need coordination.
And it ends up that in the local case you can do coordination. Distributing coordination like this is a fool's errand probably, but people keep trying. I do not think that there is ever going to be distributed coherent coordinated change, but people are already recognizing the fact that if you are willing to delay consistency, you can sort of have coordination. But in the local model, it is perfectly possible to get coordinated change.
Otherwise, change is autonomous. I change by myself. I do not care what you are doing, and no two of us can do something together.
So now we have these 3 characteristics. Clojure has 4 types of references that make different choices in these 3 areas. Refs are shared, people can see the changes, they are synchronous, they change right now. They change in a transaction, which means that you can change more than one reference in the same transaction and those changes will be coordinated. Sort of the hardest problem is that coordinated change problem.
Agents are autonomous. They will feel a lot more like actors in an actor model. They are shared, people can see them. They are asynchronous, so you ask for a change, it is going to happen at some point in the future, but you are going to immediately return. And they are autonomous. There is no coordinating the activities of agents.
[Time 0:39:42]
원자는 공유됩니다. 사람들은 변화를 볼 수 있습니다. 동기적입니다. 지금 바로 일어나기 때문에 이것이 에이전트와의 차이점입니다. 또한 자율적입니다. 단일 작업 단위에서 두 개 이상의 원자를 변경할 수 없습니다.
마지막으로 클로저에는 변수라는 것이 있습니다. 이는 좋은 커크 나쁜 커크 대체 우주 모델을 사용하여 변경 사항을 분리합니다. 모든 ID에는 모든 스레드에 고유한 값이 있습니다. 다른 스레드에서는 변경 사항을 볼 수 없습니다. 그것에 대해 너무 많이 이야기하지는 않겠지만, 이것은 Lisps에서 파생된 일종의 특수 목적 구조입니다.
Atoms are shared. People can see the changes. They are synchronous. They happen right now, so that is the difference between them and agents. And they are also autonomous. You cannot change more than one atom in a single unit of work.
And finally, Clojure has something called vars. They isolate changes with the good Kirk bad Kirk alternate universe model. For any identity there is a unique value in every thread. You cannot possibly see the changes in different threads. I am not going to talk too much about that, but it is kind of a special purpose construct derived from Lisps.
[Time 0:40:17]
# Uniform state transition model

이러한 참조가 작동하는 방식에서 좋은 점 중 하나는 균일한 상태 전환 모델을 가지고 있다는 점입니다. 이들 모두는 상태를 변경하는, 즉 한 상태에서 다른 상태로 이동하는 서로 다른 함수를 가지고 있습니다. 그리고 서로 다른 의미를 가지고 있기 때문에 서로 다른 이름을 사용합니다. 사람들이 이것이 동기식인지 비동기식인지, 아니면 트랜잭션이 필요한 것인지 혼동하지 않았으면 합니다.
하지만 모델은 항상 동일합니다. 변경 함수 중 하나를 호출할 것입니다. 참조인 상자를 전달하고 "이 함수를 사용해 주세요"라고 말할 것입니다. 따라서 이러한 인수가 포함된 함수를 전달하고 상자의 현재 상태에 적용하고 반환 값을 새 상태로 사용할 수 있습니다. 따라서 함수는 원자 단위로, 트랜잭션 내에서, 어떤 식으로든 몇 가지 제약 조건에 따라 현재 상태를 전달받게 됩니다. 현재 상태가 전달됩니다. 새로운 상태를 계산할 수 있습니다. 여기서도 전달되는 것은 순수한 함수입니다. 그 새로운 상태가 참조의 새로운 값이 됩니다.
클로저의 참조에서는 참조를 역참조하면 항상 참조의 현재 상태를 볼 수 있습니다. 즉, 완전히 자유롭게 할 수 있기 때문에 로컬 가시성이라는 것입니다. 그리고 그렇게 할 수 있기 때문에 훨씬 더 효율적인 프로그램을 만들 수 있습니다. 컬렉션을 보고 싶을 때마다 컬렉션을 볼 수 있는 권한을 요청해야 한다면 로컬 컨텍스트에서는 작동하지 않습니다.
또한 이러한 것들의 다른 공통된 속성 중 하나는 사용자 잠금이 없고, 이 작업을 수행하기 위한 잠금이 없으며, 이러한 구조 중 어느 것도 교착 상태에 빠질 수 없다는 것입니다.
One of the things that is nice about the way these references work is: they have a uniform state transition model. All of them have different functions that change the state, that say: move from one state to another state. And they use different names because they have different semantics. I do not want people to get all confused about: is this happening synchronously or asynchronously, or do I need a transaction?
But the model is always the same. You are going to call one of the changing functions. You are going to pass the reference, the box, and you are going to say, "Please use this function". So you are going to pass a function, maybe with these arguments, apply it to the current state of the box, and use its return value as the new state. So the function will be passed the current state, under some constraints, either atomically, within a transaction, some way. It will be passed the current state. It can calculate a new state. Again it is a pure function you are passing. That new state becomes the new value of the reference.
In Clojure's references, you can always see the current state of a reference by dereferencing it. In other words, that is the local visibility, because it is completely free to do. And it yields much more efficient programs, to be able to do that. If you have to ask for permission to see collections every time you want to see them, it does not work in the local context.
In addition, one of the other shared attributes of these things is that there is no user locking, you do not have any locking to do this work, and none of these constructs can deadlock.
[Time 0:41:45]
# Persistent 'Edit'
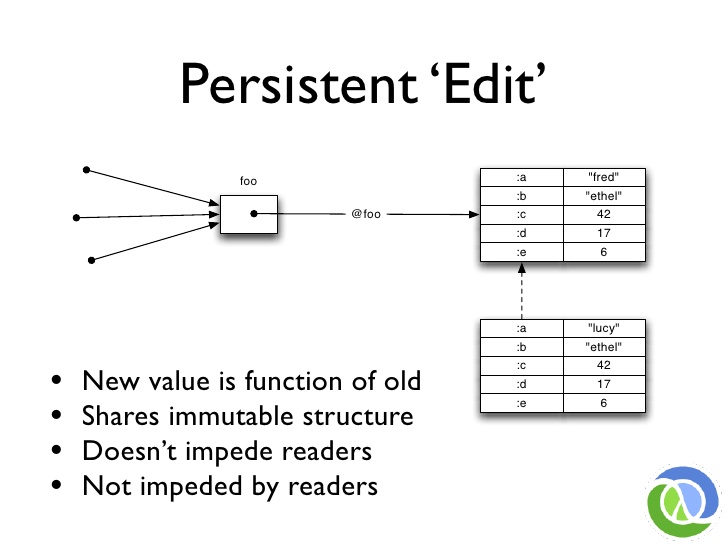
그렇다면 이 새로운 세상에서 무언가를 편집한다는 것은 무엇을 의미할까요? 값에 대한 참조를 갖게 될 것입니다. 우리는 새로운 값을 단품으로 만들 수 있습니다. 함수를 호출하고 새로운 값을 만들어서 새로운 상태인 foo가 되게 할 것입니다.
새 값은 이전 값의 함수입니다. 구조를 공유할 수 있습니다. 방금 보셨죠? 이렇게 해도 foo를 읽는 사람이 방해받지 않습니다. 그들은 완전히 자유롭게 계속 읽을 수 있습니다. 우리가 새로운 버전의 foo를 알아내는 동안 멈출 필요가 없습니다.
또한, 사람들이 읽는 것에 방해가 되지 않습니다. 새 버전을 만들기 위해 사람들이 읽기를 멈출 때까지 기다릴 필요가 없습니다. 이것이 바로 높은 처리량의 동시성을 위해 필요한 것입니다.
So what does it mean to edit something in this new world? You are going to have a reference to a value. We can make a new value a la carte, on the side. We are going to call a function and create this new value, which we intend to become the new state of foo.
The new values are a function of the old. They can share structure. We just saw that. Doing this does not impede anybody who is reading foo. They are completely free to keep reading. They do not have to stop while we figure out the new version of foo.
In addition, it is not impeded by people reading. We do not have to wait for people to stop reading so we can start making a new version. This is the kind of thing you are going to need for high-throughput concurrency.
[Time 0:42:25]
# Atomic State Transition
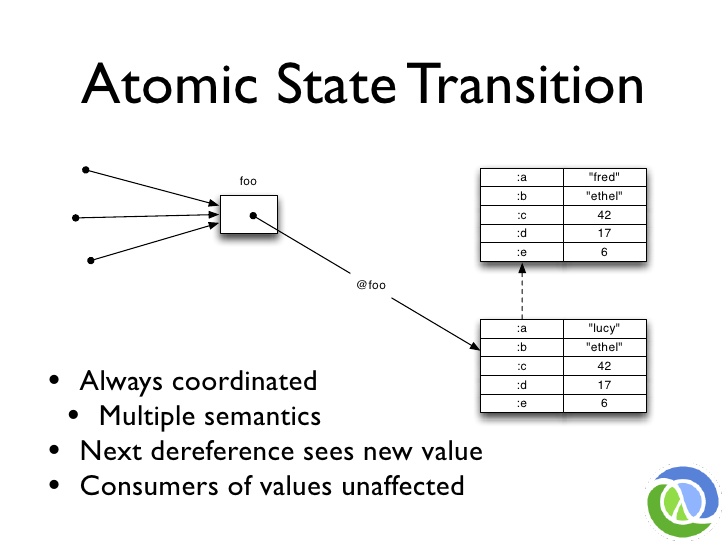
그리고 새로운 상태로 이동하는 것은 이 상자를 원자 단위로 바꿔서 새로운 불변의 값을 확인하는 것입니다. 이는 항상 조율됩니다. 이런 일이 일어나는 방식에는 항상 규칙이 있습니다. 방금 여러 의미론을 보여드렸습니다. 이 일이 발생한 후 누군가가 이 상자를 다시 참조할 때마다 새로운 값을 보게 됩니다.
소비자는 영향을 받지 않습니다. 이전 가치를 보고 있었다면 이런 일이 발생해도 방해받지 않습니다. 저는 그저 오래된 가치를 보고 있을 뿐입니다. 마치 달리기 선수의 사진을 보고 있는 것과 같습니다. 레이스가 끝났다는 것을 압니다. 괜찮습니다. 우리는 그렇게 행동해야 합니다.
저처럼 오랫동안 프로그래밍을 해왔다면 '내가 세상을 소유한다'는 생각에서 벗어나기가 정말 어렵습니다. 그리고 내가 세상을 멈춘다. 내가 가라고 하면 세상은 간다." 그런 생각에서 벗어나야 합니다. 그것이 미래입니다. 우리는 반드시 최신 데이터가 아닌 데이터로 작업하게 될 것이라는 점을 이해해야 합니다. 그것이 바로 우리의 미래입니다.
And then going to a new state is just an atomic swapping of this box to look at the new immutable value. That is always coordinated. There are always rules for how that happens. I just showed you the multiple semantics. Any time somebody dereferences this after -- more time words -- after this happens, they will see the new value.
Consumers are unaffected. If I was looking at the old value, I do not get disturbed by this happening. I am just looking at an old value. It is like I am looking at a picture of the runner to see. I know the race is over. That is OK. We need to behave that way.
If you have been programming for so long as I have, it is really hard to break from, "I own the world. And I stop the world. The world goes when I say go." We have to just break from that. That is the future. We have to understand that we are going to be working with data that is not necessarily the very latest data. That is just the future for us.
[Time 0:43:18]
# Refs and Transactions

자, 제가 말씀드린 것처럼 하드 레퍼런스는 트랜잭션 레퍼런스입니다. 클로저에는 소프트웨어 트랜잭션 메모리 시스템이 있습니다. 저는 이 용어를 사용하는 것이 거의 싫은데, 사람들이 STM을 마치 한 가지인 것처럼 비판하는 것을 좋아하기 때문입니다. 다양한 STM이 존재합니다. 근본적으로 다른 특성을 가지고 있습니다. 클로저는 다른 것과 근본적으로 다릅니다.
하지만 기본적으로 데이터베이스 모델과 매우 흡사한 모델이라는 몇 가지 공통점이 있습니다. 트랜잭션 내에서만 변경할 수 있습니다. 트랜잭션 내에서 전체 참조, 참조 집합에 대한 모든 변경은 함께 일어나거나 전혀 일어나지 않습니다. 이것이 바로 원자성입니다. 트랜잭션을 실행하는 동안에는 다른 트랜잭션의 영향을 볼 수 없습니다. 그들은 여러분의 효과를 보지 못합니다. 이것이 바로 정상입니다.
STM 거래의 한 가지 독특한 점은 투기적이라는 것입니다. 당신은 이기지 못할 수도 있습니다. 다른 사람이 이길 수도 있습니다. 특정 한도까지 자동으로 재시도되므로 거래에 부작용이 포함될 수 없습니다.
OK, so the hard reference, as I said, are the transactional ones. Clojure has a software transactional memory system. I almost hate using this term because people like to criticize STM as if it was one thing. There are a whole bunch of different STMs. They have radically different characteristics. Clojure's is radically different from the other ones.
But they all share some things, which is basically a model that feels a lot like a database model. You can only change them within a transaction. All the changes you make to an entire set of references, refs, inside a transaction, happen together, or none of them happen. That is atomicity. You do not see the effects of any other transactions while you are running. They do not see your effects. It is the normal things.
The one unique thing about STM transactions is that they are speculative. You may not win. Somebody else may win. You will automatically retry up to a certain limit, which means that your transactions cannot contain side effects.
[Time 0:44:15]
# The Clojure STM

이것이 바로 코디를 하는 방식입니다. 이런 기술 없이는 실제로 조정을 할 수 없습니다. 독립된 개체에 시스템을 구축하고 이런 종류의 작업을 할 수는 없습니다.
그렇다면 실제로는 어떻게 할까요? 코드를 도싱크로 감싸면 되는데, 이는 트랜잭션이라는 의미일 뿐입니다. 제가 설명한 대로 작동하는 두 가지 함수인 alter와 commute가 있습니다. 이 두 함수는 참조와 함수, 인수를 받아 "트랜잭션의 참조에 이 값을 적용하고 반환값을 새 상태로 만듭니다."라고 말합니다.
내부적으로 Clojure는 다중 버전 동시성 제어(MVCC)를 사용하는데, 이는 실제 세계에서 작동하는 방식으로 STM을 수행하는 데 매우 중요한 구성 요소라고 생각합니다. 많은 STM 설계는 객체 지향 언어를 사용하여 필드를 두드리는 끔찍한 방식으로 앱을 작성하면 STM이 마술처럼 개선해줄 것이라고 생각합니다.
저는 전혀 그렇게 생각하지 않습니다. 클로저의 STM은 그런 종류의 작업을 위해 설계되지 않았습니다. 객체의 모든 부분을 참조로 만들면 작동하지 않을 것이며 방금 방법을 설명했기 때문에 기분이 나쁘지 않을 것입니다. 객체를 값으로 만들고 그 값을 원자 단위로 바꾸면 모든 것이 더 좋아집니다.
하지만 대부분의 STM이 "읽기 추적"이라는 작업을 수행하기 때문에 사람들은 STM을 보편적으로 비판할 수 있습니다. 트랜잭션이 진행되는 동안 나쁜 일이 일어나지 않도록 하기 위해 모든 쓰기뿐만 아니라 모든 읽기까지 추적합니다. 저는 또한 그것이 작동하지 않을 것이라고 믿습니다. 그래서 클로저는 읽기 추적을 하지 않습니다.
이를 달성하는 방법은 다중 버전 동시성 제어라는 기술을 사용하는 것인데, 이는 Oracle과 PostgreSQL이 데이터베이스로 작동하는 방식으로, 기본적으로 이전 값을 유지하여 트랜잭션에 대한 스냅샷을 제공하는 동시에 쓰기 중인 다른 트랜잭션은 계속 진행할 수 있습니다. 이는 결국 매우 효과적입니다.
하지만 값에 대한 참조를 사용해야 할 필요성이 없어집니다. 여러분을 위해 오래된 값을 보관하는 것은 비용이 많이 들어야 합니다. 방금 영구 데이터 구조를 사용하는 경우 비용이 얼마나 저렴한지 보여드렸습니다. 이 모든 것이 함께 진행됩니다. 이 모든 것을 함께하지 않으면 제 생각에는이 문제에 대한 답이 없습니다. 하지만 이렇게 하면 정말 좋습니다. 따라서 MVCC STM은 읽기 추적을 수행하지 않습니다.
This is the way you do coordination. You cannot really do coordination without some technique like this. You cannot build a system on independent entities and do this kind of work.
So in practice what do you do? You just wrap your code with dosync,
which just means this is a transaction. There are two functions alter
and commute, which work like I described. They take a reference and a
function and some args and say, "apply this to the reference in the
transaction and make the return value the new state."
Internally Clojure uses multiversion concurrency control (MVCC) which I also think is a very critical component to doing STM in a way that is going to work in the real world. A lot of STM designs are: you just write your app in the terrible way you were, with your object oriented language, banging on fields, and STM is magically going to make that better.
I do not believe in that at all. Clojure's STM is not designed for that kind of work. If you make every part of your object a ref, it is not going to work and I am not going to feel bad for you, because I just explained how to do it. You make your object the value and atomically switch that value, and everything is better.
But you do have this issue of, again, people would criticize STMs universally, because most STMs do something called "read tracking". In order to make sure that nothing bad happened while your transaction was going on, they track every read that you do, in addition to all the writes that you do. I also believe that that is not going to work. So Clojure does no read tracking.
The way it accomplishes that is with a technique called Multiversion Concurrency Control, which is the way Oracle and PostgreSQL work as databases, where essentially old values can be kept around in order to provide a snapshot of the world for transactions, while other transactions that are writing can continue. That ends up being extremely effective.
But it falls out of this necessity to be using references to values. It has got to be cheap for me to keep an old value around for you. I just showed you how it is cheap, if you are using persistent data structures. All these things go together. If you do not do all of this stuff together, you do not have an answer to this problem, in my opinion. But when you do this, it is really nice. So MVCC STM does not do read tracking.
[Time 0:46:24]
# Refs in action

그렇다면 실제로는 어떤 모습일까요? 우리는 foo를 참조로 정의합니다. 이는 해당 맵에 대한 트랜잭션 상자입니다. foo를 역참조하면 그 안에 무엇이 있는지 확인할 수 있습니다. 안타깝게도 해시 맵이기 때문에 이름 순서가 변경되므로 반복 순서를 보장하지 않습니다.
이제 foo 내부의 값을 조작할 수 있습니다. "foo 안에 있는 맵을 주고, a 키를 lucy와 연결해줘"라고 말할 수 있습니다. 그러면 새로운 값이 반환됩니다. 그 어떤 것도 참조에 영향을 미치지 않습니다. 값을 제거했습니다. 다른 값을 만들었습니다. 트랜잭션 시스템 외부에서 모든 종류의 계산을 완전히 수행할 수 있습니다. 여전히 함수형 프로그래밍 언어입니다. 값을 꺼내서 함수형 프로그램을 작성하면 됩니다. 그래서 그것은 foo에 아무런 영향을 미치지 않았습니다.
참조를 취하고, 참조를 함수 어소시에이션으로 통근하고, 맵에 값을 추가하고, 키 a와 값 루시를 추가하는 커뮤트 함수를 사용할 수 있습니다. 트랜잭션 내부의 참조에 대해서만 이 작업을 수행할 수 있다는 참조에 대한 의미가 있기 때문에 실패합니다. 그래서 오류가 발생합니다.
그러나 동일한 작업을 트랜잭션 내부에 넣으면 성공합니다. 그리고 트랜잭션이 완료되면 이것이 바로 foo의 값입니다.
So what does it looks like in practice? We define foo to be a ref. That is a transactional box to that map. We can dereference foo, and we see what is in there. Unfortunately the name order changes because they are hash maps, so they do not guarantee any order of iteration.
We can go and manipulate the value inside foo. We can say, "give me
the map that is inside foo, and associate the a key with lucy".
That returns a new value. Nothing about that impacted the reference.
I took the value out. I made another value. We can do all kinds of
calculations completely outside of the transactional system. It is
still a functional programming language. Get the value out and write
functional programs. So that did not have any effect on foo.
We can go and we can use that commute function, which actually says:
take a reference, commute a reference with a function assoc, which
adds a value to a map, the key a and the value lucy. And that
fails, because there is a semantics to those refs which is that you
can only do this for refs inside a transaction. So you get an error.
If however you put that same work inside a transaction, it succeeds. And when the transaction is complete, that is the value of foo.
[Time 0:47:40]
# Implementation - STM

구현 세부 사항에 대해 이야기 할 시간이 많지 않습니다. 하지만 다시 한 번 말씀드리지만, STM이 한 가지라고 생각하지 마세요. STM에 대한 논문을 하나만 읽었다면 STM에 대해 아무것도 모르는 것입니다. STM에 관한 모든 논문을 읽었다면 STM에 대해 아무것도 모르는 것이 아니라 조금 아는 것입니다. 우리 중 누구도 STM에 대해 아무것도 모릅니다. 이것은 여전히 연구 주제입니다.
하지만 제가 아는 것은 이것이 작동하고 정말 잘 작동하며 잠금을 사용하지 않는 프로그램을 쉽게 작성할 수 있다는 것입니다. 지금까지 제가 작성한 모든 프로그램에서 조정된 변경이 필요할 때 언제든지 이 방법을 사용할 수 있었을 것이고, 괜찮았을 것이라고 생각합니다. 사람들은 그것을 두드리고 확장성 문제 등을 밀어붙일 수 있습니다. 정확성의 관점에서 보면 이것은 신의 선물입니다.
하지만 내부를 들여다보면 일부 STM과 달리 Clojure의 STM은 낙관적으로 돌아가지 않습니다. 잠금을 사용합니다. 대기 알림을 사용하며 이탈하지 않습니다. 프로세스는 다른 프로세스를 기다립니다. 교착 상태 감지 기능이 있습니다. 나이 기반 바게징이 있습니다. 트랜잭션 시스템에서 공유할 수 있는 최소한의 양은 사실 타임스탬프에 대한 하나의 CAS입니다.
사람들은 80개의 스레드로 하나의 CAS를 계속 망치질할 수 있다는 것을 보여줬는데, 이것이 확장성의 한계에 가깝습니다. 그러나 실제로 트랜잭션에 약간의 작업이 있을 때는 문제가 되지 않습니다. 저는 600개의 코어를 가진 Azul 박스에서 작업을 실행해봤는데, 그 CAS는 문제가 되지 않았습니다.
제가 말했듯이 읽기 추적은 없습니다. 이 STM은 거친 방향을 위해 설계된 것이 중요합니다. 기존에 하던 일을 할 수 있는 뱀 오일 STM이 아닙니다. 이 새로운 일을 해야 합니다. 불변 값에 대한 참조를 사용해야만 제 STM을 사용할 수 있습니다. 그렇다고 해서 기존 프로그램이 좋아지지는 않습니다.
독자가 작가에게 방해받지 않고, 그 반대의 경우도 마찬가지입니다. 또한 출퇴근도 지원하는데, 지금은 설명할 시간이 없습니다.
I do not have a lot of time to talk about the implementation details. But again, do not think that STM is one thing. If you have read one paper on STM, you know nothing about STM. If you have read all the papers about STM, you know a little bit more than nothing about STM. None of us knows anything about STM. This is still a research topic.
But I do know this: this works, and it works really well, and it makes it easy to write programs that do not use locks. I think all the programs that I have written in my career, I could have used this any time I needed coordinated change, and it would have been fine. People can bang on it and try to push the scalability issues and whatnot. From a correctness standpoint, this is a godsend.
However, inside, unlike some STMs, Clojure's STM is not spinning optimistic. It does use locks. It uses wait notify, it does not churn. Processes will wait for other processes. It has got deadlock detection. It has got age-based barging. There is extreme minimum -- in fact, I think what is actually the minimum amount -- of sharing in a transactional system, which is one CAS, which is for the timestamps.
People have demonstrated you can hammer on one CAS continuously with 80 threads, and that is about the limit of scalability. But when you actually have some work in your transactions, it is no problem. I have run stuff on an Azul box with 600 cores, and that CAS is not going to be the problem.
As I said there is no read tracking. It is important that this STM is designed for coarse-grained orientation. It is not one of these snake-oil STMs that you can do what you were doing. You have to do this new thing. You have to use references to immutable values, then you can use my STM. It is not going to make your old programs good.
And readers do not then get impeded by writers, and vice versa. It also supports commute, which I do not really have time to explain right now.
[Time 0:49:33]
# Agents

다른 모델을 하나 보여드리고 싶은데, 매우 다르지만 매우 같다는 점에서 좋은 모델입니다. 값에서 변화를 분리했기 때문에 시간에 대해 완전히 다른 접근 방식을 취할 수 있습니다.
따라서 이러한 참조 셀의 또 다른 종류인 에이전트에서 각 에이전트는 완전히 독립적입니다. 각 에이전트는 고유한 상태를 가지며 다른 에이전트와 조정할 수 없습니다. 상태 변경은 액션을 통해 이루어지며, 액션은 본질적으로 보내기 또는 보내기라는 함수를 사용하여 에이전트에게 보내는 일반적인 함수일 뿐입니다. 이 함수는 즉시 반환됩니다. 예를 들어 "미래의 어느 시점에 이 인수를 사용하여 에이전트의 현재 값에 이 함수를 적용하고 함수의 반환 값을 에이전트의 새 상태로 만듭니다."라는 식으로 이 함수와 일부 데이터를 보낼 수 있습니다.
이는 스레드 풀의 스레드에서 비동기적으로 발생합니다. 에이전트당 한 번에 하나의 작업만 수행되므로 에이전트에는 기본적으로 일종의 입력 메일함 대기열이 있습니다. 따라서 에이전트는 모든 작업을 순차적으로 수행합니다. 이것은 에이전트의 의미론에 대한 또 다른 약속입니다.
I do want to show you one other model, because it is very different, And it is nice in that it is very different, yet very much the same. Because we have sort of isolated change from values, you can take a completely different approach to time.
So in an agent, which is another kind of these reference cells, each
agent is completely independent. They have their own state and they
cannot be coordinated with any other. State change is through
actions, which are essentially just ordinary functions that you are
going to send to the agent with a function called send or
send-off. That function is going to return immediately. You are
going to send this function and some data, say, "at some point in the
future, apply this function to the current value of the agent with
these arguments, and make the return value of the function the new
state of the agent."
That happens asynchronously on a thread from a thread-pool. Only one action per agent happens at a time, so agents essentially have sort of an input mailbox queue. So they also do all of their work serially. This is another promise of the semantics of an agent.
[Time 0:50:38]
# Agents

이 함수는 어떻게 사용할 수 있을까요? 지도를 참조하는 에이전트가 되려면 def foo라고 말합니다. 참조를 해제합니다. 지도의 내용을 봅니다. 그 참조를 동일한 함수 associate :a를 루시에게 보냅니다. 저는 바로 그것을 봅니다. 아직 표시되지 않을 수도 있습니다. 어느 정도 시간이 지날 것입니다. 약속할 수는 없습니다. 그리고 나면 달라질 겁니다.
이것은 사물에 대한 다른 사고 방식이지만 Erlang으로 프로그래밍하는 사람들은 이런 방식으로 사물을 생각하면서 놀라운 일을 완전히 해냅니다. 비동기적일 수 있습니다. 마치 컴퓨터가 예전 Apple이고 자신과 자신의 어셈블리 언어만 있고 자신이 우주의 왕인 것처럼 계속 프로그래밍할 수는 없습니다. 이제는 모든 일이 동시에 일어납니다.
Again as with the other reference types, you can just dereference it and see what is in there. If you do successive actions to agents inside the same action, they are held until the action completes, so they can see the new state.
The agents do coordinate with transactions, which is kind of nice. So one of the problems is you saw, "no side effects in transactions". So you are wondering, how do I let somebody know I completed this transaction successfully? Do I need to send them a message, or do something side effect-y? It ends up that if you send an agent action during a transaction, that is held until the transaction commits. So if the transaction gets retried, those messages do not go out until the transaction actually succeeds. So that coordination is a really nice feature. These two things work together.
They are not quite actors. The difference with an actor model is: that is a distributed model. You do not have direct access to the state in an actor model, because you cannot distribute that. Since I am not doing distribution, I can let you access the state directly, which means it is a suitable place to put something that you actually may need to share a lot, without necessarily serializing activity.
[Time 0:51:40]
# Agents in Action

이 함수는 어떻게 사용할 수 있을까요? 지도를 참조하는 에이전트가 되려면 def foo라고 말합니다. 참조를 해제합니다. 지도의 내용을 봅니다. 그 참조를 동일한 함수 associate :a를 루시에게 보냅니다. 저는 바로 그것을 봅니다. 아직 표시되지 않을 수도 있습니다. 어느 정도 시간이 지날 것입니다. 약속할 수는 없습니다. 그리고 나면 달라질 겁니다.
이것은 사물에 대한 다른 사고 방식이지만 Erlang으로 프로그래밍하는 사람들은 이런 방식으로 사물을 생각하면서 놀라운 일을 완전히 해냅니다. 비동기적일 수 있습니다. 마치 컴퓨터가 예전 Apple이고 자신과 자신의 어셈블리 언어만 있고 자신이 우주의 왕인 것처럼 계속 프로그래밍할 수는 없습니다. 이제는 모든 일이 동시에 일어납니다.
So what does this look like to use? I say def foo to be an agent
referring to a map. I dereference it. I see the contents of the map.
I send that reference the same function associate :a with lucy.
I look at it right away. It may not be there yet. Some amount of
time will pass. I cannot promise you what. And then it will be
different.
This is a different way of thinking about things, but people who program in Erlang completely do amazing things with thinking about things this way. Things can be asynchronous. You cannot keep programming your computer as if it was your old Apple and there was only you and your assembly language and you were king of the universe. Things happen at the same time now.
[Time 0:52:27]
# Atoms

원자는 에이전트와 매우 유사한 이야기입니다. 원자는 독립적입니다. 원자에 대한 변경을 조정할 수 없습니다. 상태 변경 함수에는 다른 이름이 있습니다. 스왑이라고 합니다. 다시 말하지만 이전 상태의 일반 함수를 새 상태로 가져옵니다. 변경은 이제 동기적으로 발생하므로 이것이 원자와 에이전트의 차이점입니다. 지금 바로 일어나고 있습니다.
이것이 비교 및 스왑 모델입니다. 비교 및 스왑 또는 비교 및 설정은 비교 및 설정 메모리를 보고 "이 메모리로 바뀌었으면 좋겠어."라고 말할 수 있는 원시적인 방식입니다. 그리고 그것이 여전히 그 상태일 때만 이것으로 바뀝니다. 그래서 당신은 그것을 봅니다. 그것이 그것임을 알 수 있습니다. 당신은 그것을 이것으로 바꾸고 싶습니다. 여전히 저것이라면 내부에서 원자적으로 "좋아, 이렇게 만들겠습니다."라고 말할 것입니다.
CAS 자체의 문제점은 일반적으로 값을 읽고 무언가를 수행한 다음 다시 넣기를 원한다는 것입니다. 따라서 값을 본 시점과 CAS를 수행하려고 할 때 사이에 간격이 생깁니다. 물론 이 작업을 수행한 후 다른 사람이 무언가를 수행했다면 CAS는 실패할 것입니다. 그러면 어떻게 해야 할까요? 일반적으로 CAS가 적절한 데이터 구조인 잘 작성된 CAS에는 약간의 스핀 루프가 있습니다. 여러분은 값을 CAS로 회전시킬 것입니다. 원자가 여러분을 위해 회전을 합니다. 결과적으로 함수는 두 번 이상 호출될 수 있습니다.
다시 말하지만, 트랜잭션과 원자 모두에서 두 번 이상 호출되어야 하기 때문에 부작용이 없는 함수로 프로그래밍해야 하는 세상에 살고 있습니다. 따라서 부작용을 피해야 하지만, 이를 통해 얻을 수 있는 가치는 성공했을 때 함수가 전달된 값에 적용된 함수를 알 수 있고, 입력된 결과에는 해당 원자에서 개입 활동이 발생하지 않았다는 것입니다. 이것이 바로 여러분이 가져야 할 강력한 구조입니다.
Atoms, a very similar story to agents. They are independent. You
cannot coordinate change to atoms. There is a different name for the
state change function. It is called swap. Again it takes an
ordinary function of the old state to the new state. The change
happens synchronously now, so that is the difference between atoms
and agents. It happens right now.
This is a model for compare and swap. Compare and swap, or compare and set, is a primitive that is going to let you look at a piece of compare and set memory and say, "I want it to turn in to this." And it will turn into this only if it is still that. So you look at it. You see it is that. You want to turn it into this. If it is still that, inside atomically it will say, OK I will make it this.
The problem with CAS by itself is: you usually want to read the value, do something with it, and then put it back. So you get this interval between when you looked at it, and when you try to do the CAS. And of course when you do that, and somebody else has done something, that CAS is going to fail. And then what do you do? Typically, a well written CAS thing, where CAS is a suitable data structure, will have a little spin loop. You are going to spin in a value into a CAS. Atoms do the spinning for you. As a result, the function may be called more than once.
Again, we are in this world where you should be programming with these side effect free functions, because they need to be called more than once, both in transactions and in atoms. So you have to avoid side effects, but the value you get out of this is that when you succeed, you know the function you applied was applied to the value the function was passed, and the result that got put in had no intervening activity occur on that atom. That is a powerful construct you need to have.
[Time 0:54:08]
# Atoms in Action

그리고 이것들을 보세요. 다른 지도와 매우 비슷해 보입니다. foo를 해당 지도를 참조하는 원자로 정의합니다. 그것을 참조 해제하면 거기에 있습니다. 교환합니다. 즉시 새로운 값을 얻습니다.
And look at these. It looks a lot like the other ones. Define foo
to be an atom that refers to that map. Dereference it, it is there.
We swap. Immediately we get the new value.
[Time 0:54:22]
# Uniform state transition

이것이 바로 균일한 상태 전환 모델입니다. 이것이 바로 참조의 모습입니다. 트랜잭션을 시작하고, 커밋하거나 변경합니다. 함수와 몇 가지 인수를 전달하는 참조입니다. 함수의 결과가 새로운 값입니다.
에이전트는 완전히 다른 시간 의미를 제외하고는 동일합니다. 일정 시간이 지난 후 스레드 풀에서 비동기적으로 발생합니다. 즉시 반환됩니다.
원자, 지금 바로 발생하지만 다른 원자들과는 독립적입니다.
특히 로컬 모델에서 실제 멀티 스레드 프로그램을 작성하려면 이러한 모든 것이 필요합니다. 이것들은 모두 프로그램의 로컬 부분에서 동시 프로그램을 작성하는 데 필요한 모든 것들이며, 그것들 없이는 할 수 없다고 생각합니다. 그래서 여기에 있지만 균일 한 방법입니다.
So this is the uniform state transition model. That is what refs look like. Start a transaction, commute or alter. Your ref, passing a function and some arguments. The result of the function is your new value.
Agents, same thing, except completely different time semantics. It happens asynchronously in a thread-pool, some time later. You return immediately.
Atoms, happen right now, but are independent from the others.
You need all of these things to write a real multi-threaded program, especially in the local model. These are all things that I have needed to do in my career writing concurrent programs in the local part of the program, and I do not think you can do without them. So here they are, but it is a uniform way to go.
[Time 0:54:57]
# Summary

요약하자면, 함수형 프로그래밍에서 불변 값은 매우 중요합니다. 하지만 결국 상태에도 매우 중요합니다. 불변 값 없이는 시간과 상태를 제대로 관리할 수 없습니다. 시간과 값이라는 두 가지가 변하도록 내버려두면 신뢰할 수 있는 어떤 것도 할 수 없습니다.
영구 데이터 구조를 사용하면 복합 객체를 효율적이고 불변하게 표현할 수 있습니다. 값에 대한 불변성의 제약을 받아들일 수 있다면 이러한 모든 옵션을 사용할 수 있습니다. 저는 의미가 약간 다른 다섯 번째 참조 유형을 작업하고 있습니다. 시간 관리와 가치 관리를 분리했기 때문에 쉽게 할 수 있습니다.
마지막으로, 이것은 사용하기 매우 쉽다고 생각합니다. 다른 모델을 보셨다면, 이것은 작동하는 변수와 매우 유사합니다.
So, in summary, immutable values are critical for functional programming. But it ends up they are also critical for state. We cannot really manage time and state without immutable values. If you you are going to let two things change, time and value, you cannot do anything that is reliable.
Persistent data structures let you represent composite objects efficiently, immutably. Once you are able to accept this constraint of immutability on your values, you have all of these options. I am working on a fifth reference type with slightly different semantics. It is easy to do, because I have separated time management from value management.
Finally, I think this is pretty easy to use. If you have seen some other models, this is a lot like variables that work.
[Time 0:55:51]
# Thanks for listening!

감사합니다!
So, thank you!
[Time 0:55:52]