# 우리는 거기에 있는가? (Are We There Yet?)
- Speaker: Rich Hickey
- Conference: JVM Language Summit 2009 (opens new window) - Sept 2009
- Video: http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hickey (opens new window)

그래서 오늘은 시간에 대해 이야기해 보려고 합니다. 특히 객체 지향 언어에서 일반적으로 시간을 어떻게 대하는지, 그리고 어쩌면 우리가 어떻게 실패하고 있는지에 대해 말입니다. 그래서 저는 오늘 우리가 매일 하는 일에 너무 익숙해져서 한 발짝 물러나서 우리가 정확히 무엇을 하고 있는지 살펴보지 않는다고 생각하는 몇 가지 근본적인 것들을 다시 생각해 보도록 유도하려고 합니다.
So I’m going to talk about time today. In particular, how we treat time in object-oriented languages generally and maybe how we fail to. So I’m trying to provoke you today to just reconsider some fundamental things that I just think we get so entrenched with what we do every day, we fail to step back and look at what exactly are we doing.

그렇다면 우리는 일반적으로 구현된 객체 지향의 도움을 잘 받고 있는 것일까요? 개념은 매우 광범위하고 여러 가지 구현이 가능하지만, 결국에는 일관된 속성을 많이 가지고 있습니다. 이것이 소프트웨어를 작성하는 가장 좋은 방법이라는 데 모두 동의하시나요? 앞으로도 이것이 최선의 방법이라고 생각하시나요?
So are we being well-served by Object Orientation as commonly embodied, right? The concept is pretty broad and there are multiple possible embodiments, but it ends up the ones that we have have a lot of consistent attributes. Do we all agree this is the best way to write software? Do we think this will continue to be the best way?

확실히 오늘날에는 이 모델이 확고하게 자리 잡고 있습니다. 어떤 언어를 사용하든 상관없습니다. 사람마다 잘하는 언어와 그렇지 않은 언어가 다르기 때문입니다. 스칼라, 자바, C#을 사용하는 사람들은 이러한 언어 간의 차이점을 좋아하지만, 저는 이러한 언어가 모두 단일 디스패치, 상태 저장 객체 지향 언어이며 클래스, 클래스 개념, 상속 등 많은 부분이 동일하다는 유사점에 집중하길 바랍니다. 필드는 개념적으로 흥미롭습니다. 메서드는 더 흥미로운데, 이에 대해서는 나중에 이야기하겠습니다. 메서드는 모두 가비지 컬렉션이며 Smalltalk와 같은 언어로 거슬러 올라가는 유산을 가지고 있습니다.
Certainly today, this is a really entrenched model. It doesn’t matter which language you’re using. Everybody has different languages that are groovy and whatnot. Scala and Java and people use C# and they love the differences between these languages and I want you to focus on the similarities between these languages, which is they’re all single-dispatch, stateful object-oriented languages and they have a lot of the same kinds of things in classes, some notion of classes, inheritance. Fields are interesting in concept. Methods are more interesting and we’ll talk about them later. They’re all garbage-collected and they have a heritage that goes back to languages like Smalltalk.

어떤 면에서는 크게 다르지 않죠? 표면적으로만 다르죠. 믹스인이 있을 수도 있고 인터페이스가 있을 수도 있습니다. 정적 타이핑과 동적 타이핑조차도 두 언어가 공유하는 몇 가지 토대만큼 중요하지 않다고 생각합니다. 세미콜론이 없는 언어와 다른 훌륭한 선택지가 생겼기 때문에 모두가 매우 흥분하고 있습니다. 하지만 이는 프로그램의 감성과 더 관련이 있으며 프로그래밍 모델의 중요한 차이와 관련이 있습니다. 알겠어요? 그래서 모두 다른 차들이지만 모두 같은 도로를 달리고 있습니다.
They’re not significantly different in some dimensions, right? They’re superficially different. They might have mix-ins and they have interfaces. Even static and dynamic typing, I think, is not nearly as important as some of the underpinnings that they share. Everybody is so excited because now there are languages without semicolons and other great choices that we have. But they have more to do with the sensibilities of the program where then they have to do with significant differences in the programming model. Okay? So they’re all different cars, but they’re all on the same road.

이게 끝인가요? 이제 끝인가요? 우리가 알고 있는 것들과 아주 조금씩만 다른 언어를 계속 만들어야 할까요? 물론 한 가지 부인할 수 없는 사실은 사람들이 객체지향 언어를 좋아한다는 것입니다. 반면에 우리는 점점 더 보수적으로 변해가고 있다고 생각합니다. 말이 되는 말이죠. 물론 대기업에서 채택하고, 큰 투자를 하고, 사람들이 그 방법을 알고 있으니까요. 하지만 너무 쉽게 포기할 수 있는 것은 아닙니다. 그리고 분명히 강조하고 싶은 것은, 이 강연의 목적은 OO를 두들겨 패자는 것이 아니라 모두가 한 발짝 물러서서 마음에 들지 않는다고 상상해보고, 마음에 든다고 해도 그것이 완벽한지 생각해 보자는 것입니다.
Is this the end? Are we done? Are we going to keep making languages that are just very, very slight incremental differences to the things that we know? Certainly, one thing is undeniable, people like Object Orientation. On the other hand, I think we’ve gotten increasingly conservative. And which makes sense. Of course, you get adopted by large companies, they have big investments, people know how to do it. It’s not something you’re going to move away from any too readily. And certainly, I want to emphasize, the purpose of this talk is not to beat up on OO, but to have everybody just take a step back; just imagine you don’t love it, if you do, and think about whether or not it’s perfect.

언어를 보면서 다른 언어를 쓸 수 있는지, 이 언어를 고칠 수 있는지, 다음 버전의 언어에 기능을 추가하는 등 무언가를 만들 수 있는지 생각해 볼 때 우리는 어떻게 할까요? 우리는 왜 무언가를 추가할까요? 무엇이 우리를 변경하게 만들까요, 아니면 무엇이 우리가 "이 언어 사용을 중단하고 다른 언어를 채택할 거야"라고 말하게 만들까요? 그리고 어떤 것들이 우리를 그렇게 만들까요? 많은 사람들이 "세미콜론이 지겨워요. 더는 못하겠어요. 중괄호 같은 걸로 바꿔야겠어요. 더 쉬운 것으로 바꿔야겠어요."라고 말하죠. 정적과 동적은 사람들이 바꾸게 하는 원인이 될 수 있다고 생각하지만, 무엇이 우리를 바꾸게 하는지를 보여주는 사례는 이미 역사에 존재한다고 생각합니다.
When we look at languages and try to think of if I could write another language or if I could fix this language or if I could make something – add a feature to the next version of the language – what would we do? Why do we add things? What drives us to make changes or what drives us to change cars to say, “I’m going to stop using this language and adopt this other language”? And what things should drive us to that? I don’t think a lot of people say, “Oh, I’m tired of semicolons. I can’t do it anymore; curly braces or something. I’m going to switch to something easier.” I think static and dynamic may cause people to switch, but I think there are examples already in our history that show us what causes us to switch.

오늘 제가 이야기할 내용은 여러분이 사용하고 있는 언어를 되돌아보고 무언가 다른 것을 하고 싶은지 여부를 결정할 때 고려해야 할 사항의 일부에 불과합니다. 오늘은 복잡성에 대해 이야기하고 싶습니다. 저는 시간에 대해 이야기하고 싶습니다. 주로 시간에 대해요. 그리고 시간을 더 잘 구현하는 데 사용할 수 있는 모델과 객체지향의 근간이 되는 몇 가지 원칙에 대해 설명하겠습니다. 모델링 개념이죠? 모델링은 우리가 세상에서 보는 것과 비슷한 일을 프로그램에서 할 수 있다는 것을 기반으로 하며, 이는 프로그램을 이해하는 데 도움이 됩니다.
So the things I’m going to talk about today are a small subset of the kinds of things that I think you should think about when you look back at the language you’re using and try to decide whether or not you want to do something differently. I want to talk about complexity today. I want to talk about time. Mostly about time. And then, about models we can use to better implement time and some of the principles that underlie Object Orientation. It’s a modeling concept, right? It’s based around we can sort of do things in our programs that are similar to what we see in the world, and that helps us understand our programs.

오늘 강연의 주인공은 알프레드 노스 화이트헤드입니다. 아시죠? 그는 러셀과 함께 프린키피아 수학을 저술한 유명한 사람입니다. 그 후 그는 철학자가되었고 몇 가지 훌륭한 글을 썼는데 훌륭하기 때문에 여기에 올려 놓을 것입니다. 첫 번째는 불신 단순성(distrust simplicity)입니다. 저는 우리가 해결하고자 하는 문제의 복잡성에 대해 실제로 이야기하고 싶지 않습니다. 우리 모두는 해결해야 할 문제가 점점 더 복잡해지고, 더 큰 문제, 더 많은 데이터, 더 많은 유연성이 주어진다는 것을 알고 있습니다. 소프트웨어에 대한 사람들의 기대치는 점점 더 높아질 것입니다.
So the hero of the talk today is Alfred North Whitehead. Right? He’s the famous guy who with Russell wrote Principia Mathematica. Subsequent to that, he also became a philosopher and he wrote some great things and I’m just going to put them up here because they’re great. So the first thing is distrust simplicity. I don’t want to talk actually about the complexity of the problems we’re trying to solve. We all know we’re given increasingly more complex problems to solve, bigger problems, more data, more flexibility. Expectations of people for software will only ever increase.

오늘 제가 이야기하고자 하는 복잡성은 부수적인 복잡성입니다. 도구가 작동하는 방식, 도구를 구현하는 아이디어, 도구가 작동하지 않는 방식, 접근 방식이 작동하지 않는 방식에서 발생하는 복잡성입니다. 이 모든 것이 우리가 해결해야 하는 문제가 되고, 하루 중 일정 시간 동안 문제를 해결해야 합니다. 해결해야 하는 문제가 애플리케이션 도메인의 문제입니까, 아니면 특정 언어나 도구 또는 개발 전략을 선택함으로써 스스로 설정한 문제입니까? 이것이 바로 부수적인 복잡성입니다. 부수적으로 발생하는 복잡성입니다. 해결하려는 문제의 일부가 아닙니다.
제 생각에는 더 심각한 문제입니다. 무언가가 복잡해지면 누구나 "아!!! 복잡해!" 그러면 다들 "알았어요. 알겠어요. 무섭네요. 저기가 위험 지대라는 걸 알아요. 조심해야겠어요."라고 말합니다. 최악의 부수적인 복잡성은 단순함을 가장한 복잡성입니다. "이게 얼마나 쉬운지 보세요! 세미콜론이 없잖아요." 저는 세미콜론에 대해 두들겨 패고 싶지 않습니다. "내가 사용하는 언어의 표면적인 측면만 보면 이게 쉬워 보이고 익숙해 보이는데, 그 밑에 부수적인 복잡성이 숨어 있는 건 아닌지?"라고 쉽게 말할 수 있는 방법일 뿐입니다.
The complexity I want to talk about today is the incidental complexity. The complexity that arises from the way our tools work, from the ideas that embody our tools, from the ways our tools don’t work, from the ways our approaches don’t work. These things all become problems that we have to solve and we have a certain number of hours in the day we have to solve problems. Are the problems you’re solving the problems of the application domain or the problems you’ve set in front of yourself by choosing a particular language or tool or development strategy? So that’s incidental complexity. It’s coming along for the ride. It’s not part of the problem you’re trying to solve.
And it’s worse, I think. I mean, everybody knows when something is complex and you look at it, it says, “Arrr!!! Complex!” And everybody says, “Okay. Well I see that. That is scary. I know that’s a danger zone. I know I’m going to be careful with that.” The worst kind of incidental complexity is the kind that’s disguised as simplicity. “Look how easy this is! There’s no semicolons.” I don’t want to beat up on those semicolons. It’s just an easy way to say, “Look, at some superficial aspect of language I’m using, this seems easy, this seems familiar,” but is there incidental complexity hiding underneath it?
# 메모리 관리가 없는 C++

이것이 한 예입니다. 다시 한 번 말씀드리지만, 저는 이 작업을 10년 넘게 해왔습니다. 그래서 그렇게 어렵지 않습니다. 템플릿 메타프로그래밍에 들어가면 어려워질 수 있습니다. 하지만 기본은 꽤 간단하죠? 포인터를 반환하는 함수를 작성하면 됩니다. 그게 뭐가 어렵겠어요? 아주 간단합니다. 새로 만들기와 삭제가 있고 포인터가 있으며 포인터를 전달하고 참조를 해제할 수 있습니다. 알아야 할 것은 다섯 가지 정도밖에 없습니다. 오후에 배우면 됩니다.
정말 간단합니다. 예를 들어, 힙에 있는 객체와 힙에 없는 객체를 가리키는 데 동일한 구문이 사용되는데, 바로 포인터입니다. 하지만 더 나빠지죠? 함수 시그니처의 진짜 문제는 함수 시그니처를 호출할 때 얻는 것을 어떻게 처리하느냐는 것입니다. 당신의 것입니까? 이제 여러분의 책임인가요? 나중에 삭제해야 하나요? 심지어 삭제할 수 있는 것일까요? 다른 사람에게 넘겨줄 수 있나요? 그래도 되나요? 저장할 수 있나요?
그래서 문제는 표준 자동 메모리 관리가 없다는 것이었습니다. 그렇죠? 가비지 컬렉션이 없죠. 그리고 이것은 이 언어를 사용하는 사람들에게 부수적인 복잡성의 큰 원인이었고 지금도 마찬가지입니다. 그렇죠? 메모리 관리는 사용자가 직접 해야 하기 때문이죠. 그런 건 보이지 않죠. 소스 코드 상단에 "잊지 마세요. 메모리 관리는 여러분의 책임입니다."라는 문구가 없습니다. 그렇죠? 이것은 부수적인 복잡성입니다. 그 점만 알아두면 됩니다. 소스 코드에는 없습니다.
그리고 그것은 큰 문제입니다. 가비지 컬렉션의 부족은 라이브러리 언어라는 C++의 설계 목표 중 하나에 큰 장애가 된다고 생각합니다. 원래 디자인에 관한 모든 것, 그리고 스트로스트럽의 이야기를 들을 때마다 C++는 라이브러리 언어가 될 것 같았습니다. 하지만 결국 교구 단위의 라이브러리 언어(parochial library language)가 되고 말았습니다. 모든 상점에는 라이브러리가 있었지만 라이브러리가 없었고, 여전히 이 문제로 인해 여러 곳을 오가는 라이브러리가 많지 않았습니다. 가비지 컬렉션이 있는 자바는 거대한 라이브러리 인프라를 갖추고 있습니다. 따라서 C++에서 Java로 전환한 사람들은 이러한 암묵적인 복잡성을 더 이상 감수하고 싶지 않았기 때문에 그렇게 한 것이라고 생각합니다. 수동 메모리 관리를 하고 싶지 않아요. 제가 해결하려는 문제의 일부가 전혀 아니니까요. 매일 출근할 때마다 또 다른 문제가 생겨서 하기 싫을 뿐입니다.
So, this is an example. Again, not to beat up on C++, but I spent more than a decade doing this. So, it’s not that hard. I mean, if you get into template metaprogramming, it can get hard. But the basics are pretty simple, right? You can write a function that returns a pointer. What’s wrong with that? It’s pretty simple. There’s new and delete and there’s pointers and you can pass them around and you can dereference them. There’s only like five things you need to know. You can learn them in an afternoon.
So it is really simple. For instance, the same syntax is used to refer to things on a heap and things that are not on a heap; these pointers. But it gets worse, right? And the real problem with that function signature is what do you do with the thing that you get when you call it? Is it yours? Is it now your responsibility? Do you have to delete it later? Is it even something that can be deleted? Can you hand it to somebody else? Is that allowed? Could you save it?
So the problem there was there’s no standard automatic memory management. Right? There’s no garbage collection. And this was, and still is, for people using this language, a big source of incidental complexity. Right? Because managing memory is on you. You don’t see that. There’s not a sign on the top of your source code, “Don’t forget; managing memory is on your head.” Right? This is incidental complexity. You have to just know that. It’s not in the source code.
And it’s a big problem. I think the lack of garbage collection really impeded C++ in one of its design objectives, which is it’s supposed to be a library language. All the original design stuff and any time you heard Stroustrup talk about it, it’s like C++ is going to be a library language. But it only ever ended up being a parochial library language. Every shop had a library, but there weren't a library, and still not a lot of libraries that go between places because of this problem. And we know that Java, having garbage collection, has this huge library infrastructure. So I think people that moved from C++ to Java did so in no small part due to the fact that they were no longer willing to bear this implicit complexity. I don’t want to do manual memory management. It’s not part of the problem I’m trying to solve at all. It’s just another problem on my plate every day when I go to work and I don’t want to do it.
# 메모리 관리가 있는 Java

이제 Java를 살펴봅시다. 별표가 없으니 더 쉽습니다. 이것은 훨씬 더 좋습니다. 그럼 뭐가 문제일까요? 더 간단합니다. 확실히 더 간단합니다. 그렇죠? 이제 관리되는 메모리에 대한 참조만 있고 자동 메모리 관리가 있습니다. 가비지 컬렉션도 있습니다. 훨씬, 훨씬 낫습니다. 훨씬 쉬워졌죠. 하지만 숨겨진 복잡성이 있다는 점만 빼면요. 그렇죠? 이게 변경 가능한 건가요, 아닌가요? 언제 일관된 값을 볼 수 있을까요? 지금 이걸 보고 필드를 돌아다니면 내가 본 것 중 어떤 것이 일관된 가치를 나타낼까요? 그렇습니다. 이것은 단순한 동시성 문제가 아닙니다. 그렇죠? 동시성 문제는 큰 문제입니다.
하지만 스레드와 그 모든 부분이 있기 전에도 안정적인 값이 언제 나올지 모르기 때문에 프로그램에서 부수적인 복잡성의 큰 원인이었습니다. 그렇죠? 이 날짜를 저장해 두었다가 나중에 보면 내가 이 날짜를 건네받았을 때 보았던 것을 볼 수 있을까요? 그건 모르죠. 또한 날짜나 변경 가능한 것을 건네주면 - 변경 가능한 것은 모두 사용되지 않는 것으로 알고 있습니다. 날짜나 뭐 그런 걸 고치고 있잖아요. 날짜를 때리려는 게 아니에요. 하지만 누군가에게 변경 가능한 것을 건네주면 그 사람이 다른 사람에게 건네줄 수 있고, 그 후에 변경해야 한다면 누가 영향을 받게 될까요? 여러분은 전혀 모릅니다.
그래서 이것은 정말 쉬워 보입니다. 사실입니다. 이것은 Java뿐만이 아닙니다. 제가 나열한 가변 객체를 허용하는 모든 언어가 이 문제를 가지고 있으며 이를 해결할 방법이 없습니다. 그렇다면 무엇이 문제일까요? 저는 여기서 표준 시간 관리가 없다는 것이 문제라고 말하고 싶습니다. 알겠어요? 정말 혼란스러울 수 있습니다. 앞으로는 그렇게 되지 않기를 바랍니다.
So, let’s look at Java. It’s easier; there’s no asterisk. This is like even better. So what’s the problem with this? It’s simpler, it’s definitely simpler. Right? Now, we only have references to managed memory and we have automatic memory management. We have garbage collection. This is much, much better. It’s much easier. Except, again, we have this hidden complexity. Right? Is this a mutable thing or not? When will I see a consistent value? If I look at this right now and I walk through its fields, will some of the things I’ve seen represent a consistent value? All right. This isn’t just a concurrency problem. Right? There is a concurrency problem and it’s a big one.
But even before we had threads and all that part, this is a big source of incidental complexity in programs because we don’t know when we have a stable value. Right? Can I store this date off and look at it later and know I’m going to see what I saw when I was handed it? You don’t know. In addition, if you hand a date or some mutable thing – I mean, I know the mutable things have been all deprecated. They’re fixing date or whatever. I’m not trying to beat up on date. But if you hand a mutable thing to somebody and they may hand it to other people, and then you need to change it, who is going to be affected by that? You have no idea.
So this looks really easy. Now, this is true. This is not just Java. This is every single language I listed that allows for mutable objects has this problem and there’s no way to fix it. So what’s the problem here? I’m going to say the problem here is we don’t have any standard time management. Okay? That may be a really confusing thing. Hopefully, it won’t be as we go along.
# 친숙성이 복잡성을 가린다

앞서 말씀드린 내용을 약간 반복하는 것 같은데요. 우리는 이 문제에 너무 익숙하기 때문에 이 문제에 대해 전혀 모르고 있다고 생각합니다. 그렇죠? 그리고 우리가 언어를 선택하거나 사람들이 다른 언어를 선택할 때, 많은 경우 구문이나 아마도 이것이 나를 기분 좋게 만든다거나 표현력의 차이와 같은 매우 피상적 인 차이로 결정을 내리는 경우가 많습니다. 그 동안 우리 시스템은 구축, 유지보수 및 수정하기가 매우 어려워지고 있습니다. 이는 부수적인 복잡성 때문이기도 합니다. 우리는 큰 프로그램을 이해할 수 없습니다. 그렇죠? 우리에게는 거대한 테스트 스위트가 있죠? 그리고 사소한 것을 변경할 때마다 테스트 스위트를 실행해왔죠. 여기서 무언가를 변경하면 저기서 무언가가 깨지지 않을지 알 수 없기 때문입니다. 알 수 없으니까요. 저뿐만 아니라 많은 사람들이 이 분야에서 동시성이야말로 낙타가 바늘구멍을 통과할 수 있는 지푸라기라고 생각합니다.
So, this is kind of a little bit of a reiteration of the points I was making before. I think that because we’re so familiar with this, we’re absolutely, completely blind to it. Right? And when we choose languages or when people choose different languages, a lot of times, they make the decision on very superficial differences like the syntax or perhaps sort of this makes me feel good, expressivity differences, which I admit completely are real and valid, but they’re somewhat emotional. In the meantime, our systems are getting very, very hard to build, maintain and make correct. And in no small part, that’s due to this incidental complexity. We can’t understand big programs. Right? We have these giant test suites, right? And we’ve run them every time we changed any little thing. Because we don’t know if we change something over here, that it’s not going to break something over there. And we can’t know. And I think for me, and I think for many people, we’re going to find concurrency just is the straw that breaks the camel’s back in this area.

그래서 우리는 프로그래머입니다. 우리는 더 이상 어셈블리 언어를 사용하지 않습니다. 우리에겐 언어가 있죠. 그렇죠? 새로운 언어를 빌드하거나 새로운 언어를 사용할 때마다 이 영역에서 몇 가지 이점을 기대합니다. 그렇죠? 우리는 덩어리들을 숨기고, 이름을 붙이고, 캡슐화하고, 그것들에 대해 생각할 필요 없이 그 위에 무언가를 만들 수 있기를 원합니다. 벽돌로 집을 짓는 사람은 벽돌 내부에 대해 걱정할 필요가 없잖아요. 그렇죠? 벽돌에는 특정한 속성이 있고, 특정한 기대치가 있습니다. 객체지향의 장점 중 하나는 이러한 종류의 단위를 결합하여 이해하기 쉬운 프로그램을 만들 수 있다는 점입니다. 우리는 조각을 이해하기 때문에 조각을 조합하면 이해할 수 있는 무언가를 얻을 수 있습니다.
So we’re programmers. We don’t use assembly language anymore. We have languages. Right? Each time we build a new language or we use a new language, we’re expecting some benefits in this area. Right? We want to hide chunks of stuff, name them, encapsulate them, get them out of our way so we do not have to think about them and we can build something on top of that. I mean, somebody who’s building houses out of bricks does not need to worry about the inside of bricks. Right? They have certain properties, they have certain expectations. And I think it’s one of the selling points of Object Orientation, that this is a way to make these kinds of units that we can combine to make programs that are easy to understand. Because we understand the pieces, when we put the pieces together, we get something we can understand.

결국에는 그 단위가 그것에 가장 적합한 단위가 아니라는 것을 알게 됩니다. 이를 위한 최고의 단위는 함수입니다. 특히 순수한 함수는 더욱 그렇습니다. 그렇죠? 걱정할 필요가 없는 것을 원한다면 순수 함수를 좋아해야 합니다. 순수 함수는 불변의 값을 취합니다. 그 값으로 무언가를 수행합니다. 그 함수가 하는 일은 세상에 아무런 영향을 미치지 않으며 외부 세계와도 아무런 관련이 없습니다. 그런 다음 또 다른 불변의 것을 반환합니다.
따라서 그 활동의 전체 범위는 로컬입니다. 시간 개념이 없습니다. 이는 나중에 중요해질 것입니다. 하지만 확실히 이해하기 쉽습니다. 변경하기 쉽기 때문입니다. 그렇죠? 시그니처가 있어요. 다른 사람이 아는 건 그것뿐이죠. 내부를 바꾸면 아무도 신경 쓰지 않습니다. 순수한 기능은 우리가 가장 쉽게 걱정 없이 사용할 수 있는 것이기 때문에 우리가 사용하는 벽돌이 되어야 하고, 또 그래야 합니다. 이렇게 하면 분명 큰 이점이 있습니다. 객체 지향 언어에서는 쉽게 할 수 있다고 생각하지만 사람들은 그렇지 않습니다.
반대로 객체와 메서드에는 이러한 속성이 없습니다. 객체와 메서드에는 "생각할 필요가 없다"는 속성이 없습니다. 확실히 없습니다. 그 이유를 잠시 후에 살펴보겠습니다.
It ends up that they’re really not the best unit for that. The best unit for that are functions. And in particular, pure functions. Right? If you want something you do not have to worry about, you should love the pure function. The pure function takes immutable values. It does something with them. That stuff it does has no effect on the world and no connection on the rest of the outside world. Then it returns another immutable thing.
So the entire scope of its activity is local. It has no notion of time. That’s going to become important later. But it’s definitely easy to understand. It’s easy to change. Right? There’s some signature. That’s the only thing about it anybody else knows. When we change the insides, nobody cares. Pure functions are and should be the bricks that we use because they are the things we can use without worrying about them most readily. There are definitely huge benefits from doing this. I think you could easily do it in object-oriented languages, but people don’t.
In contrast, objects and methods do not have this property. They do not have the “I don’t need to think about them” property. They definitely don’t. And we’re going to see why in a minute.

반면에 함수가 빌딩 블록만큼이나 훌륭하지만, 우리 프로그램은 일반적으로 함수가 아닙니다. 아시겠죠? 함수인 프로그램도 있잖아요? 컴파일러와 정리 증명자가 있죠. 이런 것들을 가져다가 변환하거나 뭐든 하죠. 하지만 많은 프로그램이 무한히 오래 실행되고 사람들은 프로그램이 실행되는 동안 동작을 볼 수 있고 입력을 받을 수 있기를 기대합니다. 그렇죠? 그리고 매번 다른 무언가를 얻길 원하죠.
같은 단어를 입력할 때마다 같은 결과가 나오는 것은 원치 않아요. 그러면 Google은 저를 위해 작동하지 않을 것입니다. 구글이 함수라면 아무 소용이 없겠죠. 알겠어요? Google은 전 세계와 연결된 프로세스입니다. 페이지를 샅샅이 뒤져 통합하고 알고리즘을 형성하고 있는데, 이 또한 변화해야 합니다. 전체적으로 보면 더 이상 기능이라기보다는 세상의 참여자처럼 느껴집니다. 이상적인 계산이 아닙니다. 따라서 전체 프로그램에는 시간이 지남에 따라 관찰할 수 있는 이러한 동작이 있다고 말할 수 있습니다(제가 "동작"이라는 단어를 좋아하지 않는다는 것을 아시겠지만). 따라서 대부분의 프로그램, 업계에서 대부분의 사람들이 작업하는 대부분의 프로그램은 프로세스입니다.
On the other hand, as great as functions are as building blocks, our programs in general are not functions. Okay? There are programs that are functions, right? There are compilers and theorem provers. Take this stuff and convert it or whatever. But a lot of programs run indefinitely long and people have an expectation of being able to see their behavior, to have inputs as the program runs. Right? And get something different every time.
I don’t want Google to return the same result every time I type the same word into it. Google wouldn’t work for me then. If Google was a function, it would be no good. Okay? Google is a process that’s connected to the rest of the world. It’s scouring pages and integrating them and forming algorithms, which hopefully also should change. As a whole, it feels much more like a participant in the world than a function anymore. It’s not an idealized calculation. So we can say that the entire program has this behavior we can observe over time, although you’ll see I don’t like the word “behavior.” So most programs, most programs that most people work on in industry are processes.
# OO와 "변화"

어쩌면 우리는 함수의 가치를 제대로 보지 못했을 수도 있습니다. 확실히 그렇지 않다고 생각합니다. 하지만 한계도 보았습니다. 객체 지향은 "함수는 훌륭하고 계산과 그 밖의 모든 것에 유용합니다."라고 말하는 방식이었습니다. 하지만 현실 세계에는 객체도 있고 창 시스템도 있고 사물도 있습니다."라고 말하는 방식이었습니다. 객체 지향은 "좋아. 그럼 우리가 세상에서 보는 프로세스에 대한 우리의 정신적 모델을 어떻게 프로그래밍 모델로 구현할 수 있을까요?"라고 묻는 것입니다. 그렇죠? 따라서 객체 지향 프로그램의 본질은 캡슐화나 어쩌고저쩌고 하는 것이 아닙니다. 실제로는 동작, 흐름과 같은 것입니다. 우리는 세상에서 어떤 일을 하는 개체를 볼 수 있습니다. 우리 프로그램에도 일을 하는 엔티티가 있어야 합니다.
So maybe we haven’t seen the value of functions. I certainly don’t think we have. But we also have seen the limitations. Object Orientation was a way to say, “Well, you know, functions are great and they’re great for calculations and all those stuff. But then I see the real world and there are objects and there are windowing systems and there are things.” And Object Orientation was a way to say, “All right. Well how do we take our mental model for the processes we see in the world and embody them in some kind of programming model?” Right? And so, the essence of the Object-Oriented program is not encapsulation, blah, blah, blah. It’s really that behavior, that flow-like thing. We have these entities we see doing things in the world. We should have entities that do things in our programs.

따라서 우리가 가장 먼저 깨달아야 할 것은 현실 세계를 모델링하려는 모든 프로그램 모델은 본질적으로 단순하다는 것입니다. 알겠죠? 하지만 다시 한 번 "단순함을 조심하라"는 말이 있습니다. 너무 단순해서 일을 제대로 수행하지 못할까요? 그렇죠? 객체 지향 시간의 문제 중 하나는 행동과 상태 등에 대해 매우 느슨하게 이야기한다는 것입니다. 이러한 용어는 거의 의미가 없습니다.
또한 객체가 프로세스에 관한 것이라고 가정하더라도 객체에는 시간에 대한 개념이나 구체적인 개념이 없습니다. 함수에는 더더욱 없습니다. 하지만 적어도 함수는 시간을 가지고 노는 척하지는 않습니다. 함수는 시간이 없다고 말합니다. 그렇죠? 입력과 출력만 있을 뿐이죠. 저는 시간을 다루는 척하지 않습니다. 객체가 시간을 다루는 척하는 거죠. 하지만 우리의 객체 시스템에는 시간에 대한 명확한 개념이 없습니다. 대부분 프로그램이 컴퓨터를 지배하던 시대에 탄생했기 때문에 명시적으로 이야기할 수 있는 것이 없습니다. 단조로운 단일 실행 흐름이 있었고 프로그램은 원하는 대로 실행했습니다. 모든 것을 제어하는 하나의 보편적인 프로세스가 있었습니다.
이제 더 이상 그렇지 않으므로 우리는 잠금을 사용하여 이러한 세계관을 복원하려고 합니다. 하지만 그 세계관은 결코 옳지 않았습니다. 그 이유는 모든 잠금 장치와 다른 모든 것을 사용하더라도 여전히 우리가 지각에 사용할 수 있는 구체적인 표현이 없기 때문입니다. 무언가를 보고 안정된 것을 볼 수 있을까요? 기억도 마찬가지입니다. 기억할 수 있을까요? 그렇죠? 이 물체들은 모두 살아 있습니다. 시한폭탄이죠. 그렇지? 우리가 잘못 생각했어요. 객체 지향 모델은 시간을 잘못 이해했습니다.
So, the first thing we should realize, that any program model is going to be – that tries to model the real world - is essentially going to be a simplistic thing. Okay? But again, there’s that "beware of simplicity." Is this thing too simple to do the job correctly? Right? One of the problems with object-oriented time is that we talk about behavior and state and things like that really, really loosely. These terms are almost completely meaningless.
And in addition, even though objects putatively are about process, there’s no notion, no concrete notion of time in objects. No more so than there are in functions. But at least functions aren’t pretending to play with time. Functions say there’s no time. Right? There’s my inputs and my outputs. I’m not pretending to deal with time. Objects are pretending to deal with time. And yet, our object systems don’t have any reified notion of time. There’s nothing you can talk about explicitly because most of them were born in the day when your program ruled the computer. You had a single monotonic execution flow and it just did what it wanted; do this, do that. There was a single universal process controlling everything.
Now that that’s no longer true, we try to use locks to restore that vision of the world. But that vision of the world was never correct. And you can tell in one key way because we still, even with all the locks and everything else, we still don’t really have a concrete representation we can use for perception. Can I look at something and see it be stable? Or memory. Can I remember that? Right? These objects are all live. They’re time bombs. Right? We have gotten this wrong. The object-oriented model has gotten time wrong.
# 화이트헤드의 시간 개념

이를 위해 몇 가지 방법을 사용했습니다. 첫 번째는 제자리에서 변화할 수 있는 오브젝트를 만들고 제자리에서 변화하는 것을 볼 수 있는 오브젝트를 만들었습니다. 그렇죠? 아까 말씀드렸듯이 시간에 대한 구체적인 개념과 가치에 대한 적절한 개념이 없습니다. 알겠죠? 값을 조작할 수 있습니다. 그렇죠? 모든 불변 컴포넌트를 가진 클래스를 만들 수 있고, 그것이 값을 구성할 수 있습니다. 하지만 많은 언어에는 값에 대한 적절한 개념이 없습니다.
우리가 가진 가장 큰 문제는 두 가지를 혼동했다는 것입니다. 우리는 시간이 지나도 변하지 않는 것에 애착을 갖는 것이 시간이 지나도 변하지 않는 것이라고 말했죠. 하지만 실제로는 그렇지 않습니다. 또한 앞서 말했듯이 실제로는 깨지기 쉬운 것으로 인식됩니다.
그래서 여기 오늘의 주인공인 화이트헤드를 모셨습니다. 화이트헤드는 제가 말씀드린 것처럼 '프린키피아 수학'을 연구한 후 철학자가 되었고, 양자역학과 상대성 이론에 대한 20년대 당시의 지식을 바탕으로 세상이 실제로 어떻게 작동하는지에 대해 관심을 가지려고 노력했습니다. 그리고 그가 생각해낸 것 중 하나는 시간은 원자 단위로 움직여야 한다는 사실입니다. 사실 시간은 실제로 만질 수 있는 실체는 아니지만, 이러한 시대적 전환을 보면서 얻을 수 있는 개념입니다.
And we’ve done so in a couple of ways. The first is we’ve made objects that can change in place and we’ve made objects that we could see change in place. Right? As I’ve said, we left out any concrete notion of time and there’s no proper notion of values. Okay? You can fabricate values. Right? You can make a class that has all immutable components, and that would constitute a value. But there’s no proper notion of value in a lot of these languages.
The biggest problem we have is we’ve conflated two things. We’ve said the idea that I attach to this thing that lasts over time is the thing that lasts over time. And that’s not actually true. In addition, as I said before, it really is perceived as fragile.
So I have the hero of the day, Whitehead up here. Who, subsequent to doing all the Principia Mathematica stuff, as I said, became a philosopher, and he tried to concern himself with how does the world actually work informed by the current knowledge, which this was back in the ‘20s, of Quantum Mechanics and Relativity. And one of the things that he came up with was the fact that time must be atomic and move in chunks. And in fact, time isn’t actually a real thing you can touch, but it’s something that you derive from seeing these epochal transitions.

자세한 설명은 나중에 하겠지만, 이 말은 정말 좋은 인용구입니다. 그렇죠? "어떤 사람도 같은 강을 두 번 건널 수는 없다." 강이 뭔가요? 우리는 사물에 대한 이런 개념을 좋아합니다. 마치 변화하는 것이 있는 것처럼요. 그렇죠? 강은 없어요. 그렇죠? 어느 시점에는 물이 있고. 그리고 또 다른 시점에는 다른 물이 있죠. 그렇죠? 강; 그것은 모두 여기 [마음]에 있습니다. 알겠어요?
So I’m going to explain that more, but this is a great quote. Right? “No man can ever cross the same river twice.” Because what’s a river? I mean, we love this idea of objects; like there’s this thing that changes. Right? There’s no river. Right? There’s water there at one point-in-time. And another point-in-time, there’s other water there. Right? River; it’s all in here [the mind]. Okay?
# 변하지 않는 실체는 없다

그렇다면 어떻게 이런 실수를 저질렀을까요? 이 실수의 진짜 본질은 무엇일까요? 그렇죠? 제자리에서 메모리를 바꿀 수 있을 것 같았어요. 그렇죠? 우린 그렇게 하고 있었어요. 엿보기와 찌르기가 있는데 그걸 볼 수 있을 것 같았어요. 읽을 수 있었죠. 하지만 우리가 메모리에 저장하는 것 중 시간과 상관관계가 있는 것은 아무것도 없었어요. 그렇죠? 다시 살아났죠. 이제 우리는 "새로운 컴퓨터 아키텍처를 보세요. 변수가 어디에 있지?" 여기에는 한 시점의 버전이 하나 있습니다. 그렇죠? 그리고 여기 또 하나 있습니다. 그리고 저기 있는 것은 언젠가 저쪽에서 볼 수 있는 곳으로 가는 중입니다. 라이브입니다. 이제 문제가 보입니다. 그렇죠? 값은 변하지 않습니다. 특정 시점의 가치만 존재하고, 그 시점에 대한 가치만 얻을 수 있습니다. 그렇죠? 그리고 가치는 변하지 않습니다. 그렇죠?
따라서 화이트헤드의 가장 큰 핵심 통찰은 변하는 물체라는 것은 없다는 것이었습니다. 우리가 발명했죠. 우리는 그것들을 발명하지 말아야 합니다. 알겠죠? 그리고 화이트헤드의 모델은 제가 지나치게 단순화하고 있습니다. 알겠어? 이해도 안 돼요. 이 책은 완전히 벅찬 책이지만 정말 멋진 통찰력으로 가득 차 있습니다. 그리고 그가 구축한 것은 불변하는 것이 있다고 말하는 모델입니다. 그런 다음 우주에는 다음 불변하는 것을 만들어내는 과정이 있습니다.
그리고 우리가 연속적이라고 보는 실체는 인과관계가 있는 여러 가치에 중첩된 것입니다. 우리는 시간이 지남에 따라 일어나는 일들을 보고 "아, 저건 프레드야!" 또는 "저건 우리 집 뒤편에 있는 강이야" 또는 "저건 구름이야"라고 말합니다. 그렇죠? 구름을 충분히 오래 보고 있다가 갑자기 구름이 세 개였거나 구름이 사라졌다는 것을 알 수 있습니다. 그렇죠? 구름은 변하지 않습니다. 그렇죠? 구름이라는 개념을 일련의 관련 구름 값에 겹쳐서 생각하면 됩니다.
So how did we make this mistake? What’s the real nature of this mistake? Right? It looked like we could change memory in place. Right? We were doing it. There’s PEEK and POKE and it looked like we could see that. We could read. But there was nothing about what we were putting in memory that had any correlation to time. Right? It was live again. And now we’re finding, “Well, look at these new computer architectures. Where is the variable?” Well, there’s one version over here from one point-in-time. Right? And another one over here. And that’s on its way to a place that this over there might see at some point. It’s live. Now we see the problem. Right? There are no changing values. There’s values at points in time and all you’re ever going to get is the value for a point-in-time. Right? And values don’t change. Right?
So the biggest key insight of Whitehead was there’s no such thing as a mutable object. We’ve invented them. We need to uninvent them. Okay? And Whitehead’s model, which I am grossly oversimplifying. Okay? I don’t even understand it. The book is completely daunting, but it’s full of really cool insights. And what’s he’s built is a model that says there’s this immutable thing. Then there’s a process in the universe that’s going to create the next immutable thing.
And entities that we see as continuous are a superimposition we place on a bunch of values that are causally-related. We see things happen over time and we say, “Oh, that’s Fred!” or “Oh, that’s the river outside the back of my house” or “That’s a cloud.” Right? We know you can look at a cloud for enough time, and all of a sudden it’s like, well, that was three clouds or the cloud disappeared. Right? There is no cloud changing. Right? You superimpose the notion of cloud on a series of related cloud values.

여기 규칙이 있습니다. 다시 말씀드리지만, 저는 화이트헤드를 다시 인용하는 것이 아닙니다. 제가 지금 지어낸 이야기입니다. 알겠죠? 실제 실체는 불변합니다. 그렇죠? 새로운 것이 있을 때 그것은 방금 말씀드린 과거의 순수한 기능적 의미에서 함수입니다. 따라서 미래는 과거와 과정의 함수이며 과정이라는 개념은 과거로부터 미래를 창조하는 것입니다. 정체성은 정신적 구성물입니다. 알겠어요? 우리는 그것을 구름이라고 부르기도 하고, 강이라고 부르기도 하고, 프레드라고 부르기도 합니다. 매우 유용한 심리적 인공물입니다. 그래서 우리가 객체 지향 언어를 사용하는 겁니다. 이것은 우리에게 유용합니다. 사물을 이해하는 데 도움이 되니까요. 하지만 객체는 시간이 지나면서 변하는 것이 아니라는 점을 이해해야 합니다. 그렇죠?
우리는 시간이 지남에 따라 관찰한 일련의 값에 객체를 겹쳐 놓습니다. 그것이 바로 객체입니다. 따라서 인과관계를 이해하는 것이 중요하기 때문에 이런 식으로 생각하는 것이 좋습니다. 사자, 사자, 사자, 사자, 사자... 끊어야겠어요. 그렇죠? 그렇다고 사자가 변한다는 뜻은 아닙니다. 없어 그리고 시간은 엄밀히 말해서 이 일련의 사건들에서 파생된 거야. 알겠지?
So, here are the rules. Again, I am not restating Whitehead. I’m making this up now. Okay? Actual entities are immutable. Right? When you have a new thing, it’s a function in that pure functional sense that I just talked about of the past. So the future is a function of the past and processes and the notion of process is what creates the future from the past. Identities are mental constructs. Okay? We call it a cloud, we call it a river, we call him Fred. It’s an extremely useful psychological artifact. That’s why we have object-oriented languages. This is useful to us. It helps us understand things. But we have to make sure we understand that objects are not things that change over time. Right?
We superimpose object on a set of values we saw over time. That’s an object. So just because we like to think of it this way, because it’s important to us to understand the causality. You know, lion, lion, lion, lion, lion… I better go. Right? That doesn’t mean there is a lion that’s changing. There isn’t. And then, time then is strictly, again, a derivative of this series of events. Okay?

화이트헤드의 훌륭한 인용문은 매우 혼란스럽지만, 지금 바로 이해하려고 노력하고 계속 진행하면서 기억할 수 있는 것은 연속성이라는 것입니다. 그렇죠? 우주에는 연속적인 가치를 창출하는 과정이 있습니다. 그렇죠? 그래서 우리는 "아, 연속성이라고? 대단하네요." 그 반대가 아닙니다.
So Whitehead’s great quote, which is extremely confusing, but I think it’s something that you could try to get right now and remember as I keep going, is that there’s a becoming of continuity. Right? There’s this process in the universe that’s creating successive values. Right? And that allows us to say, “Oh, continuity? Great.” It’s not the other way around.
# 용어 - 가치, 정체성, 상태, 시간

이제 우리는 화이트헤드의 용어에서 완전히 벗어났습니다. 그는 자신만의 용어를 많이 가지고 있습니다. 하지만 이 문제의 나머지 부분에 대해 이야기할 때 제가 사용하고 싶은 용어는 다음과 같습니다. 첫 번째는 "가치"라는 개념입니다. 우리는 가치에 대한 아주 적절한 개념이 필요합니다. 그렇죠? 우리는 "42"라고 말할 때 가치에 대한 적절한 개념을 가지고 있는 경향이 있습니다. 날짜에 대해 이야기할 때 우리는 가치에 대한 개념이 훨씬 약합니다. 따라서 가치의 핵심 특성은 불변이라는 것입니다. 아시겠어요? 크기일 수도 있고, 그런 것일 수도 있고, 불변하는 것들의 복합체도 가치입니다. 이런 것들은 우리에게 매우 중요합니다. 그렇죠?
그리고 "정체성"이 있습니다. 정체성은 다시 말하지만 심리적 구성 요소입니다. 우리는 인과관계가 있는 일련의 가치들을 보게 될 것입니다. 그렇죠? 하나는 이전 가치에서 비롯된 것이고, 다른 하나는 이전 가치에서 비롯된 것입니다. 그리고 우리는 프레드라고 말할 것입니다. 프레드는 다시 말하지만 레이블입니다. 그렇죠? 중요한 것은 이 정체성이며, 이는 시계열을 수집하는 데 사용하는 구조일 뿐입니다.
'상태'는 변경할 수 있는 것이 아닙니다. 상태는 스냅샷입니다. 이 엔티티는 이 시점에 이 값을 가지고 있습니다. 이것이 상태입니다. 따라서 변경 가능한 상태라는 개념은 의미가 없습니다. 변경 가능한 객체는 의미가 없습니다.
마지막으로 "시간"이 있습니다. 시간은 완전히 상대적인 개념입니다. 시간은 이 일이 저 일의 이전 또는 이후 또는 같은 시점에 일어났다는 것만 알 수 있습니다. 알겠죠? 측정할 수 있는 것이 아닙니다. 차원이 없습니다.
So now we’re completely out of Whitehead terms. He has a whole bunch of his own terms. But these are the terms I want to use to talk about the rest of this problem. The first is the notion of a “value.” We need a very proper notion of a value. Right? We tend to have a decent notion of a value when we say “42.” We have a much weaker notion of a value when we talk about dates. So the key characteristic of a value is that it’s immutable. Okay? It could be a magnitude, it could be something like that, or any composite of those things that’s also immutable is a value. These are extremely important to us. Right?
Then we have “identity.” Identity, again, is the psychological construct. We’re going to see a succession of values whose causation is related. Right? One was caused from the previous that was caused from the previous. And we’re going to say Fred. Fred, again, is a label. Right? The important thing is this identity, which is just a construct we use to collect the time series.
A “state” is not something you can change. The state is a snapshot. This entity has this value at this point-in-time. That’s state. So, the concept of mutable state, it makes no sense. Mutable objects, they make no sense.
And finally, we have “time.” Time is a completely relative thing. All time can ever tell you is this thing happened before or after that other thing or at the same point. Okay? It’s not a measurable thing. It doesn’t have dimension.

이 모든 것이 다소 과장되게 들립니다. 왜 우리가 이 문제에 관심을 가질까요? 우리는 의사 결정을 내리는 프로그램을 만들려고 하기 때문입니다. 그렇죠? 우리 프로그램에는 논리가 있습니다. 변할 수 있는 강 위에 논리를 얹을 수는 없죠. 알겠어요? 값 위에만 논리가 있을 수 있습니다. 그렇죠? 그래서 안정적인 값이 필요합니다. 그리고 프로그램의 다른 부분으로부터 값을 수집해야 합니다. 안정적인 값을 봐야 합니다. 기억할 수 있어야 합니다. 그래서 저는 "인식"이라는 단어를 사용하고 있습니다. 지각은 엄청나게 복잡하고 해결되지 않은 정신적 현상이라는 것을 잘 알고 있습니다. 하지만 저는 방 전체를 관찰할 수 있기 때문에 '관찰'이라는 단어보다 '지각'이라는 단어를 더 좋아하지만, 지각은 실제로 개체를 구분하는 것과 같습니다. 조금 더 세밀하죠.
다른 한편으로는 정체성이 필요하다고 생각합니다. 객체지향의 매력은 유효하다고 생각합니다. 그렇죠? 우리가 항상 세상에 대해 생각하는 방식이기 때문에 중요하게 생각하죠. 프로그램을 작성하기 위해 세상에 대해 생각하는 방식을 완전히 바꿔야 한다면 제 삶은 힘들어질 거예요. 제가 세상에 대해 생각하는 방식에서 프로그램을 작성하는 방식으로 어떻게든 이어갈 수 있다면 더 쉬워질 거예요. 알겠죠?
하지만 시간을 낭비하고 지금 방식이 잘못되었다고 해서 더 쉬워질 수는 없습니다. 그래서 "아, 저 객체들을 이해했어. 알겠어."라고 생각하지만 그것은 옳지 않습니다.
This all sounds kind of highfalutin. Why do we care about this? We care about it because we’re trying to make programs that make decisions. Right? We have logic in our programs. You can’t have logic on top of rivers that can change. Okay? You can only have logic on top of values. Right? So we need stable values. And we need to collect them from other parts of our program. We need to see stable values. We need to be able to remember them. So I’m using the word “perceived.” I understand completely perception is an incredibly intricate and unresolved mental phenomenon. But I like it better than just “observe” because I can observe the entire room, but perception really is kind of that division into entities. It’s a little bit finer.
On the other hand, I do think we need identity. I mean, I think that the appeal of Object Orientation is valid. Right? We care about this because it’s the way we’re thinking about the world all the time. If I have to change completely the way I’m thinking about the world in order to write a program, my life is going to be hard. If I can somehow carry over from the way I think about the world something to the way I write my program, it will be easier. Okay?
But, we can’t screw up time and state the way we have and have it still be easier because it’s now wrong. So it looks, “Oh, I understand those objects. I understand,” but it’s not right.
그래서 저는 JavaOne에서 멋진 책인 Head First Java를 쓴 사람들이 이야기하는 멋진 강연을 보았습니다. 그 사람이 말하길 - 이름을 잊어버려서 죄송합니다 - 강연에 사자 슬라이드를 넣으면 사람들이 겁을 먹고 더 잘 받아들일 수 있을 거라고 했어요. 그래서 이 사자가 제 사자입니다.
[웃음]
자, 이제 이론적인 장황함을 프로그램 작성에 사용할 수 있는 수준으로 끌어내려 봅시다.
So I saw this great talk at JavaOne where the people wrote Head First Java, which is a fantastic book, talked about... Well the guy talked about – I forget his name, I’m sorry – you should put a slide of a lion in your talk because it will get everybody like scared, and then they’ll be more receptive. So, this is my lion.
[laughter]
Okay. So, let’s just try to like pull that theoretical mumbo jumbo down to something we can use to write programs.

가장 먼저 이해해야 할 것은 우리는 직접적인 인지를 통해 세상에 대한 결정을 내리지 않는다는 것입니다. 우리는 뇌를 탁자 위에 올려놓고 문지르지 않습니다. 프레드에게 문지르지 않습니다. 우리의 논리 체계와 실제 세계 사이에는 단절이 있습니다. 알겠어요? 살아있는 게 아니에요. 그렇죠? "기억을 볼 수 있다"는 생동감은 그런 식으로 작동하는 게 아니에요.
The first thing we need to understand is we don’t make decisions about the world by direct cognition. We don’t take our brains and rub it on the table. We don’t rub it on Fred. There’s a disconnect between our logical system and the actual world. Okay? It’s not live. Right? This whole liveness we have from “I can see memory,” that’s not how it works.

현실 세계에서는 할 수 없는 또 다른 일이 있죠? 현실 세계를 모델링하려면 이렇게 하면 안 돼요. 잠깐만요, 알았어요. 알았어요 우리는 세상을 멈출 수 없어요, 특히 관찰할 수 없어요. 알았죠? 하지만 우리는 항상 프로그램에서 무엇을 하나요? 멈춰요! 잠깐! 멈춰요! 잠깐만요! 모두가 세상을 완전히 통제하기 위해 세상을 멈추려고 해요. 우리가 더 많은 동시성을 가지게 되면, 그렇게 되지 않는 것이 우리에게 훨씬 더 쉬울 것이기 때문에 우리의 의도나 욕망 또는 최선의 바람에도 불구하고 진행될 세상에서 사는 법을 배워야 할 것입니다. 그렇게 될 것입니다. 우리는 이를 받아들이고 수용할 수 있을 때까지 우리가 원하는 수준의 병렬성과 동시성을 달성하지 못할 것입니다.
따라서 우리는 좀 더 주의 깊게 살펴볼 필요가 있습니다. 지각은 실제로 어떻게 작동할까요? 우리는 뇌를 문지르지 않습니다. 우리는 세상을 멈추지 않습니다.
The other thing we don’t get to do in the real world, right? If we’re going to model the real world, we don’t get to do this – Wait! Okay. Okay. We don’t get to stop the world, especially not to observe it. Okay? But what do we do in our programs all the time? Stop! Wait! Stop! Wait! Hold on! Everybody’s trying to stop the world so they can control it completely. As we get more concurrent, we’re going to need to learn to live in a world that’s going to proceed in spite of our intention or desire or best wishes that it would not because it would be a lot easier for us if it wouldn’t. It’s going to. We’re not going to achieve the degrees of parallelism and the concurrency we want until we can accept this and embrace it.
So we need to look more carefully. Well how does perception actually work? We don’t rub our brains on it. We don’t stop the world.

엄청나게 평행합니다. 그렇죠? 경기장에는 수만 명의 관중이 있고 모두 경기를 볼 수 있습니다. 그들은 "워, 워, 워! 어디 좀 보자"라고 말하지 않죠. 그들은 "잠깐만요! 사진 찍을게요." 그럴 필요가 없죠. 그렇죠? 사진을 찍고 게임을 계속할 수 있으니까요. 그렇죠?
그래서 첫 번째는 지각이 조정되지 않는다는 것입니다. 알겠어요? 엄청나게 평행합니다. 메시지 전달이 아닙니다. 알겠어요? 게임을 보고 싶어하는 사람과 게임 사이에 소통이 없습니다.
그래서 다시 한 번 살펴볼 수 있습니다. 현실을 조금이라도 들여다볼 수 있도록 현실을 모델링하려고 합니다. 어떻게 할까요? 웨트웨어는 어떻게 하나요?
It is incredibly parallel. Right? There's umpteen thousand people in the stadium, they can all watch the game. They don’t say, “Whoa, whoa, whoa! Let me look at you.” They’ll say, “Hang on! Let me take a picture.” They don’t need to. Right? They can take a picture and the game can keep going. Right?
So the first thing is perception is uncoordinated. Okay? It’s massively parallel. It is not message passing. Okay? There’s no communication between the people who want to see the game and the game.
So, we can again look again. We’re trying to model reality so we can look at reality a little bit. How do we do it? How does the wetware do it?
# 인지

결국 가장 먼저 깨달아야 할 것은 우리는 항상 과거를 고려하고 있다는 사실입니다. 우리는 현재를 인식하지 못합니다. 그렇죠? 빛의 전파가 있죠. 빛은 감각계에 도달합니다. 엄청나게 느린 속도로 뇌로 전달되죠. 어떤 결정을 내릴 때면 저는 과거를 사용하고 있습니다. 우리는 시간을 멈출 수 없기 때문에 항상 과거로 계산하고 있는 거죠? 우리는 세상을 멈출 수 없습니다. 그래서 세상은 절대적으로 계속됩니다.
순간적으로 보입니다. 여기 맨 앞줄에 있는 사람이 보이지만 그 사람은 떠날 수 있습니다. 그렇죠? 빛은 매우 빠르기 때문에 얼마나 많은 시간과 거리에 따라 달라집니다. 다시 말하지만 까다롭습니다. 전자처럼요. 우리가 지금 기억을 보고 있다고 생각하게 만듭니다. 하지만 실제로는 그렇지 않습니다. 그것은 항상 과거입니다. 우리는 항상 과거를 인식하고 있습니다.
우리의 감각 시스템을 살펴보면 알 수 있는 또 다른 사실은 감각이 매우 개별적인 사건에 초점을 맞춘다는 사실입니다. 아시겠어요? 우리에게는 화학 신호를 전달하는 뉴런이 있는데, 이 뉴런은 연속적일 수 있습니다. 그리고 우리는 연속적인 두뇌를 만들 수 있습니다. 그렇죠? 어떻게든 세상을 움직이는 물체처럼 생각한 거죠. 그리고 움직이는 것이 우리 뇌에 들어와서 모두 움직이고 있습니다. 알겠어요?
그거 알아? 우리는 그렇게 하지 않았어요. 진화는 그렇게 하지 않았어요. 왜? 그건 엉망진창이니까! 그렇죠? 고려하려는 모든 것이 이리저리 움직이면 논리를 수행할 수 없습니다. 그렇다면 우리의 뉴런은 무엇을 할까요? 뉴런은 무언가를 쌓아 올린 다음 "뿅!" 소리를 냅니다. 뉴런은 입력을 이산화합니다.
그 다음에는 무엇을 할까요? "와우! 동시에 10가지 일이 일어났어."라고 말합니다. 그렇죠? 그래서 우리는 일을 이산화합니다. 그리고 동시성을 좋아합니다. 우리에게는 동시성 감지기가 있습니다. 우리의 뇌는 그보다 낮은 수준에서 동시성을 감지합니다. 알겠어요?
그래서 당연히 스냅샷을 좋아하죠. 알겠죠? 스냅샷은 좋은 거예요. 우리가 생각하는 데 도움이 되죠. 가치와도 같죠.
Well it ends up that the first thing you have to realize is we’re always considering the past. We’re never perceiving the present. Right? There’s the propagation of light. It hits my sensory system. It’s an incredibly slow system that carries that to my brain. By the time I’m making the decision about anything, I am using the past. I am always calculating with the past because we are not able to impede time, right? We can’t stop the world. And so, the world is absolutely continued.
It seems instantaneous. I see the person in the front row here, but they could leave. Right? Depending on how much time and how much distance because light is pretty fast. Again, it’s like tricky. Like electrons. It makes us think that we’re looking at memory right now. But it’s really not. It’s always the past. We’re always perceiving the past.
The other thing to pick up from looking at our sensory system is the fact that they’re incredibly oriented around discrete events. Okay? We have neurons that carry chemical signals, which could be continuous. And we could have built brains that were continuous. Right? That somehow took the world and consider it like this moving thing. And the moving thing comes into our brain and it’s all moving around. Okay?
Guess what? We didn’t do that. Evolution did not do that. Why? Because that’s a mess! Right? You cannot do logic if everything you’re trying to consider is moving around. So, what do our neurons do? They build stuff up, and then they go, “Boing!” They discretize the input.
What’s the next thing that we do? We say, “Whoa! 10 things happened at the same time.” Right? So we discretize things. And then, we love simultaneity. We have simultaneity detectors. That’s where our brains are at a lower level. Okay?
So of course, we like snapshots. Okay? Snapshots are good. They help us think. They’re like values.

객체지향에서 우리가 한 또 다른 일은 메서드이며, 메서드는 사물을 읽고 사물을 인식하는 방법이자 사물을 실행하는 방법입니다. 사물을 실행하는 것과 사물을 인식하는 것은 완전히 다릅니다! 완전히 다르죠. 같은 구조에 있어서는 안 됩니다. 서로 다른 두 가지입니다. 그렇죠? 행동에는 다른 속성이 있기 때문이죠? 두 가지가 동시에 같은 것에 영향을 줄 수는 없습니다. 교대로 영향을 주어야 합니다. 우리가 세상을 이해하는 데 사용할 가치의 연속은 원자적인 것입니다. 원자적인 연속입니다. 쉽게 이해할 수 있도록 스레드로 그룹화했지만 실제로는 그런 방식이 아닙니다. 한 번에 한 곳에 일정량만 있을 수 있다는 사실을 확실히 이해합니다. 그리고 그 정보에 대해 조치를 취하려면 그 자리에 있어야 합니다. 따라서 행동은 순차적으로 이루어져야 하며 행동과 인식은 서로 다른 것입니다!
Another thing we’ve done in Object Orientation is Methods, and Methods are a way to read things and perceive things and a way to make things happen. Well, making things happen and perceiving things are completely different! They’re completely different. They shouldn’t be in the same construct. They’re two different things. Right? Because action has this other property, right? No two things can affect the same thing at the same time. We have to sort of take turns. That succession of values that we’re going to use to understand the world is atomic. It’s an atomic succession. And while we’ve grouped them into threads that helps make it easy to understand, that’s not actually that way. We certainly understand the fact that there can be only a certain amount of stuff in one place at one time. And when you’re trying to act on that stuff, you’re going to have to be there. So action has to be sequential and action and perception are two different things!
# 획기 시간 모델 (epochal time model)
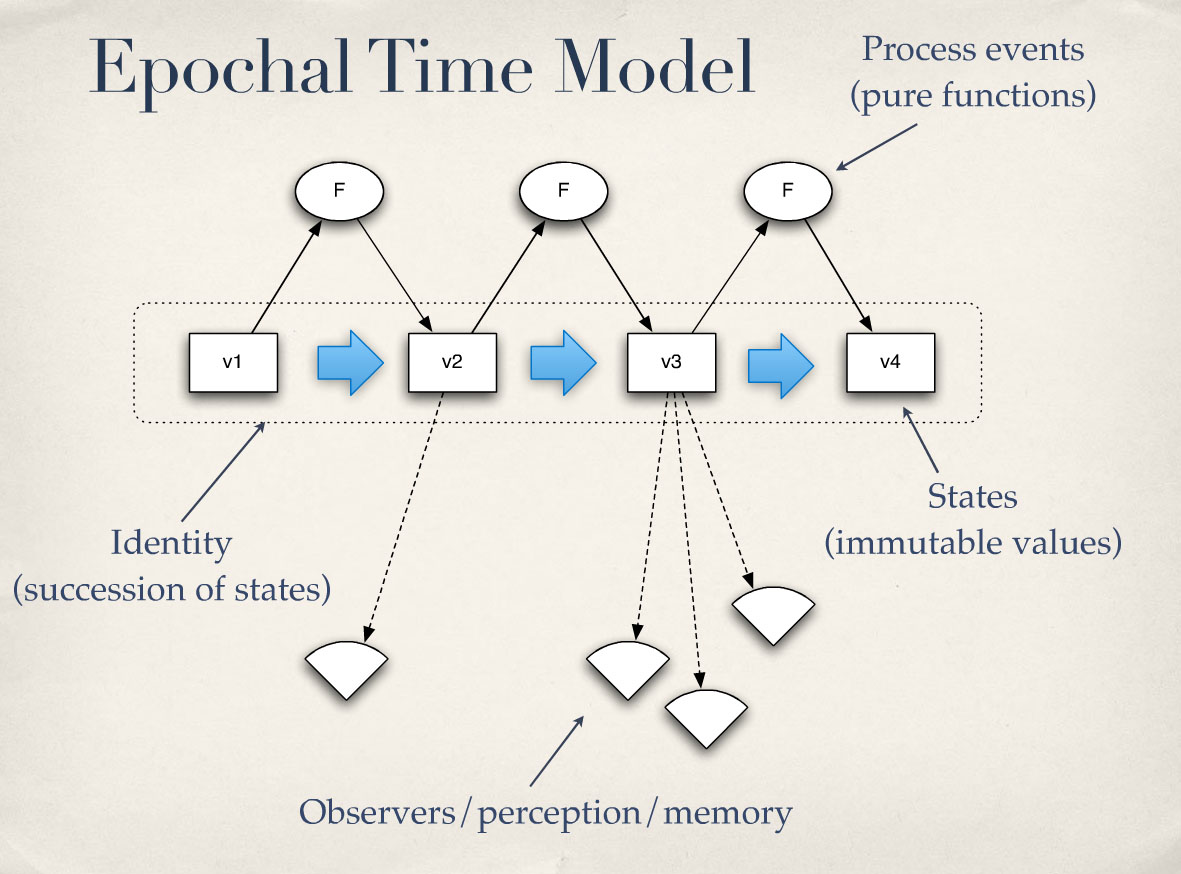
이제 이걸 올리려고 합니다. 나중에 다시 올릴게요. 이것은 모델입니다. 이것은 어떤 소프트웨어의 그림이 아닙니다. 이것은 시간에 대해 생각하는 방법에 대한 모델입니다. 가장 먼저 필요한 것은 값이 필요합니다. 시점이란 무엇인가요? 시점은 값이라고 말씀드렸습니다. 그렇죠? 값은 변경할 수 없습니다. 따라서 시점을 표현하기 위해 값을 사용하겠습니다.
우리는 여전히 아이덴티티별로 프로그램을 구성할 것입니다. 앞의 슬라이드를 기억하신다면 아이덴티티는 파생된 개념입니다. 무언가를 하는 것이 아닙니다. 그렇죠? 이 프로세스에서 파생된 개념입니다. 아이덴티티가 유용하기 때문에 우리는 여전히 사물을 정리하는 데 아이덴티티를 사용할 수 있습니다. 객체 지향은 우리가 프로세스를 이해하는 데 유용하다는 것을 보여주었습니다.
하지만 이 획기적이고 원자적인 연속적인 사건을 어떻게 헤쳐 나갈 수 있을까요? 함수를 사용하죠. 그렇죠? 우리는 과거의 함수를 가지고 미래를 만들어냅니다. 따라서 위에 있는 F는 순수한 함수입니다. 그렇죠? 함수는 우주의 상태를 취하거나 한 시점의 정체성의 상태를 취해 다음 상태를 생성합니다. 그 안에 있는 것은 나눌 수 없고 지각할 수 없습니다. 그것은 원자적입니다. 함수는 원자적입니다.
그리고 그것이 세상의 과정입니다. 그렇죠? 우리는 객체 지향 시스템에서 동작을 말합니다. "아, 나는 운전 중이야."라고 말하는 동작이 실제로 존재합니다. 그렇죠? 내가 이 일을 하고 있죠? 하지만 번개에 맞으면 누가 행동할까요? 행동은 없습니다. 하지만 세상에는 프로세스가 있고 그것이 사물에 영향을 미칩니다. 그게 바로 그런 기능입니다. 그렇죠?
엔티티 또는 아이덴티티와 관련된 이러한 기능 중 하나를 "상태"라고 부를 것입니다. 그렇죠? 다시 말하지만, 이는 특정 시점의 가치와 신원에 대한 레이블일 뿐이며, 우리는 이를 상태라고 부를 것입니다. 그리고 신원 자체는 다시 파생된 것입니다. 상태의 연속은 프레드 또는 강입니다.
여기서도 중요한 것은 사람들이 이것을 볼 수 있다는 것입니다. 그렇죠? 관찰자가 있을 수 있습니다. 빛은 강에서 반사될 수 있습니다. 빛이 프레드에게서 반사될 수 있습니다. 프레드는 그렇게 할 필요가 없습니다. 프레드가 저걸 운전할 필요는 없어요. 우린 그걸 볼 수 있어요. 그래서 우리는 사물을 관찰할 수 있습니다. 그리고 관찰자가 타임라인에 포함되지 않는 것이 매우 중요합니다.
그리고 저기 파란색 부분은 실제로 어디에도 통일되지 않습니다. 하지만 그것은 시간입니다. 다시 말하지만, 이것은 또 다른 파생된 것입니다. 따라서 모든 주를 둘러싼 상자, 그 정체성은 파생된 것입니다. 시간이라는 개념은 한 시점에서 이것을 보고 또 다른 시점에서 저것을 보았기 때문에 시간이 있다는 것을 알 수 있는 것입니다. 사물에 꼬리표가 붙는 것은 아닙니다. 오늘은 9월 22일이었습니다.
알겠습니다. 그럼 어떻게 해야 할까요? 이렇게 분해했다가 다시 조립하려면 어떻게 해야 할까요? 두 가지가 필요합니다. 아까 다이어그램에서 함수를 보았는데 순수한 함수입니다. 어떻게 해야 할지 알 것 같아요. 우리 모두 동의했듯이 우리는 순수 함수를 작성할 수 있는 기술을 가지고 있습니다.
So now, I’m going to put this up. I’ll put it up again later. This is a model. This is not a picture of some software. This is a model for how to think about time. The first thing we need is we need a value. What’s a point-in-time? We said a point-in-time is a value. Right? It can’t be changed. So we’ll use values to represent points in time.
We will still probably organize our programs by identities. As long as you remember the slide from before; that the identity is a derived notion. It isn’t a thing that’s doing stuff. Right? It’s a derived concept we get from this process. We can still use identities to organize things because that’s going to be useful to us. Object Orientation has shown us that’s useful for us to understand processes.
But, how do we get through these epochal, atomic, successive events? We use functions. Right? We take a function of the past, we produce the future. So the Fs on the top are pure functions. Right? They take the state of the universe or let's just say the state of an identity at one point-in-time and produce the next one. What’s inside them is indivisible, imperceptible. It’s atomic. The functions are atomic.
And that’s the process of the world. Right? We say behavior in object-oriented systems. There really is a behavior that says, “Oh, I’m driving.” Right? I’m doing this, right? But when you get hit by lightning, who’s behaving? There’s no behavior. But there are processes in the world and they affect things. So those are those functions. Right?
We’re going to call any one of those, relative to an entity or an identity, its “state.” Right? Again, it’s just a label of a value, of an identity at a point-in-time, we’ll call it state. And the identity itself again is a derived thing. The succession of states is Fred or the river.
The important thing also here is that people can be looking at this. Right? There can be observers. Light can bounce off the river. It can bounce off of Fred. Fred doesn’t need to do that. Fred doesn’t need to drive that. We can look at that. So we can observe things. And it’s very important that observers are not in the timeline.
And then, the blue stuff in there, it’s not actually reified anywhere. But that’s time. Again, it’s another derived thing. So the box around all the states, that identity is derived. The notion of time, it’s only because at one point, we looked at this, another point we looked at that, that we know that there is time. Things don’t come with labels. This was September 22nd.
All right. So how do we do this? If we wanted to take things apart like this and then put them back together, how are we going to do it? Well we’re going to need two things. We looked on the diagram before and we saw functions; pure functions. I think we know how to do that. Like we’re all agreed we have the technology to write pure functions.

이제 다이어그램에 두 가지가 더 남았습니다. 하나는 가치입니다. 다른 하나는 어떻게든 그 승계를 관리하는 것입니다. 그렇죠? 일종의 시간 구성이죠. 따라서 가치를 효율적으로 창출할 수 있는 방법이 필요합니다. 그렇죠? 저장하세요. 나중에 지각으로 사용할 수도 있으니까요. 그리고 가치의 연속을 조정할 수 있는 무언가가 필요합니다. 그렇죠? 그래서 시간 조정 구조라고 부르겠습니다. 그래서 우리는 그것들이 필요합니다.
결국 우리는 할 수 있습니다. 어쩌면 어떤 이론가가 시간을 모델링하기 위해 메모리를 소비해야 한다는 것을 증명할 수도 있습니다. 물론 가능합니다. 하지만 메모리 없이 할 수 있는 방법을 찾지 못했습니다.
그럼 어떻게 해야 할까요? 이전 값을 순수 함수에 전달하고 새로운 값을 비파괴적으로 생성한다고 가정해 봅시다. 그렇죠? 그러면 메모리가 약간 소모될 것입니다. 하지만 이를 통해 이 문제를 해결할 수 있습니다.
이러한 값은 우리의 지각으로 작용할 수 있기 때문에 다른 가치를 갖습니다. 그렇죠? 이 전체 시스템, 즉 전체 시각 시스템은 이러한 스냅샷을 만들기 위한 것입니다. 그렇죠? 프로그램이 - 물론 제 마음속의 스냅샷은 여기 시청자가 아닙니다. 서로 다른 두 가지입니다. 하지만 프로그램에서는 두 가지가 서로 다른 것이 아닙니다. 그렇죠? 프로그램에 가치가 있고 프로그램의 다른 부분이 그것을 인식하기를 원한다면 그들은 그것을 복사하고 싶어 할 것입니다. 그러면 정말 좋겠죠. 그들에게는 충분히 좋은 기록이 될 것입니다.
그래서 우리는 이러한 가치를 우리의 인식으로 사용할 수 있습니다. 그렇죠? 우리의 기억으로도 사용할 수 있습니다. 그렇죠? 우리 프로그램에서 무언가를 기억해야 하는 부분이 있다면 이 값도 그 목적에 부합할 것입니다. 따라서 가치를 수행하기 위한 좋은 시스템이 있다면 그렇게 할 수 있습니다. 그리고 아름다운 점은 시간을 모델링하기 위해 메모리를 사용한다면 GC가 더 이상 아무도 신경 쓰지 않는 과거와 기억을 지울 수 있다는 것입니다.
So that leaves us with two other things on the diagram. One was values. The other was somehow, we manage that succession. Right? Some sort of time constructs. So, we need a way to efficiently create values. Right? Save them. Maybe we’ll use them as percepts later. And we need something that’s going to coordinate the succession of values. Right? So we’ll call them time coordination constructs. So we need those.
It ends up that we can. And maybe some theoretician will prove we have to consume memory in order to model time. We certainly can. I don’t know that we need to, but I haven’t figured out a way to do without.
So what do we do? We say we pass the old value to a pure function, we produce a new value, nondestructively. Right? That’s going to consume some memory, and we know that. But that’s going to let us make this correct.
Those values have other value because they can serve as our perceptions. Right? What this whole system – the whole visual system is about making these snapshots. Right? When a program – I mean, admittedly, the snapshot in my mind is not the audience here. They’re two different things. But in a program, they’re not really two different things. Right? If you had a value in the program and another part of the program wanted to perceive it, they’d love a copy of it. That will be great. That’s a good enough record for them.
So we could use these values as our percepts. Right? We can also use them as our memories. Right? If we have a portion of our program that needs to remember something, this value would also serve that purpose. So if we have a good system for doing values, we can do that. And then, the beautiful thing is if we’re consuming memory to model time, GC will erase the past and the memories that nobody cares about anymore.
# 영속 데이터 구조

따라서 값을 처리하는 데 필요한 구조는 영속 데이터 구조입니다. 전에도 얘기한 적이 있습니다. 모르는 분이 계실지 모르겠지만, 여기서 말하는 것은 디스크에 저장할 수 있다거나 영구 데이터 구조가 불변이라는 것이 아닙니다. 그렇죠? 새 버전을 만들거나 변경하려고 하면 새로운 것을 얻게 됩니다. 이전 버전과 새 버전은 모두 만든 후에 사용할 수 있고 둘 다 동일한 성능 특성을 가지며 데이터 구조의 특성을 만들고 새 버전의 생산도 동일한 성능 특성을 갖습니다.
이것이 바로 간단히 이해하는(quickie) 영속 데이터 구조입니다. 그렇다면 어떤 장점이 있을까요? 특히 불변성이라는 점입니다. 아시겠죠? 따라서 기억과 인식 등 우리가 필요로 하는 목적에 매우 유용합니다. 스냅샷이 바로 그것입니다. 안정적이죠. 스냅샷의 또 다른 아름답고 실용적인 측면은 동기화가 필요하지 않다는 점입니다. 아시겠죠? 다시 돌아와서 야구 경기와 비슷하죠. 그렇죠? 좋네요! 19,000개의 메모리와 19,000명의 인식자가 있죠. 동기화가 없습니다.
영속 데이터 구조의 또 다른 좋은 점은 구현에 있습니다. 일반적으로 다음 버전의 값은 이전 버전과 많은 구조를 공유합니다. 따라서 더 효율적입니다.
또 한 가지 중요한 점은 새 값을 만들 때 이전 값을 보고 있는 사람을 방해하지 않는다는 것입니다. "잠깐만요, 멈춰요, 기다려요!"라고 말할 필요가 없습니다. 파괴하지 않더라도 아무것도 할 필요가 없습니다. 그리고 그것은 동기화로 돌아갑니다.
함수형 언어를 사용해 본 적이 없거나 비함수형 언어에서 영속 데이터 구조를 사용해 본 적이 없다면 제 말을 믿으셔도 됩니다. 이와 같은 데이터 구조를 사용하는 프로그램을 작성하면 밤에 잠을 잘 수 있고 더 행복해질 것입니다. 더 이상 걱정할 필요가 없는 것들이 엄청나게 많기 때문에 여러분의 삶이 더 나아질 것입니다.
So, the construct I think we need to do values is our persistent data structures. I’ve talked about them before. And if anybody doesn’t know, really quickly, we’re not talking about being able to put stuff on disk here or persistent data structure is immutable. Right? When you make a new version of it, when you try to change it, you get a new thing. Both the old and the new thing are available after you’ve made it and both have the same performance characteristics and they make the characteristics of the data structure and the production of the new version also has the same performance characteristics.
So that’s quickie persistent data structures. So what good are they? In particular, they’re immutable. Okay? So they’re great for the purposes that we need – memories and perceptions. Snapshots, essentially. They’re stable. Another beautiful, just practical aspect of them is they never need synchronization. Okay? Which is back – that’s just like the baseball game. Right? That’s good! There’s 19,000 memories there or 19,000 perceivers. No synchronization.
The other nice thing about persistent data structures is in their implementation. Generally, the next version of the value shares a lot of structure with the prior version. So that makes them more efficient.
The other thing that’s important is when we make the new value, we don’t disrupt anybody who’s looking at the old value. We don’t need to say, “Wait! Stop! Hang on!” Even if we’re not going to destroy it, we don’t need to do anything. And that goes back to the synchronization.
And if you have not ever used a functional language or ever used persistent data structures in a nonfunctional language, just take my word for it, this is so much better. If you write a program that uses data structures like this, you will just be able to sleep at night, you’re going to be happier. Your life is going to be better because there’s a huge quantity of things you will no longer have to worry about.

알겠습니다. 그래서 이 영구 데이터 구조는 [41:03:00] 관련되어 있습니다. 이건 오래됐어요, 정말 오래됐죠. 이 자료는 너무 오래되어서 여기에 올리기가 거의 부끄럽습니다. 그렇죠?
All right. So this persistent data structure [imperceptible 41:03] involved. This is old, this is really old. This stuff is so old, it’s almost embarrassing to put it up here. Right?
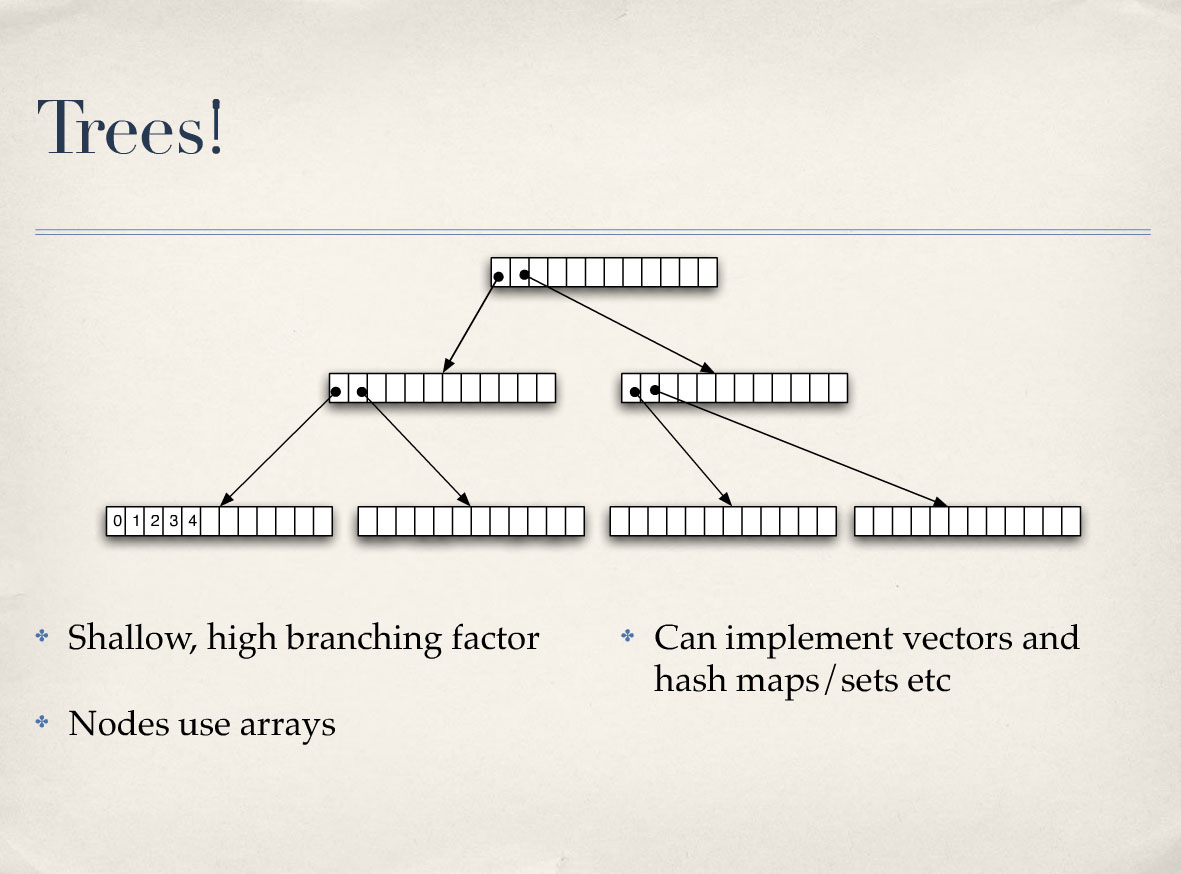
트리. 트리에는 구조를 공유하고 업데이트를 수행할 수 있는 속성이 있기 때문에 기본적으로 모든 영구 데이터 구조는 트리입니다. 특히 실용적인 측면에서 보면 몇 가지 속성을 가진 트리를 사용하여 벡터, 해시, 해시 맵 등 익숙한 것들을 구현할 수 있다고 생각합니다. 적어도 제 경험상으로는 그렇습니다. 하나는 분기 계수가 매우 높다는 점입니다. 따라서 매우 얕습니다. 그래서 좋은 성능을 제공합니다. 벡터를 구현할 수 있고 해시 맵을 구현할 수 있으며 여기서 할 수 있는 일의 세계는 여전히 열려 있다고 생각합니다. 하지만 결론은 모두 트리이며, 트리는 구조적 공유를 지원한다는 점에서 트리라는 것입니다.
Trees. And all the persistent data structures essentially under the hood are trees because trees have these properties that allow you to share structure and do updates. But in particular, I think from a practical sense, you can implement the kinds of things you’re used to having like vectors and hash, hash maps and things like that using trees with a couple of properties. At least this has been my experience. One is that they have very high branching factors. And so therefore, they’re very shallow. And that gives you good performance. You can implement vectors, you can implement hash maps and I think the world of things you can do here is still open. But the bottom line is they’re all trees and they’re trees for this reason – trees support structural sharing.
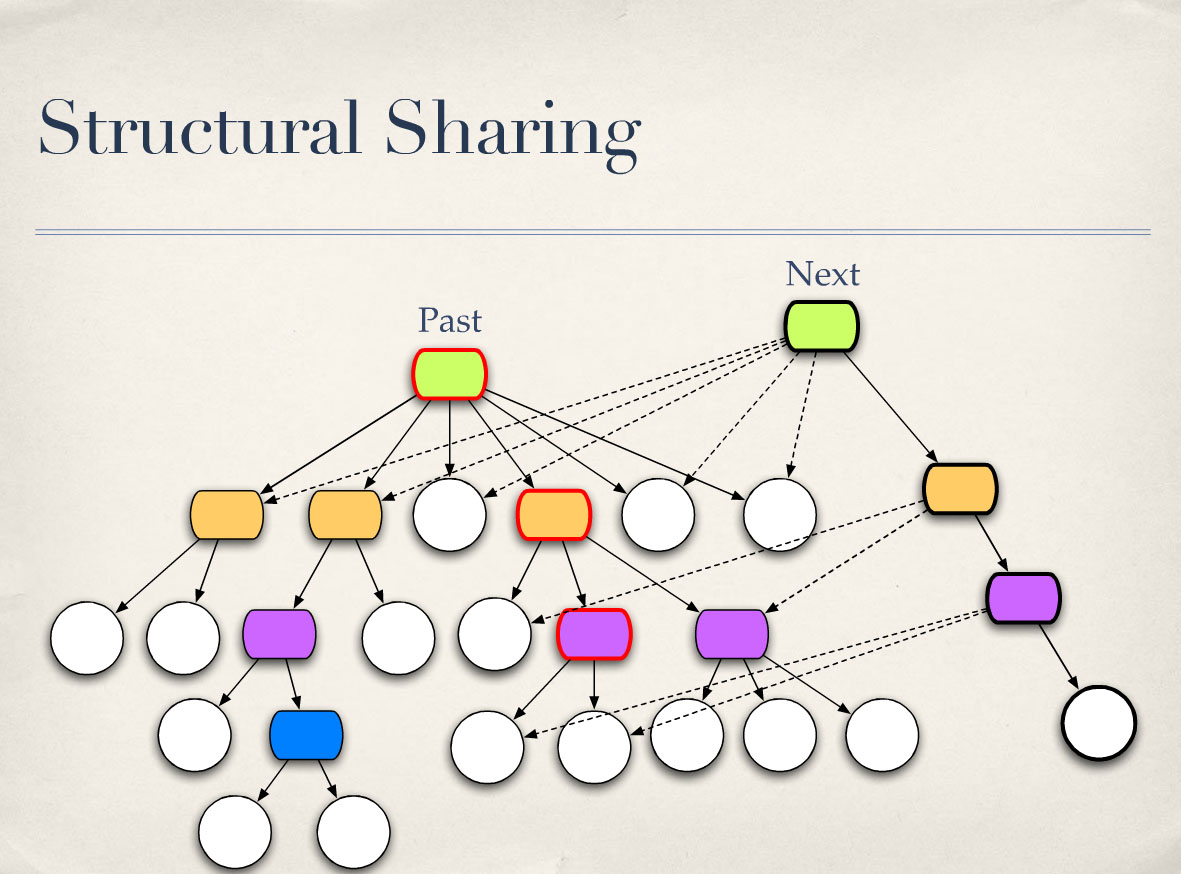
그래서 과거에 뿌리를 둔 나무는 불변합니다. 그렇죠? 절대 변경되지 않습니다. 새 노드를 추가하는 등 새 버전을 만들어야 할 때는 "경로 복사"라는 기능을 사용하게 됩니다. 그렇죠? 루트에서 변경해야 하는 노드까지 경로를 복사하는 것입니다. 그렇죠? 여기 오른쪽에 있는 것을 복사하세요. 이 새 복사본에는 우리가 원하는 새 노드, 즉 리프 노드가 있습니다. 그리고 새로운 루트가 생깁니다. 하지만 다음에 뿌리를 둔 새 트리는 빨간색 노드 세 개를 제외한 모든 것을 이전 트리와 공유합니다. 그래서 좋습니다.
So the tree rooted in the past there is immutable. Right? It’s never going to be changed. When we need to make a new version – say add a new node – we’re going to use something called “path copying.” Right? We’re going to copy the path from the root to the node we need to change. Right? So make copies of those over here on the right. Well, this new copy will have the new node we want; the leaf node we want. And we got a new root. But that new tree rooted at next shares everything with the old tree except those three red nodes. So that’s good.

앞으로 병렬화할 수 있는 프로그램을 만들려고 하면 루프 작성을 중단해야 합니다. 그렇죠? 병렬화를 통해 향후 성능 향상을 얻을 수 있다는 것은 완전히 별개의 이야기라는 것을 모두 이해하실 겁니다. 그렇죠? 그 말은 선언적 프로그램을 더 많이 작성해야 한다는 뜻이죠. 그렇죠? 그리고 이러한 선언적 프로그램은 데이터 구조를 가져와서 병렬 변환을 수행하여 새로운 데이터 구조를 생성할 수 있어야 합니다.
그리고 이 모델을 고수하려면 지속성이 있어야 합니다. 그렇죠? 그렇다면 이러한 영구 데이터 구조는 어떻게 이러한 목적을 달성할 수 있을까요? 바로 그거죠. 이미 분할과 정복이 이루어지고 있기 때문입니다. 작업의 절반은 이미 완료된 것이죠. 둘로 나뉘어져 있죠. 알겠어요? 미리 분할되어 있죠. 또한 제대로만 하면 충돌 없이 구성적인 방식으로 구성할 수 있습니다. 따라서 새 버전을 구축할 때 동기화를 피할 수 있습니다.
따라서 병렬 알고리즘을 수행하기에 매우 잘 설정되어 있습니다. 저는 영구 데이터 구조가 기본 데이터 구조가 되어야 한다고 생각합니다. 영구 데이터 구조가 기본 데이터 구조인 언어가 있었으면 좋겠어요.
Moving forward, as we try to make programs that we can parallelize, we have to stop writing loops. Right? I think everybody understands it’s a whole separate talk that we’re going to get our future performance gains from parallelization. Right? Which means we’re going to have to write more declarative programs. Right? And those declarative programs are going to need to be able to take data structures and do parallel transformations on them and produce new data structures.
And if we want to stick with this model, we want them to be persistent. Right? So how do these persistent data structures serve that purpose? Very well, it ends up. Because they’re already divide and conquer. I mean, half the work is already done. They’re sitting there divided. Okay? They’re pre-partitioned. In addition, if you do it right, you also have the ability to construct them in a compositional way without any collisions. So you can avoid synchronization in a building of the new versions.
So they’re pretty well set up for doing parallel algorithms. I think persistent data structures should be the default data structure. I wish there was a language where persistent data structures were the default data structure.

말하자면, 거짓말은 안 할게 그렇죠? 다들 "퍼포먼스 모델!" 같은 소리만 하잖아요. 더 느려요! 특히 연쇄적으로 사용할 때는 더 느려요. 특히 글쓰기에 더 그렇습니다. 읽기의 경우 성능이 얼마나 좋을 수 있는지 매우 놀랄 것입니다. 내가 보는 좋은 성능 중 일부는 완전히 이해하지 못하지만 거기에 있습니다. 읽기는 사실 꽤 견고합니다. 하지만 쓰기가 문제입니다. 경로 카피와 다른 모든 것이 있습니다.
하지만 저는 근본주의자가 아닙니다. 저는 실용주의자입니다. 그래서 F가 있다면요? 그리고 아무도 거기서 무슨 일이 일어나는지 볼 수 없다면요? 다시 말해, 불변하는 것을 취하고 불변하는 것을 생성하고 그것들이 두 개의 개별적인 시간 인스턴스이고 이것에 대한 다른 모든 것이 원자 적이라면 아무도 F 내부에서 무슨 일이 일어나는지 신경 쓰지 않습니다.
만약 그것이 큰 관련이 있다면 신경을 쓰겠죠. 정신 보존을 위해 순수 함수로 처리하고 싶을 수도 있습니다. 하지만 이번 시간 모델링에서는 원하는 대로 할 수 있습니다. 알겠죠? 즉, 영구 데이터 구조의 다음 버전을 만들 때 기존에 해오던 좋은 작업을 그대로 할 수 있다는 뜻입니다. 그렇죠? 배열을 할당할 수 있고, 아직 아무도 그 배열을 본 적이 없으므로 그 배열을 강타할 수 있습니다.
포크/조인을 사용할 수 있습니다. 그렇죠? 아주 잘 작동합니다. 그리고 이런 것들이 결국 격차를 해소할 것입니다. 이미 제 쿼드 코어에서 퍼시스턴트 벡터의 병렬 버전 맵은 ArrayList를 두드리는 루프만큼 빠릅니다. 같은 속도입니다. 따라서 코어가 더 많아지면 이기기 시작합니다. 다른 모든 장점도 있습니다. 이 퍼시스턴트 데이터 구조에는 동기화가 필요하지 않습니다. 원하는 만큼 공유하세요. 안심하세요. ArrayList에는 없는 모든 이점이 함께 제공됩니다.
또 다른 가능성은 이러한 영구 데이터 구조의 임시 버전이라고 부르는 것을 만들 수 있다는 것인데, 제가 최근에 작업하고 있는 임시 버전은 현재 사용 중인 기존 데이터 구조와 거의 동일한 속도를 제공합니다. 특히 영구 데이터 구조에서 상수 시간 생성과 영구 데이터 구조로 상수 시간 복원을 지원하며 안전하게 만들 수 있습니다. 가변적인 것에 비해 90% 정도 빠릅니다.
따라서 당연히 관심을 가져야 할 부분입니다. 다른 한편으로, 여러분이 이것을 두려워한다고 해서 이 모델의 힘을 부정하지는 않을 것입니다.
지금까지 가치에 대해 설명했습니다. 이제 시간에 대해 이야기할 때 무엇을 말하는지 기억하기 위해 시간 모델을 다시 한 번 살펴봅시다. 알겠죠?
Okay. I mean, I’m not going to lie to you. Right? Everybody's like "performance models!" and everything else. They’re slower! They are slower, especially for serial use. And especially for writing. For reading, you will be very much surprised at how good the performance can be. Some of the good performance I see, I completely do not understand, but it’s there. Reading is actually pretty solid. Writing though is a problem. You have that path copy and everything else.
But, I am not a fundamentalist. I’m a pragmatist. So if there’s this F, right? And if no one can ever see what happens there, right? In other words, if it’s going to take something immutable and it’s going to produce something immutable and those are two discrete instances of time and everything else about this is atomic, then nobody cares what happens inside F. Okay?
You probably do care if it’s a big involved thing. You probably still want to do it with pure functions for sanity preservation reasons. But for this time modeling reason, you can do whatever you want. Okay? Which means that when you’re birthing the next version of a persistent data structure, you can do the same old good stuff you know how to do. Right? You can allocate an array and you can bash on it because no one has yet seen that array.
You can use Fork/Join. Right? It works great. And these things will eventually bridge the gap. Already, on my quad-core, a parallel version of map on a persistent vector is as fast as the loop that bangs on an ArrayList. The same speed. So more cores, we start winning. Because, we have all these other great benefits. No synchronization required for this persistent data structure. Share it all you want. Rest easy. It comes with all those benefits that ArrayList doesn’t.
The other thing that’s possible is you can make what I call transient versions of these persistent data structures, and that’s something I’ve been working on recently, which have nearly the same speed of the good old data structures we’re using. And, in particular, support constant time creation from a persistent data structure and constant time restoration as a persistent data structure and can be made safe. They’re like 90% as fast as a mutable thing.
So, obviously, this is something you should care about. On the other hand, I wouldn’t deny the power of this model because you’re afraid of this.
Okay. So that’s about values. Now, let’s look at the time model again to remember what we’re talking about when we talk about time. Okay?
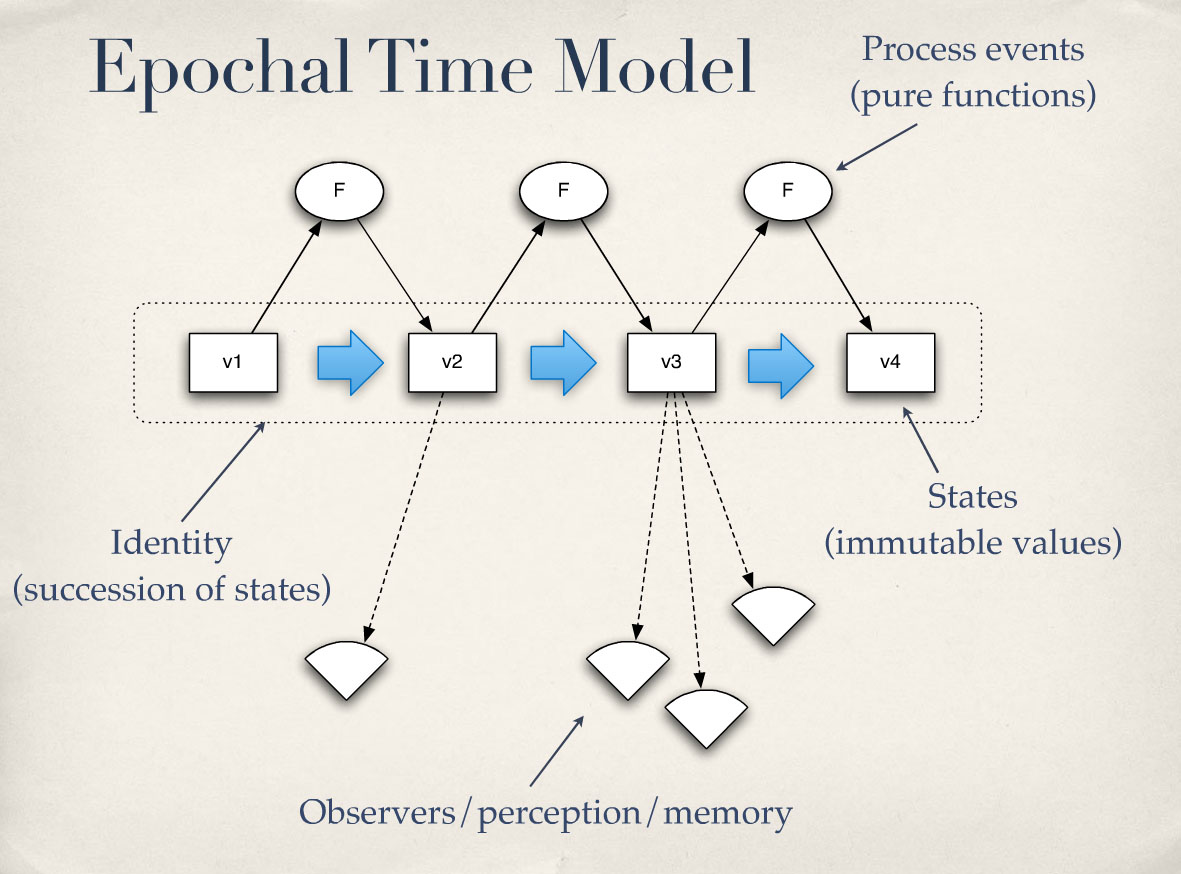
이제 V가 무엇인지 알았다고 말씀드렸습니다. V는 영구적인 데이터 구조가 될 것입니다. 그렇죠? 그렇다면 특정 신원에 대해 파란색 화살표 열차가 하나만 있는지 어떻게 확인할 수 있을까요? 시간을 어떻게 조정할까요? 다시 한 번 강조하지만, 아이덴티티는 부작용입니다. 그렇죠? 나중에 알게 되겠죠. 시간도 마찬가지입니다. 나중에 알게 되죠. 하지만 프로그램에서 모델링할 때 우리가 앞으로 나아가는 척하는 것이 우리에게는 편리합니다.
So we just said we now know what the Vs are. They’re going to be these persistent data structures. Right? So how do we make sure that there’s only one blue arrow train for any particular identity? How do we coordinate time? Again, remember, identity is a side effect. Right? We see that later. The same thing with time; we see that later. But it’s convenient to us when we’re trying to model in our program to pretend we’re driving it forward.

그렇다면 시간 구조체는 어떤 역할을 할까요? 시간 구조의 주요 역할은 값의 원자적 연속을 보장하는 것입니다. 아시겠어요? 한 값에서 다른 값으로 썩지 않고 계속 이어지도록 하는 것이 시간 구조의 주요 목적입니다. 그리고 그 사이에는 어떤 중간도 존재하지 않습니다. 그렇죠? 그게 바로 획기적이라는 뜻입니다. 그렇죠?
시간 구조가 해야 할 또 다른 일은 우리가 정체성을 볼 수 있는 방법, 즉 관리 대상을 볼 수 있는 방법을 제공해야 한다는 것입니다. 가시성을 제공해야 합니다. 그리고 다시 말하지만, 원자 단위로 이를 수행해야 합니다. 그렇죠? 실제로 일어나는 일은 야구 경기니까요. 그리고 광자가 있습니다. 그런 다음 특정 시점이 있고 광자는 야구 경기와 같은 위치에 있습니다. 그런 다음 다시 각자의 길을 갑니다. 그렇죠? 그래서 그런 것들이 서로 연결될 수 있는 순간이 있었지만, 그 순간을 스냅샷으로 표현한 것입니다. 다시 말하지만, 특정 시점의 가치입니다. 따라서 이를 제공해야 합니다.
우리는 여러 타임라인을 원합니다. 다시 말하지만, "내가 프로그램이다. 내가 우주를 통제한다. 내가 모든 것을 멈추거나 나만이 유일한 존재다"라는 생각은 더 이상 통하지 않습니다. 우리는 많은 제어 스레드가 필요하며, 이는 여러 타임라인이 필요하다는 것을 의미합니다.
이 모든 것의 좋은 점은 여기에 내재된 의미가 없다는 것입니다. 이 두 가지 사항을 준수하는 것 외에도 다양한 의미를 적용할 수 있습니다. CAS를 사용할 수 있는데, 이는 기본적으로 ID당 하나의 타임라인이 있다는 것을 의미합니다. 그렇죠? 그리고 그것은 조정되지 않습니다. CAS 타임라인을 사용하는 두 가지를 조정하는 것은 불가능하지만 CAS 타임라인은 여전히 유용합니다. 이해할 수 있는 의미가 있기 때문입니다.
일대일인 에이전트 또는 액터 시스템도 있습니다. 엔티티당 하나의 타임라인이 있으므로 조정할 수 없습니다. 하지만 비동기식이기 때문에 이벤트를 실행하는 사람의 타임라인과 연결되지 않습니다.
타임라인을 조정할 수 있는 STM 같은 것이 있습니다. 그리고 잠금을 기반으로 하는 새로운 구조도 있을 수 있습니다. 그렇죠? 잠금을 "타임라인을 강제하는 방법"이라고 볼 수 있기 때문입니다. 확실히 타임라인을 강제하는 방법입니다. 이를 자동화하여 이러한 시간 구성 중 하나로 패키징할 수 있는 방법이 있다면 정말 좋은 일이고, 그렇게 해야 합니다. STM과의 차이점은 아마도 임의의 영역을 갖는 STM과 달리 고정된 영역을 갖는다는 점일 것입니다. 하지만 "이 모든 타임라인은 실제로는 타임라인 X입니다."라고 하면 X는 자물쇠로 표현될 수 있습니다. 그리고 자물쇠 획득 순서를 보장하는 일종의 시간 구조가 있다면 이 게임을 할 수 있습니다.
So what does a time construct do? Its main job is to make sure that you have atomic succession of values. Okay? That’s its main purpose; that we go from one value to another, incorruptibly. And that there’s no in-between. Right? That’s what epochal means. Right?
The other thing that time construct has got to do is it’s got to provide some way for us to see the identity; to see the thing that it’s managing. It has to provide visibility. And again, it has to do that atomically. Right? Because what really happens is the baseball game, right? And there’s photons. And then, there’s a point-in-time and the photons are the same place the baseball game is. Then they go their own separate ways again. Right? So there was a moment there where those things could connect to each other, but what was represented was that snapshot. Again, a value at a point-in-time. So they need to provide that.
We want to have multiple timelines. Again, this whole “I am the program. I control the universe. I am stopping everything or I’m the only thing,” that isn’t working anymore. We need to have lots of threads of control, which means we want multiple timelines.
The nice thing about this whole thing is that there’s no inherent semantics to this. Other than complying with these couple of points, there’s a variety of different semantics you can apply. You can use CAS, which is essentially saying there’s one timeline per identity. Right? And it’s uncoordinated. It’s impossible to coordinate two things that are using CAS timelines, but CAS timelines are still useful. They have semantics you can understand.
There are agents or actor systems which are also one-to-one. There’s one timeline per entity so they can’t be coordinated. But they’re asynchronous so that they’re not connected to the timeline of the person enacting the event.
There are things like STM which allow you to coordinate timelines. And maybe even there can be new constructs based around locks. Right? Because you can look at locks as saying, “Well, that’s the way to enforce timelines.” It definitely is the way to enforce timelines. If you have a way to automate that and package it up into one of these time constructs, that’s great, and you should. The difference between them and STM would likely be that they have fixed regions as supposed to STM which has arbitrary regions. But if you said, “Well, all these timelines are really timeline X,” X could be represented by a lock. And if you have some sort of time construct that ensures lock acquisition order, you can play this game.
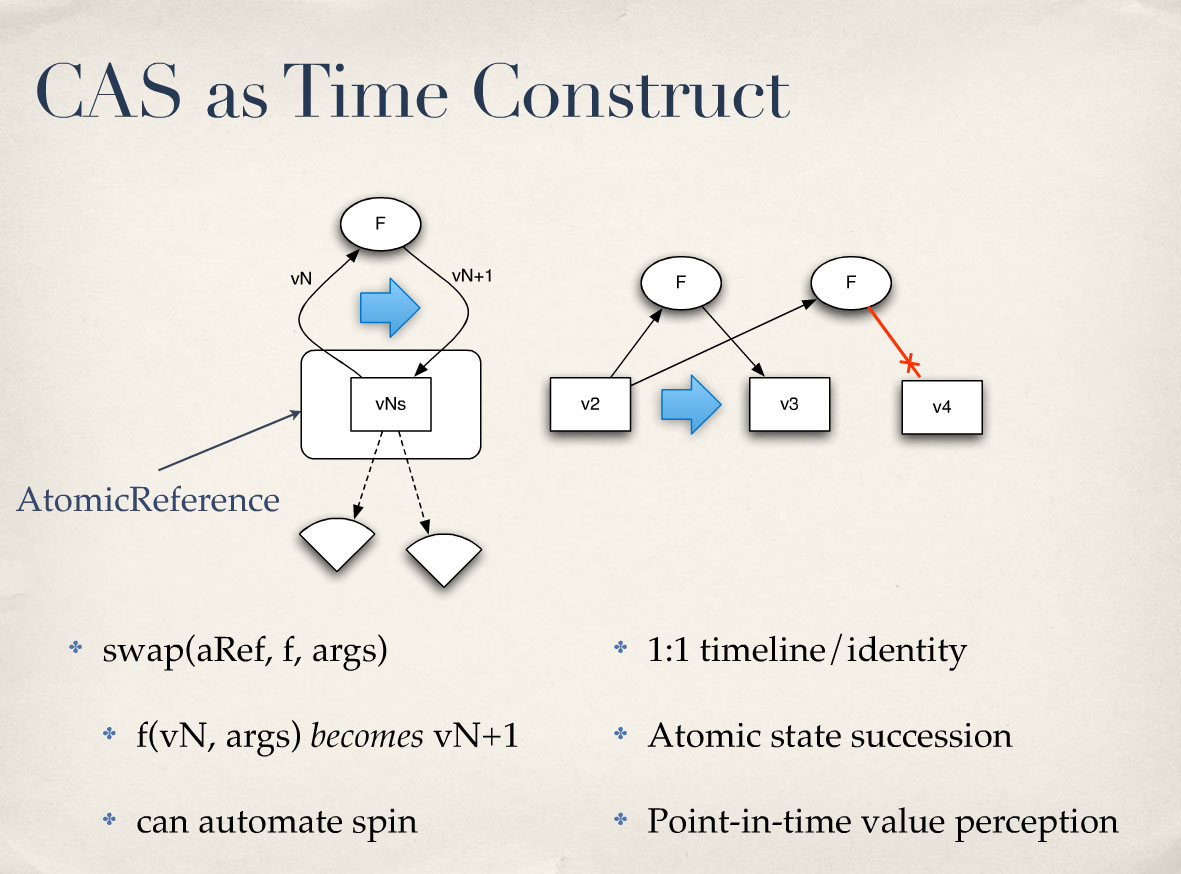
이제 CAS를 시간 구조로 살펴봅시다. 가장 쉬운 방법입니다. AtomicReference와 같은 CAS와 비슷한 것이 있죠? 이것이 타임라인을 저장할 것입니다. 그렇죠? 여기에는 히스토리가 없으므로 기본적으로 각각의 연속적인 값이 다른 값을 대체하게 됩니다. 하지만 우리가 신경 쓰는 것은 타임라인이 있다는 것입니다. 이 경우에는 타임라인이 있습니다. 하나의 정체성을 나타냅니다. 그 안에 있는 것은 항상 불변의 가치가 될 것입니다. 그렇죠?
CAS는 원자 상태 승계를 보장하죠? 만약 두 가지가, 두 개의 프로세스가 "나는 v2를 앞으로 나아갈 거야. 나는 그렇게 할 프로세스다"라고 결정하면 둘 중 하나만 성공할 수 있습니다. 그렇죠? 그래서 이 레드 라인은 CAS에 의해 방지됩니다. 그렇죠? 그리고 이 작업을 올바르게 수행하는 것과 관련된 로직을 CAS로 마무리할 수 있죠? 그게 바로 회전하는 것입니다. 그리고 그것을 구조체에 패키징하면 됩니다.
그러면 다음과 같이 보일 수 있습니다. 그렇죠? 이 함수를 사용하여 CAS 기반 참조를 일부 교체하면 과거의 함수가 됩니다. 아마도 몇 가지 추가 정보, 즉 인자를 추가할 수도 있습니다. 그리고 모든 시간 구조체에서 일어나는 일은 여기서 이 후자의 지점입니다. 현재 상태에서 함수를 호출할 것입니다. 원한다면 인자도 전달할 수 있습니다. 그러면 이렇게 되겠죠? 이것이 바로 구조체가 하는 일입니다. 이것이 다음 값이 될 수 있게 해줍니다. 시간은 거기서 파생됩니다. 정체성은 거기서 파생됩니다. 하지만 실제로는 그런 일이 일어나고 있습니다. 그래서 그렇게 보입니다. 그리고 내부적으로는 스핀을 자동화할 수 있습니다.
아토믹 레퍼런스가 허용하는 또 다른 기능은 내부에 무엇이 있는지 원자 단위로 살펴볼 수 있는 기능입니다. 그리고 그 안에 있는 것이 값인 한, 우리는 좋은 시점 인식을 할 수 있습니다.
So, let’s look at CAS as a time construct. It’s the easiest possible thing. So you have some CAS-like thingy like AtomicReference, right? That’s going to store your timeline. Right? There’s no history in it, which means essentially that each successive value will replace the other. But what we care about is that there is a timeline. In this case, there is. It represents one identity. The thing that’s in it, that’s always going to be an immutable value. Right?
CAS ensures atomic state succession, right? If two things, if two processes decide, “I’m going to move v2 forward. I am the process that’s going to do that,” only one of them can succeed. Right? So this red line, that will be prevented by CAS. Right? And you can wrap up the logic associated with doing that correctly with CAS, right? Which is that spinning thing. And just package it in the construct.
So it could look something like this. Right? Swap some CAS-based reference using this function, which will be the function of the past. Maybe plus some extra information; the args. And what happens in any time construct is this latter point here. You’re going to call the function on the current state. Also pass the args, if you want. And that will become, right? That’s what the construct does. It allows that to become the next value. Time is derived from that. Identity is derived from that. But that’s what’s really happening. So, it looks like that. And again, under the hood, we can automate the spin.
The other thing AtomicReference allows is the ability to atomically look at what’s inside of it. And as long as what’s inside of it is a value, we have good point-in-time perception.
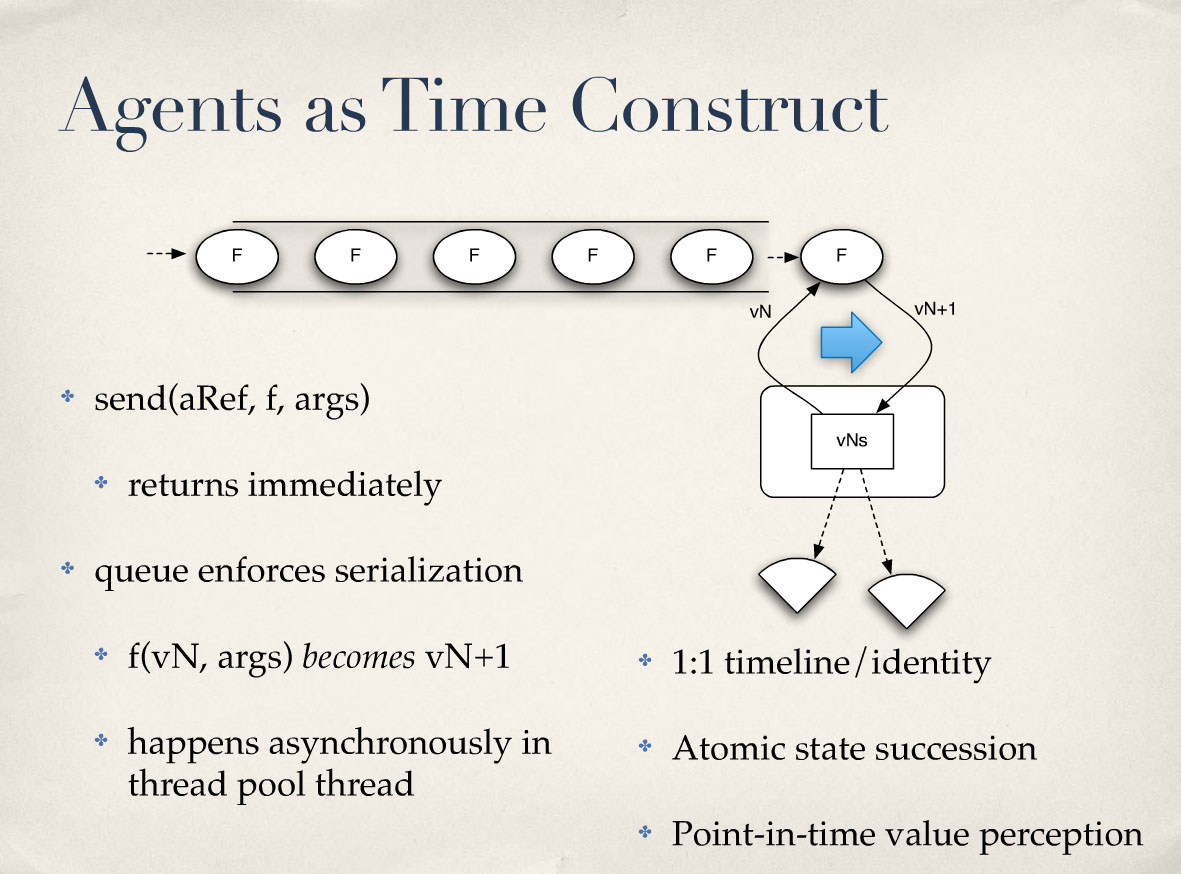
상담원에게 너무 많은 시간을 소비하고 싶지 않아요. 더 이상 조율이 없다는 점을 제외하면 CAS와 매우 유사합니다. CAS에서는 누군가 이 함수를 호출할 때, 누군가 "스왑!"이라고 말할 때 실제로 두 개의 타임라인이 존재합니다. 그렇죠? 조작하려는 신원의 타임라인이 있고 호출자의 타임라인이 있습니다. 각자의 타임라인이 있는 거죠. 그렇죠? 이 두 타임라인은 스왑에서 만나게 됩니다.
액터나 에이전트 시스템에서는 두 타임라인이 만나지 않죠. 그렇죠? 어떤 에너지의 힘을 시작하면 그 에너지가 그 대상을 향해 흐르고 당신은 그 대상에서 멀어집니다. 그리고 결국 그 에너지가 그 사물에 닿으면 어떤 결과가 나오든 그 사물은 변합니다. 그렇죠? 따라서 이제 발신자의 타임라인과 신원의 타임라인 사이에 비동기성이 생겼습니다. 하지만 그 외에는 여전히 동일한 작업을 수행합니다. 타임라인과 아이덴티티는 1:1 관계입니다. 그렇죠? 원자 상태 승계는 두 가지에서 발생합니다. 모든 것이 대기열에 놓여 있다는 사실에서 승계가 이루어지지 않습니다. 그리고 원자 상태는 읽는 사람이 한 명뿐이라는 사실에서 비롯됩니다.
또한 특정 시점의 가치 인식을 제공할 수도 있습니다. 제가 이러한 것들을 액터가 아닌 에이전트라고 부르는 이유는 액터는 일반적으로 그렇지 않기 때문입니다. 실제로는 그렇지 않습니다. 하지만 인프로세스 모델에서는 인식이 항상 지원되어야 한다고 생각합니다.
I don’t want to spend too much time on agents. They’re a lot like CAS, except that there’s no longer a coordination. In CAS, when somebody’s calling this function, when someone’s saying, “Swap!” there are actually two timelines. Right? There’s the timeline of the identity they’re trying to manipulate and there’s the caller. They have their own timeline. Right? Those two timelines meet at swap.
With an actor or an agent system, they don’t meet. Right? You initiate some energy force and it flows out towards that thing and you walk away. And eventually, that energy force hits that thing and whatever the results is the result and the thing changes. Right? So, there’s now an asynchrony between the caller’s timeline and the timeline of the identity. But otherwise, it’s still doing all the same work. It’s 1:1 relationship between the timeline and the identity. Right? Atomic state succession falls out of two things. The succession falls out of the fact that everything’s being put in a queue. And the atomic falls out of the fact that there’s only one reader.
And they can also provide point-in-time value perception. The reason why I call these things agents and not actors is actors typically do not. In fact, they definitely do not. But in an in-process model, I think perception should always be supported.

좋아요. 그렇다면 두 가지를 조율하면 어떻게 될까요? 아니면 두 가지 이상일까요? 이런 것들, 이런 CAS와 다른 것들은 작동하지 않을 것입니다. 그렇죠? 조율할 수 없으니까요.
All right. So what happens when you coordinate two things? Or more than two things? These things, these CASs and other things are not going to work. Right? Because you can’t coordinate them.

따라서 다른 무언가가 필요합니다. 소프트웨어 트랜잭션 메모리 또는 여러 임의의 영역의 활동을 조정할 수 있는 트랜잭션과 같은 것이 유일한 것은 아닐 것입니다. 따라서 여러 타임라인이 있습니다. 우리는 "좋아. 내가 호출하는 이 동작은 세 가지에 영향을 미칠 거야."라고 말할 수 있습니다. 즉, 어떻게든 타임라인이 맞아야 한다는 뜻입니다. 트랜잭션 기능도 있지만, 이 기능에는 별로 흥미롭지 않습니다.
하지만 가장 중요한 것은 우리가 획기적인 시간 모델에서 벗어나지 않는다는 것입니다. 이것은 여전히 획기적인 시간 모델입니다. STM 트랜잭션에 참여하는 모든 가치의 경우 여전히 동일합니다. 과거에 대한 어떤 함수가 미래를 생성하게 될 것입니다. 순수한 함수와 값이 들어오고 나가는 것이죠.
So you need something else. One possible other thing – it’s probably not the only one – is Software Transactional Memory or any kind of transactional thing which allows you to coordinate the activities of multiple arbitrary regions. So multiple timelines. We’re going to say, “Okay. This action I’m invoking is going to affect three things.” Which means somehow their timelines have to meet. They have transactional capabilities, which are not really interesting for this.
But the most important thing is we’re not walking away from the epochal time model. This is still the epochal time model. For any value that’s going to participate in an STM transaction, it’s still the same thing. You’re going to have some function on the past produce the future. A pure function and values in and out.
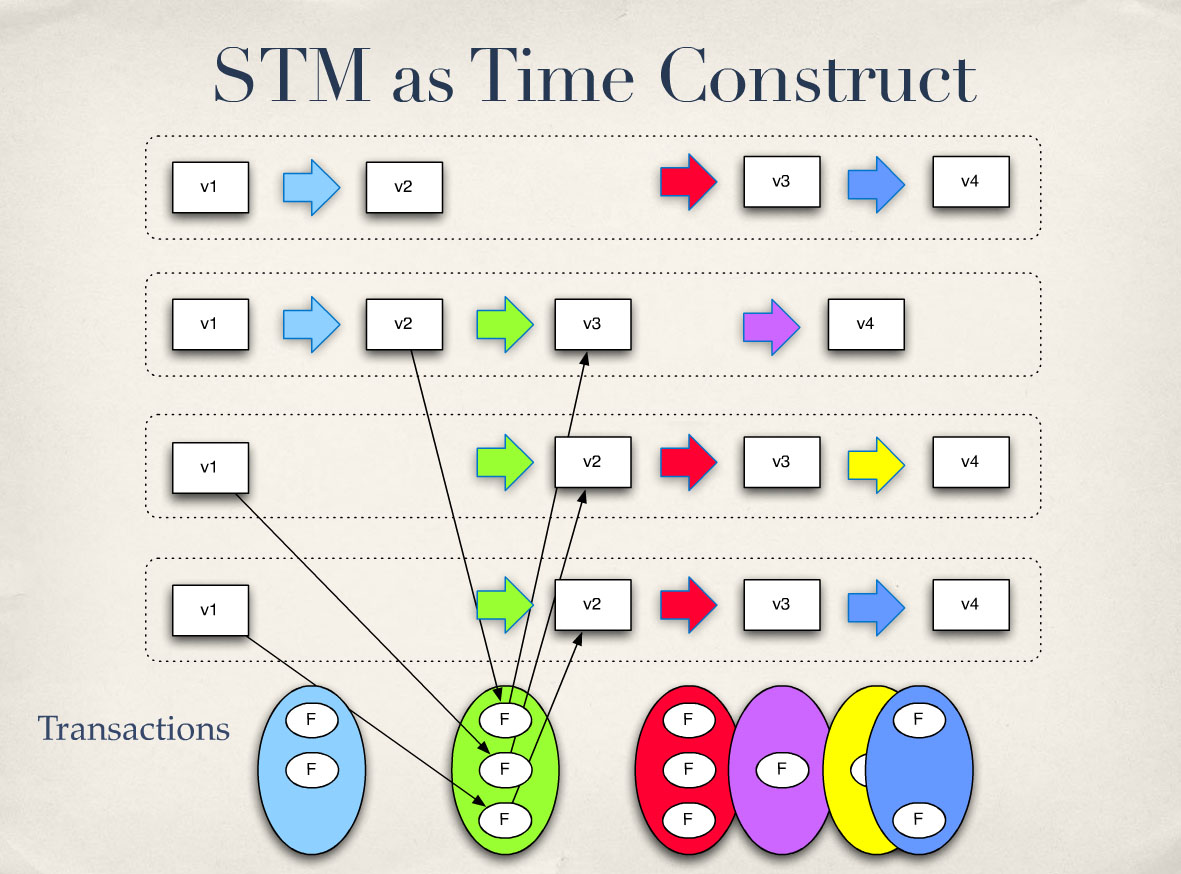
지금은 어떤 모습일까요? 여러 개의 신원이 있는 거죠? 잠재적으로요. 아니면 장소나 뭐든지요. 프로그램에 의미 있는 구조가 무엇이든 간에, 여러분은 여전히 그것을 가지고 있습니다. 그리고 특정 트랜잭션은 임의의 집합을 가져와 원자적으로 함수 변환을 수행합니다. 따라서 여러 개의 작은 마이크로 프로세스를 연결하여 하나의 프로세스로 만드는 방식입니다.
내부적으로는 각각이 이전과 똑같은 방식으로 작동합니다. 작동이 불가능할 것 같아서 화살표를 모두 넣었습니다. 그리고 트랜잭션 세트 자체가 타임라인처럼 느껴집니다. 특히 파란색과 노란색이 겹치지 않으면 기술적으로 동시에 발생합니다. 실제로는 시간이 없을 정도로 동시에 발생하죠? 이 두 가지 사이에는 연속성이 없기 때문에 시간이 없습니다. 겹쳐야 합니다. 앞서 말했듯이 시간은 한 가지 일이 연이어 일어나는 것에서 파생된 개념일 뿐입니다. 따라서 서로 관련이 없다면 물리학자들이 말하듯이 시간 개념은 정말 지저분해집니다.
So what does this look like now? There’s multiple identities, right? Potentially. Or places or whatever. Whatever construct is meaningful to your program, you still have that. And any particular transaction is going to take an arbitrary set of these and atomically do that function transformation. So it’s a way of connecting a bunch of little micro processes and making them one process.
Internally, each one works exactly the same way as before. I just put all those arrows because it would be unworkable. And the set of transactions themselves feels like a timeline. In particular, if blue and yellow don’t overlap, they technically happen at the same time. Really, they happen at times that – there’s no time, right? Because there’s no succession between those two things, there is no time. You’d have to superimpose it. Because we said, time only is a derived concept from one thing happening after another. So if they’re unrelated, it really gets messy about time, as physicists will tell you.
# Perception in (MVCC) STM
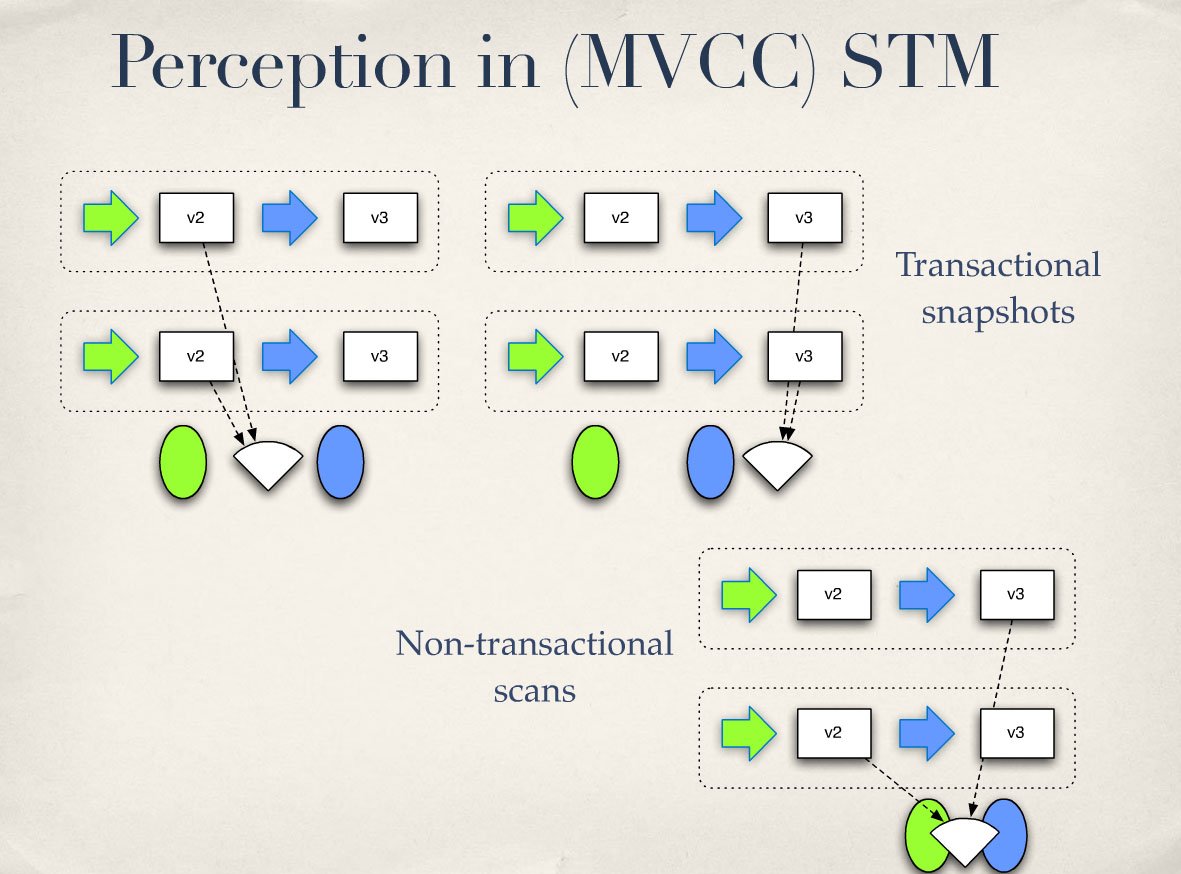
그래서 인식은 너무 지저분하기 때문에 여기서는 제외했습니다. 그렇다면 STM에 대한 인식 이야기는 무엇일까요? 경기장 전체를 한 번에 볼 수 있을까요, 아니면 여러 개체를 한 눈에 볼 수 있을까요? 결국 그렇게 할 수 있는 시스템을 구축할 수 있다는 결론이 나옵니다. 특히 다중 버전 동시성 제어를 사용하는 STM을 사용하면 가능합니다. 나중에 더 자세히 설명하겠지만 먼저 보여드리고 싶습니다. 그렇죠? 본질적으로 일어나는 일은 인식자가 있을 수 있다는 것입니다. 이 다이어그램에서 정말 중요한 것은 아직 타임라인에 표시되지 않았다는 점입니다. 이 상자에 누가 들어갔는지 인식하는 사람이 이렇게 많았던 적은 없었습니다. 그렇죠? 인식은 프로세스를 방해하지 않습니다. 이 두 가지를 함께 섞을 수는 없습니다.
따라서 실제로는 두 가지 이상의 원자적 이벤트와 관련하여 모든 인식은 트랜잭션 자체인 경우 완전히 하나의 이벤트 이후에 발생하거나 완전히 그 이전에 발생합니다. 그렇죠? 이것이 바로 STM이 제공하는 기능입니다.
트랜잭션이 아닌 스캔도 할 수 있습니다. 패닝할 수 있습니다. 경기장의 이 부분을 살펴보고 이쪽으로 가서 저 부분을 살펴볼 수 있습니다. 알겠죠? 또는 도로에 있는 자동차를 보고 구름을 올려다 볼 수도 있습니다. 여기 빨간 자동차를 보고 구름을 올려다 볼 수 있나요? 이쪽을 보면 빨간 차가 보이죠? 그렇죠? 하지만 그렇게 할 때 무엇을 알 수 있을까요? 저것도 같은 빨간 차일 수 있어요. 이렇게 패닝을 하면 특정 시점을 볼 수 없다는 것을 알 수 있습니다. 하지만 선택권이 있습니다.
그렇죠?
[청중] 모든 절차가 트랜잭션이 커밋되는 순서에 동의해야 한다고 생각하시나요, 아니면...?
그 얘기는 나중에 해야겠네요 [웃음].
[청중] 상대성을 어디까지 인정하고 싶으신가요, 일종의? 일반적인 메모리 연산에 대해서는 "아니요, 동의할 필요가 없습니다."라고 말할 수 있을 테니까요. 그렇죠.
아니요, 동의할 필요는 없습니다. 맞습니다. 하지만 여러 STM을 가질 수 있습니다. 그렇죠? STM은 일종의 작은 우주를 구성하기 때문입니다.
좋아요, 트랜잭션 보기는 살짝 보는 것과 같습니다. 비트랜잭션 보기는 스캔과 같은 것입니다.
So, I left perception out of this because this is too messy. So what’s the perception story for STM? Can we look at the whole stadium at one time or can we glance and see multiple entities? And it ends up that you can build systems that do that. In particular, an STM that uses multi-version concurrency control can do it. And I’ll explain that more later, but I just want to show it to your first. Right? Essentially, what happens is there can be perceivers. What’s really important about this diagram is they’re still not in the timeline. There’s never been so many perceiving who got up into this box. Right? Perception does not interfere with process. You cannot munge those two things together.
So, relative to these atomic events that are in fact more than one thing, any perception is either going to occur completely after one or completely before it if it’s transactional itself. Right? That’s what STMs provide.
You can still do a non-transaction scan. You can pan. You can look at this part of the stadium and then go over here and look at that. Okay? Or you can look at a car on the road and you can look up at the clouds. Can you see the red car here and look up at the clouds? You look over here and you see the red car. Right? But you know when you’re doing that, what? That may be the same red car. You’ve realized when you’re panning like that, you’re not seeing a point-in-time. But you have the choice.
Yes?
[Audience member] Do you think that all the procedures should agree on the order that transactions commit, or...?
We’ll have to save that [Laughs].
[Audience member] How far do you want to take relativity, kind of? Because you would say for just normal memory operations you’d probably say, “No, they don’t need to agree.” So yeah.
No, they don’t need to agree. They don’t. But you could have multiple STMs. Right? Because STM sort of constitutes a little universe.
Okay. So we have transactional viewing, which is like glimpsing. We have non-transactional viewing, which is like scanning.
# Multiversion concurrency control

따라서 이를 위한 한 가지 방법은 멀티버젼 동시성 제어를 사용하는 것입니다. 그렇죠? 이 모든 것은 오래된 것입니다. 그렇죠? 이것은 데이터베이스의 오래된 것들과 똑같습니다. 따라서 다중 버전 동시성 제어는 독자를 만족시키기 위해 일부 기록을 유지한다는 것을 의미합니다. 이것이 바로 데이터베이스입니다. 하지만 이 모델에서도 생각해 볼 수 있는 방법이 있죠? 다중 버전 동시성 제어의 가장 중요한 한 가지 속성은 독자가 작성자를 방해하지 않는다는 것입니다. 인식이 프로세스를 방해하지 않는다는 것입니다. 정말 중요한 기능입니다. 이 기능 없이는 불가능하다고 생각합니다. 제가 전에 보여드린 모든 것의 모든 타임라인 중간에 인식자를 집어넣으면 삶이 훨씬 더 복잡해질 것입니다. 야구 경기 그만해요! 그래서 우리는 그렇게 하고 싶지 않습니다.
그래서 이 모델링에서는 프로그램에서 실제 세계를 구현한다고 가정해 봅시다. 다중 버전 동시성 제어가 빛의 전파 또는 감각 지연을 모델링한다고 말할 수 있겠죠? 야구 경기에서 반사되는 빛이 어떻게든 우리에게 충분히 좋은 값을 포착하고 있다는 전체 사슬이죠. 전송 지연은 프로세스가 계속 진행되는 동안 해당 값이 전송되는 동안 어딘가에 있어야 하고 게임이 계속 진행되어야 한다는 것을 의미합니다.
그래서 저희는 기록을 보관하는 방식으로 이를 해결합니다. 흥미롭게도 영구 데이터 구조는 이러한 히스토리를 저렴하게 유지할 수 있게 해줍니다. 제가 이해하지 못하는 심오한 점이 있습니다.
다중 버전 동시성 제어의 또 다른 멋진 점은 독자가 타임라인에 대한 자신만의 개념을 가질 수 있다는 것입니다. "그때 이걸 봤어요. 그리고 나중에 저것을 봤어요." 이는 의사 결정에 매우 중요한 요소입니다. 실제로 우리의 뇌는 행동을 재구성할 때 바로 이 작업을 수행합니다. 방금 세기 시스템을 살펴봤습니다. 모든 것을 개별화하고 "스냅샷화"하는 것이죠. 좋아요, 하지만 사자가 나를 향해 달려오고 있다는 지각은 분명히 있죠. 그렇죠? 달리기, 우리는 그것을 다시 도출해야 합니다. 그리고 우리는 어떻게든 이전의 스냅샷과 이후의 스냅샷을 비교하여 그 차이를 보고 "달리는 사자"라고 말할 수 있는 정신적 프로세스를 통해 이를 수행합니다.
또한, 우리는 시각적 스캔의 차이를 알고 있으며, 우리가 무언가를 보았을 때 부주의하게 여기 다른 것을 보았을 때, 우리는 그것들을 상호 연관시켜 동시에 일어난다고 말할 수 없습니다.
So one way to do this is using multiversion concurrency control. Right? This is the same old – all these stuff is old. Right? This is the same old stuff from databases. So multiversion concurrency control means that you are keeping some history in order to satisfy readers. That’s the database thing. But there’s a way to think about it in this model as well, right? That very critically, one attribute, the key attribute of multiversion concurrency control is that readers don’t impede writers. The perception doesn’t impede process. That’s huge. I think you cannot do without that. Everything about everything I’ve shown you before, if you stick perceivers in the middle of those timelines, your life is going to get way more complicated. Stop the baseball game! So we don’t want to do that.
And so, in this modeling, let’s pretend we’re doing the real world in our programs. You could say that multiversion concurrency control models light propagation or sensory delay, right? That whole chain that if somehow the light bouncing off the baseball game is capturing its value good enough for us. That transmission delay means that that value has got to be somewhere while it’s being transmitted while the process keeps going, the game keeps going.
So we do this by keeping some history. Quite interestingly, and fortuitously, persistent data structures make keeping that history cheap. There’s something profound about that that I don’t understand.
The other cool thing about multiversion concurrency control is it allows readers to have their own notion of a timeline. “I saw this then. And then later, I saw that.” That’s really important to some decision-making. In fact, when our brain reconstructs behavior, that’s exactly what it does. We just looked at the century system. It’s discretizing and “snapshotizing” everything. Okay. But we definitely have percepts for the lion is running towards me. Right? Well running, we have to re-derive that; that running. And we do that by a mental process that somehow allows us to compare a snapshot from before to a snapshot we know is later and see the deltas of that and say, “Running lion.”
In addition, again, we know the difference between the visual scan, and we know when we’ve looked at something and we’ve carelessly looked at something else over here, we are not allowed to correlate those things and say they happen at the same time.

STM에 대한 이야기는 아니지만, 한 가지 꼭 알아두셨으면 하는 것은 STM은 서로 다르다는 점입니다. 하나의 STM은 없습니다. STM을 두들겨 패고 싶다면 하나를 골라 그 속성을 살펴보고 무엇이 잘못되었는지 알아보세요. 왜냐하면 제가 생각하기에 정말 시간을 잘못 맞추는 것도 있고, 여전히 시간을 잘못 맞추는 것도 있기 때문입니다. 그렇죠? 따라서 다중 버전 동시성 제어 기능이 없으면 시간적 관련성이 없는 스캔으로 제한될 수 있습니다. 이것도 보고 저것도 보고. 모르겠어요. 한 번에 두 가지를 동시에 볼 수 있는 능력이 없습니다. 아니면 정신이 나간 거죠. 그렇지? 다시 "잠깐!"으로 돌아갈 것입니다. "잠깐만요! 내가 중간에 인식을 할 수 있도록 프로세스를 중지하세요." 그렇죠? 멀티버젼 동시성 제어가 없다면 바로 이런 상황이 벌어집니다.
제가 생각하는 STM의 또 다른 중요한 점은 세분성이 중요하다는 것입니다. 아시겠죠? 강제로 STM을 사용하거나 STM을 잘못 사용하여 일관된 값을 보기 위해 트랜잭션이 필요하다면 또다시 시간을 낭비하고 있는 것입니다. 아시겠죠? 따라서 객체의 네 필드를 일관되게 읽기 위해 트랜잭션이 필요한 STM은 시간을 제대로 측정하지 못하는 것입니다. 이 문제를 제대로 해결하지 못합니다. 알겠어요?
So, this is really not a talk about STM, but I do think that one takeaway I’d really like you to have is that STMs are different from each other. There’s no one STM. If you want to beat up on STM, pick one, pick its attributes and find out what’s wrong with it because there are some that I think really get time wrong, still get time wrong. Right? So if you don’t have multiversion concurrency control, you either are going to be limited to scans, non-temporally related. I looked at this thing, I looked at that thing. I have no idea. I have no ability to look at two things at once. Or, you’re going to have some gook. Right? You’re going to be back to “Wait!” “Wait! Stop the process so I can get my perception in the middle of it.” Right? Without multiversion concurrency control, that’s where you are.
The other thing about STMs I think is super, super critical is that granularity matters. Okay? If you’re using an STM that forces you or you’re incorrectly using an STM and you find yourself requiring a transaction in order to see a consistent value, you have got time wrong again. Okay? So STMs that require a transaction to read four fields of an object consistently are not doing time right. They’re not really solving this problem. Okay?
# Conclusions

결론적으로 말하자면, 때때로 - 아니, 항상 - 지나친 복잡성으로 고통받고 있다면 무언가를 바꾸는 것에 대해 생각해야 한다고 생각합니다. 그리고 때때로 사람들은 실제로 변화합니다. 그렇죠? 가비지 수집이 거의 되지 않던 언어에서 가비지 수집이 가능한 언어로 바꾸는 이유는 암묵적인 복잡성이 줄어들기 때문입니다. 다른 이유는 없습니다. 알겠죠?
하지만 현재 객체 지향 언어의 상태에서는 행동과 시간, 정체성과 상태의 혼동으로 인해 우리의 삶이 훨씬 더 힘들어지고 있고, 점점 더 악화될 것입니다. 아시겠어요? 우리는 프로그램에서 시간에 대해 명확히 해야 합니다. 함수형 프로그래밍을 하는 사람들이 "순수 함수의 이 모든 훌륭한 속성을 보세요. 그것들이 바로 거기에 있습니다." 이는 화이트헤드의 "우리는 사물의 내부를 이해할 필요성을 제거함으로써 앞으로 나아간다"는 말을 확실히 충족시켜 줍니다. 아시겠어요?
저는 이 획기적인 시간 모델이 시도해 볼 가치가 있다고 생각합니다. 이것이 일반적인 모델이라고 생각합니다. 이 모델은 다양한 구현 아이디어를 지원하며 로컬 프로세스에서 작동할 것입니다. 저는 여기서 분산 컴퓨팅에 대해 전혀 이야기하고 있지 않습니다.
한 가지 더 말씀드릴 수 있는 것은 현재 우리가 가지고 있는 인프라가 구현을 위한 실험을 하기에 충분하다는 것입니다.
So, in conclusion, sometimes – I mean, all the time – I think if you’re suffering from excessive complexity, you got to think about changing something. And sometimes, people actually do change. Right? We move from languages that weren’t garbage-collected substantially to ones that are because that reduces our implicit complexity. There’s no other reason. Okay?
But, in the current state of object-oriented languages, this conflation of behavior and time and identity and state is just making our lives much, much harder, and it’s going to get worse. Okay? We need to become explicit about time in our programs. We really need to pay attention to the functional programming people who are saying, “Look at all these great properties of pure functions. They are there.” They definitely satisfy Whitehead’s “We move forward by taking away the need to understand the insides of things.” Okay?
I believe that this epochal time model is worth trying. I think it’s the general model. It supports multiple implementation ideas and it will work in the local process. I’m not here talking about distributed computing at all.
The other thing I can tell you is that the current infrastructures that we have are sufficient for experimenting with this for doing the implementation.

그렇다면 아직 해결되지 않은 문제는 무엇일까요? 글쎄요, 내부 시간을 외부 세계와 조정하는 것이 중요한 일이 될 것이며 이는 어려운 문제입니다. STM 트랜잭션을 트랜잭션 I/O에 연결하는 것은 매우 흥미롭고 가능한 일이라고 생각합니다.
하지만 전반적으로 트랜잭션성에서 벗어나고 싶을 것입니다. 트랜잭션성은 제어, 제어, 제어입니다. 여러분은 통제력이 부족해도 최대한 행복해지기를 원합니다. 그러면 더 많은 동시성을 얻을 수 있습니다.
항상 더 많은 병렬성이 있을 수 있습니다. 성능이 향상될수록 이러한 데이터 구조 내부에서 병렬 처리를 위해 더 많은 작업을 수행할 수 있습니다. 더 많은 데이터 구조와 더 나은 버전이 개발될 것이라고 확신합니다. 다른 시간 구조도 분명히 존재할 것입니다. 이 모델에서 잠금을 이동하는 것은 매우 흥미롭다고 생각합니다. 잠금에는 우리가 활용하고 싶은 몇 가지 특별한 효율성이 있고 이러한 측면에서 잠금을 이해할 수 있는 방법이 있기 때문입니다.
다른 모든 분들께 공개 질문으로 남겨두겠습니다. 객체지향과 이를 조화시킬 수 있는 방법이 있을까요? 객체에 대한 인식과 객체의 정체성을 충분히 분리하여 객체의 이점을 계속 누리면서도 나중에 엉망이 되지 않도록 할 수 있을까요?
이상입니다. 감사합니다.
[박수]
So what is still unresolved here? Well, coordinating this internal time with the external world is going to become an important thing and it’s a hard problem. Tying STM transactions to transactional I/O would be a very interesting, and I think, a possible thing.
Again, overall though, you want to move away from transactionality. Transactionality is control, control, control. You want to become as happy as you can with lack of control. That will give you more concurrency.
There always could be more parallelism. The more performance and there definitely could be more work done on parallelism inside these data structures. There are more data structures to be done, I’m sure, and better versions. There are definitely going to be other time constructs. I think moving locking under this model is extremely interesting because locking has some particular efficiencies that we’d want to leverage and there’s a way to understand it in terms of this.
I’ll leave this an open question for everybody else – is there a way to reconcile this with Object Orientation? Could we separate perception of an object from its identity enough so that we’d still get the benefits of objects but we don’t get a mess later?
That’s it. Thanks.
[Applause]

질문할 시간이 있나요? 늦은 거 알아요. 좋아요 질문 있으신가요? 질문 있나요?
[청중 1] 지난 20년 동안 모든 함수형 프로그램 언어 컨퍼런스에서 이 강연의 변형된 버전이 발표되어 왔고, 20년 동안 틀렸다고 합니다. 그렇다면 왜 이 생각이 틀릴 것이라고 생각하시나요, 아니면 틀리지 않을 것이라고 생각하시나요?
[리치 히키] 글쎄요, 그 강연이 어떤 내용인지는 모르겠지만 제가 본 바로는 함수형 프로그래밍은 여러 측면에서 시간을 절약하려고만 합니다.
[청중 1] 네.
[리치 히키] 시간을 확보하는 거죠. 이건 그런 게 아닙니다. 이것은 시간이 프로그램에서 여러분이 싸워야 하는 중요한 부분이라는 것입니다.
[청중 1] 알겠습니다.
[리치 히키] 저는 여기서 순전히 기능적인 프로그래밍을 옹호하는 것이 아닙니다. 저는 프로그램이 있다고 말하는 것입니다. 그 상자 중 하나 인 프로그램이 있습니다. 그렇죠? 가치에서 다른 가치로의 전환이죠. 그렇죠? 그런 종류의 프로그램이 계산기입니다. 그렇죠? 대부분의 프로그램은 시간의 진행이라는 문제를 해결해야 합니다. 그리고 그것은 어려운 문제입니다. 그래서 저는 이 문제에서 벗어나려고 하지 않아요. 저는 그것을 향해 걸어가려고 합니다.
[청중 2] 모든 것은 흐른다고 말한 헤라클레이토스가 객체 지향적이라고 말했기 때문에 지금 하고 계신 일은 철학의 초기 역사를 되짚어보는 것이라고 생각합니다. 그리고 나서 플라톤이 그 뒤를 이어서 아니라고 말했죠. 그리고 파르메니데스도 "아니요, 모든 것은 안정적입니다."라고 말했죠. 변화 같은 것은 없다고 말하는 것이 공동체의 기능입니다. 그리고 이 두 가지를 종합하여 하이브리드 모델, 다중 패러다임 모델, 불변성과 변화를 실체라는 개념으로 통합하는 방법을 알아낸 사람이 바로 아리스토텔레스였습니다. 이 책에서 더 많이 다루고 계신 것 같습니다.
[리치 히키] 네. 화이트헤드를 읽어보세요. 그는 정말 그렇게 했어요. 그는 정말로 당신이 말하는 것을 정확히 수행했습니다. 전 그냥 미치지 않고 프로그래밍하려고 노력하는 것뿐이에요.
[웃음]
[리치 히키] 하지만 저는 확실히 그런 개념에서 영감을 받았습니다. 우리가 가진 모델을 고치는 데 정말 중요하다고 생각합니다. 그렇죠?
[조슈아 블로흐] 그렇다면 78년 램포트가 발표한 "분산 시스템에서의 시간, 시계, 이벤트 순서(http://research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf)"라는 논문을 읽어보셨나요?
[리치 히키] 네, 읽어봤어요. 네.
[조슈아 블로흐] 그래서 저는 그것이 정확히 같은 아이디어라고 생각합니다.
[리치 히키] 네, 맞습니다. 제 말은, 멋진 것들이 많이 있다고 생각합니다. 흥미롭다고 생각해요. 전체 웨이브, 지금 웨이브에서 일어나고 있는 일, 이러한 운영상의 변화는 정말 흥미로운 사고 방식이라고 생각합니다. 여기에는 더 많은 것이 있습니다. 예를 들어, 변환의 구성 가능성과 같은 것들은 매우 흥미롭습니다. 하지만 네, 램포트는...
[조슈아 블로흐] 램포트의 접근 방식과 여러분의 접근 방식 사이에 흥미로운 차이점이 하나 있는데, 램포트는 매우 커뮤니케이션 지향적이라는 점입니다. 그는 한 개체가 다른 개체에 무언가를 전달할 때 시간이 발전한다고 말합니다. 반면, 여러분의 프레임워크에서는 한 함수의 출력이 다음 함수의 입력으로 사용될 때 시간이 진행됩니다. 하지만 실제로는 같은 것입니다.
[리치 히키] 맞습니다. 제 생각에는 커뮤니케이션 부분이 까다로워지는 것 같아요. 저는 커뮤니케이션이 필요 없다는 점이 마음에 듭니다. 하지만 시간 구성은 커뮤니케이션과는 다른 것일 수도 있습니다. 그리고 서로 다른지 모르겠어요.
[조슈아 블로흐] 같은 것을 다른 말로 표현하는 거죠.
[리치 히키] 네. 그럴 수도 있죠. 그럴 수도 있습니다.
[청중 4] 네, 그렇죠. 시간의 흐름이 아닌 F 박스에서의 커뮤니케이션.
[리치 히키] 네. 글쎄요, 이것도 일종의 시간의 흐름에 속합니다. 그것은 확실히 - 조정 측면에서 사람들과 소통하는 것입니다. 다음은 당신입니다. 이제 당신, 이제 당신. 네?
[청중 5] 그렇다면 JVM이 STM과 같은 작업을 빠르게 처리하는 데 적합한 기본 요소를 모두 제공한다고 생각하시나요, 아니면 추가 지원이 있었으면 좋겠다고 생각하시나요?
[리치 히키] 지금 아주 만족하고 있습니다.
[청중 5] 알겠습니다.
[리치 히키] 저는...
[청중 5] JVM에 바라는 점이 있다면 무엇인가요?
[리치 히키] 가비지 컬렉션에 대한 압박이 상당할 것입니다. 그러니 가지고 있는 모든 것을 더 빠르게 만들어주세요.
[웃음]
Do we have time for questions? I know we’re running late. Okay. Any questions? Yes?
[Audience member 1] So a variation on this talk has been given at every functional program language conference for the last 20 years and they’ve been wrong for 20 years. So why do you think that this thought will be wrong or not wrong?
[Rich Hickey] Well, I don’t know what those talks were, but from what I’ve seen, functional programming, in many respects, just tries to get time out of the way.
[Audience member 1] Right.
[Rich Hickey] Get time out of it. Well that’s not what this is. This is about time is an important part of programs that you have to contend with.
[Audience member 1] Okay.
[Rich Hickey] I’m not advocating purely functional programming here at all. I’m saying there are programs. There are programs that are one of those boxes. Right? One transition from value to another. Right? That kind of program is a calculator. Right? Most programs have to deal with that; that progression of time. And that’s a hard problem. So I’m not trying to walk away from it. I’m trying to walk towards it.
[Audience member 2] I think what you’re doing here is you’re recapitulating the early history of philosophy because it was Heraclitus that said everything flows so that's your object oriented thing. And then, it was Plato that followed and said no. And Parmenides also had said, “No, everything’s stable.” And that’s the function of community, saying there’s no such thing as change. And then, it was Aristotle that synthesized the two and figured out how to get the hybrid model, the multi-paradigm model, and integrated change with invariability with the concept of a substance. And that’s what I see you dealing with more in this.
[Rich Hickey] Yeah. Well, I mean, read Whitehead. I mean, he really did that. He really did exactly what you’re saying. I’m just trying to program without going crazy.
[Laughter]
[Rich Hickey] But I am inspired definitely by that, by those notions. That I think they’re really important for fixing the model we have. Yes?
[Joshua Bloch] So, have you read a paper called “Time, Clocks, and the Ordering of Events in a Distributed System (opens new window)” by Lamport in ’78?
[Rich Hickey] Yes, I have. Yes.
[Joshua Bloch] So, I think that that’s exactly the same set of ideas.
[Rich Hickey] Yes, it is. I mean, I think there’s lots of cool things. I think that’s interesting. I think the whole wave, what’s happening in wave right now, those operational transforms, are a really interesting way to think about this. I mean, there’s a lot more to this. For instance, the composability of transformations and things like that that are very interesting. But yes, Lamport is...
[Joshua Bloch] There’s one fascinating difference between Lamport’s treatment of it and yours, is Lamport’s is very much communication-oriented. He says time advances when one entity communicates something to another. Whereas in your framework, time advances when the outputs of one function are used as the inputs to the next function. But, it’s really the same thing.
[Rich Hickey] It is. I mean, the communications part gets tricky, I think. I like the fact that this is sort of communication-free. But maybe time constructs are different from communication. And I don’t know if they are different.
[Joshua Bloch] Different words for the same thing.
[Rich Hickey] Yes. They may be. They may be.
[Audience member 4] Yeah, yeah. Communications in your F box and not in the flow of time.
[Rich Hickey] Yeah. Well, this is sort of in the flow of time too. That is definitely – in the coordination aspect, that’s communicating to people. You next. Now you, now you. Yes?
[Audience member 5] So, have you found that the JVM provides all the right primitives to make things like STM fast or do you wish that there was additional support that you could take advantage of?
[Rich Hickey] I’m having a good time right now.
[Audience member 5] Okay.
[Rich Hickey] I don’t…
[Audience member 5] What would you ask for out of JVM?
[Rich Hickey] The garbage collection pressure of this is going to be significant. So just keep making everything you have faster.
[Laughter]
[청중 5] 그럴 수 있어요.
[청중 6] [FP 01:08:29] 사람들에 대해 좀 가혹하게 말씀하셨어요. 함수형 반응형 프로그래밍은 [불분명 01:08:33]은 어떻습니까?
[리치 히키] 그건 척 시간입니다.
[청중 6] 차이점이 무엇인가요?
[리치 히키] 함수형 리액티브 프로그래밍을 특징짓고 싶지는 않습니다. 저는 방송 자동화 시스템 분야에서 오랫동안 일했습니다. 그 책을 읽었습니다. 그 책과 제가 실제로 해야 하는 일 사이에는 전혀 상관관계가 없다고 생각했습니다. 그렇죠? 하지만 시간을 조작하여 함수에 대한 인수로 바꾸고 이제 다시 펀팅을하고 있습니다. 척하는 거죠. 그렇지? 그건 시간이 아니야. 그건 또 시간이지요. 그리고 그것을 외부 세계와 연결하자마자 그것이 사실임을 알게 될 것입니다.
[청중 7] 이벤트 스트림이 있고 그 안에 있는 모든 것이 불변의 이벤트 스트림에서 작동할 수 있는 최신 이벤트 처리 언어를 살펴본 적이 있나요? 이벤트를 테이블이나 집계에 저장할 수는 있지만 모든 데이터는 다음 흐름으로 변경되지 않습니다.
[리치 히키] 모든 데이터가 변경되지 않는다면 올바른 방향으로 가고 있다고 생각합니다. 여기서 중요한 점은 변경 가능한 객체 같은 것은 없다는 것입니다. 이 사실을 정말로 믿을 수 있다면 더 나은 시스템을 구축할 수 있습니다. 다시 말하지만 동의하지 않는 것은 아닙니다. 물론 저는 함수형 프로그래밍을 좋아하죠? 하지만 실제 사람들이 가지고 있다고 생각하는 다른 문제에 대해서는 이야기하지 않는 것 같아요.
다른 질문은 없나요? 감사합니다!
[박수]
[Audience member 5] I can do that.
[Audience member 6] You were a little bit harsh I thought on the [FP 01:08:29] people. What about Functional Reactive Programming is [Unclear 01:08:33]?
[Rich Hickey] That’s pretend time.
[Audience member 6] What’s the difference?
[Rich Hickey] I don’t want to characterize Functional Reactive Programming. I will say this – I worked in broadcast automation systems for a long time. I read that book. I saw absolutely no correlation between that and what I actually had to do in the real world at all. Right? But fabricating time and turning it into an argument to functions, now you’re punting again. You’re pretending. Right? That’s not time. That’s again punting. And as soon as you connect it to the outside world, you’ll see that’s the case.
[Audience member 7] Have you looked to any modern event processing languages that have streams of events and everything in it can operate on the immutable stream of events? You can store an event into tables or aggregation things, but all your data is immutable as the next flow.
[Rich Hickey] As long as all your data is immutable, I think you’re on the right track. I think the key takeaway here is there’s no such thing as a mutable object. If you can really believe that, you can build better systems. Which, again, is not to disagree. I mean, obviously, I like functional programming, right? But I don’t see them talking about other problems that I think real people have.
Anything else? Thanks!
[Applause]